Introduction
When we start designing a database, we all think about normal forms, as well as denormalization techniques in case of optimizing performance. To protect information and reinforce the integrity of database, we apply constraints and business rules. The question is, isn't it enough for the database to be safe?
Following up on normal forms and strict constraints does not go far enough. Assuming that you get the design work done perfectly, everything appears to make sense. But one day you spot a design flaw in an up-and-running database. Moreover, this flaw doesn't come from complying with normal forms wrongly. It is just going to be a matter of logical design. “Circular Reference” is such a flaw.
In this article, I'll work through using some real-work examples to demonstrate the impact of “Circular Reference” on data consistency.
Example 1
This example is all about task management. We are first looking at four tables “Project”, “Team”, “Task” and “ProjectAssignment” that make up a circulation. In theory, looks like it’s fine since it complies with normal forms. On the logical side, it’s not fine since this design hides its potential inconsistency flaw.
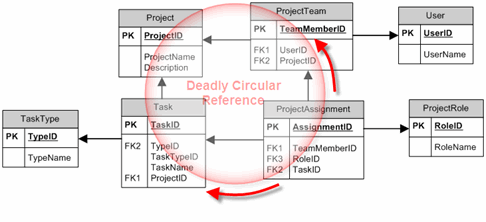
In this figure, circular reference appears. Data is potentially at risk because if we really look deeper at the business relationship between entities “ProjectAssignment” and “Project”, there are two routes for data to traffic from ProjectAssignment to Project:
ProjectAssignment=> ProjectTeam => Project ProjectAssignment=> Task => Project
Obviously, the result of query by either ways could be different, leading to inconsistency in data flows.
You can ask yourself a question: “So what’s going on with this problem? My system still runs fine without being affected by this problem. I don't care much about this at all.”
Maybe you're true. You might not see the threat behind the scenes. But it certainly makes you worry or brings uncertainty for your business. Some day, data inconsistency occurs. It really poses a potential nightmare if you have to change database design once the system goes into production. Let us assume that the following requirement is added up:
“List out all of the projects for which there is a team member with role ’Supervisor’ ”
With this requirement in mind, if we are not careful enough in writing code to impose strict validation on working with data, it might end up with inconsistent data between entities “ProjectTeam” and “Task”, the consequence being that query result might be different.
Solutions: There are some sorts of solutions subject to business requirements. During preliminary design, we're better off looking out for circular reference which makes up more than four tables.
In the above example, we can propose 2 solutions:
Solution 1: Drop table “ProjectTeam” if this table is not necessary. This solution is helpful only if the requirement implies that each team member must belong to at least a specific task.

Solution 2: If the requirement implies that some members can join the project beforehand, no need to belong to any specific task until they are assigned, then you'll need to weigh the pros and cons about all sides of this issue. If you're confident that your code is solid and there is surely not any anomaly in database, then you might not need to make changes. On the contrary, if your code is not solid enough, and accidental altering is likely to occur such as a concurrency error, a transmission error, hard disk crash, or missing design scenarios, then data is not sufficiently reliable. Let’s have look at the scenario: “Move a certain member from one project to another”. Obviously, this is potentially dangerous if this team member has already been assigned with some tasks, unless strict rules/constraints have been imposed on. You can easily figure out why inconsistent data comes up at this point. Certainly, the more strict rules/constraints you come up with, the more likely it is that your database is safe. However, finding all strict rules/constraints at the first time is never easy. Moreover, too many constraints and rules can incur processing overhead and hamper creative work.
Choosing the most suitable solution is up to you. Because you understand requirements better than others, only you know what is truly best for your database. In this case, I just want to prove that defining so many constraints is not necessarily the best solution while we can still get out of circular reference. Hence, some changes are necessary for database design just to be on the safe side.
The second solution is a bit tricky. We can still drop “ProjectTeam”. However, we have to come up with alternative rules. The following rule could be useful: When a new project has been created, we always add a “special task” in “Task” table, but link with Project through ProjectID. There are lots of solutions as to mark a record as special one. In this case, setting value of “TaskType” as “Null” is one solution. This special task acts as a “virtual task”. It belongs to every team member. Now we can add a new record for a certain member in “ProjectAssignment” that links tables “User”and “Task” (through virtual task). Obviously, this member doesn't need to belong to any specific task, but certainly belong to a project.
In this modified design, there is no more than one route for data to traffic from one entity to another. Moreover, we are now removing the unnecessary Associate Table “ProjectTeam”, hence removing redundant data. This solution also helps explain the importance of “special record”. The downsize is that using “special record” does come at a cost. Developers make it easy to neglect it, especially in maintenance phase. It’s a trade off.
Example 2
The flaw found in the first example is not too dangerous and the changes in database design might not need. But the flaw found in this example tells us that the changes are needed. Let’s have look at the requirements:
- Each customer can purchase multiple products at the same time, as well as same products at different periods of times. All of these purchasing transactions store in table “
Purchase”. - Reseller can earn commission for each sold product for one customer. All of commission data store in table “
Commission”.
As mentioned in the first example, data inconsistency might occur when user tries to insert data directly into the database. In this example, even inputting data in UI page might as well cause problems. The first example is more of an inconsistency than a genuine threat. Meanwhile, circular reference in this example can be potentially hazardous.
Look at the following design. Now inconsistent data is created by the end user itself. The problem lies in two highlighted rows which share the same product (Bamboo Flooring). In addition, all of these transactions belong to same customer (Pham Dinh Truong).
Now there is a real bottleneck in dealing with “Commission Amount”. The same customer purchases the same product, but on different dates and with different quantities for each purchase date, hence it can have different commission amounts. Once Commission Amount has been inputted (auto or manual) for each above highlighting row, after we save it and reload grid, Commission Amount is always the same for both highlighting rows. The query looks like:
SELECT CommissionAmount FROM Commission
WHERE CustomerID = @CustomerID AND ProductID = @ProductID
This query returns two values corresponding to two purchase transactions (two rows, respectively), but which value of CommissionAmount maps with which transaction? You can guess easily that the first returned value will be filled for both transactions. Now you know what’s happening.
Obviously, this bug is never easy to detect. The consequence being that it can distort our business data.
Original Cause
Let’s try to figure out what’s going on behind this circular reference. Unlike the first example, this example always ensures that there is no more than one way for data to traffic between two entities. Let’s trace back to the above UI portion, it’s quite clearly that there exists hidden “business relationship” between Purchase and Commission. However, this relationship doesn't reflect in database design.
In the end, we found the original cause.The biggest mistake is that the hidden relationship has been missed. Hence the database developer unintentionally creates a circular reference that leads to inconsistent data.
Solution
So what is the solution for this problem?
Changing database design is an uncontrolled damage, especially when we already get the system up and running. If we change the design after the product goes live, we must pay the price. Sooner or later, circular reference causes trouble, bringing uncertainty for end users to work with the system. Hence we need a good trained eye so as to detect the problem and break it through as soon as we can.
Look at the following modified database design, the relationship in pairs of tables Customer-Commission and Product-Commission has broken through. Commission table now links to Purchase table.
Obviously, the modified design is better than the original one.
Conclusion
In order to remove the uncertainty out of your mind about database design, especially concerning data inconsistency, the following advice might be helpful:
- Circular reference increases the likelihood of errors and inconsistencies. Keep number of circular references as low as possible to minimize the impact on data consistency and correctness.
- It’s important that circular reference be detected and prevented as early as the implementation phase before the situation turns ugly.
- Be sure that there is no more than one route for data to traffic from one entity to another.
- Using “special records” in some circumstances could be helpful for database design.
Detecting design flaw is never easy. We are not sure whether the anomalies are present in up-and-running database. It requires a good trained eye to find the culprit in database design. Hopefully, this article could help you to keep a trained eye on database design. Practice makes perfect.
History
- Version 1.0 (1 August, 2009) - Initial release

