Introduction
What follows is my response to the CodeProject contest challenge posted at Code Lean and Mean. The object of the challenge is to present a solution that calculates and displays the differences between two text files as quickly as possible using the least amount of memory as possible. This solution is being submitted for category #2 (.NET/any language).
Background
I originally thought this project would be very straightforward, but the more I read the rules and parameters of the proposed problem, the more I realized that a solution needed to be smart enough to detect changes in either words or whole lines of text, because a byte-by-byte comparison could easily fall into a number of pitfalls.
Byte-by-Byte Comparisons
- Generally don't work forward the same way as backwards, so if you compare file A to file B, you will not get the same results as if you compare file B to file A.
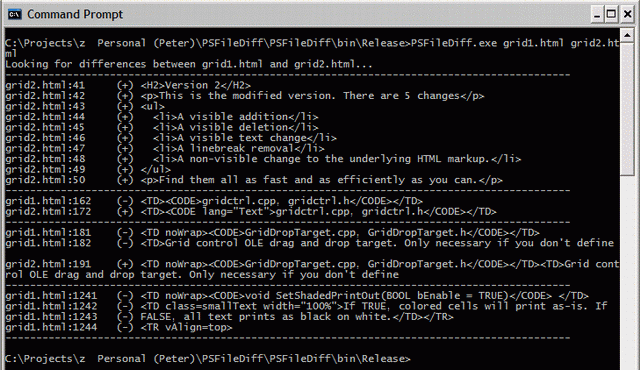
- Suffer from issues relating to treating individual bytes as patterns instead of what humans would perceive as patterns. For example, a byte-by-byte comparison will tell you that "this is some text" and "this is even more text" has several changes where a word or line-based comparison would easily pick out the one change ("some" was replaced with "even more").
- Are simply difficult for a human to read the output for since no grouping was performed.
Since the aim of this project is to use as little memory as possible, reading in the entire contents of both files to perform very quick in-memory analysis was out of the question. Also, since I decided to do a line-by-line analysis of the input files (the problem did say they'd be text files), I would need to scan ahead and then rewind the file pointers for the files when finding out when the files synchronized again after finding discrepancies.
This lead to a problem...
The Problem With StreamReader.ReadLine
I originally used StreamReader's ReadLine method to read lines of text from the input files. The problem quickly became evident -- the method doesn't immediately update the FileStream's Position property that indicates where it is in the file due to caching. Retaining and resetting the file pointer was out of the question if I were going to continue to use the StreamReader, so I ultimately decided to ditch it in favor of this replacement:
static string ReadLine(FileStream file, byte[] buffer)
{
Encoding en = new ASCIIEncoding();
long lPreserveFilePos = file.Position;
long lByteStop = 0;
int lOffset = 0;
file.Read(buffer, 0, iBufferSize);
if (buffer[0] == 10) lOffset = 1;
for (; lByteStop < iBufferSize; lByteStop++)
if (buffer[lByteStop] == 13)
break;
if (lByteStop == lOffset) return string.Empty;
if (lByteStop < iBufferSize)
{
file.Position = lPreserveFilePos + lByteStop + 1 + lOffset;
return en.GetString(buffer, (int)lOffset, (int)(lByteStop - lOffset));
}
string s = en.GetString(buffer, 0, iBufferSize);
s += Program.ReadLine(file, buffer);
return s;
}
[NOTE: code comments have been removed for the sake of brevity. For full comments, please download my source code at the top of the article.]
Here, I simply read byte chunks from the FileStream until I'm satisfied by a newline as a line ending. Any linefeed characters are discarded by intention; this way DOS and UNIX style text files can be compared directly. This function does require, however, that the files be in simple ASCII format (no Unicode support).
Using the Code
The crux of the code is a simple loop through all of the data in file A, trying to find where the data de-synchronizes and re-synchronizes against file B:
while (fileA.Position < fileA.Length)
{
sA = Program.ReadLine(fileA, x);
iLineFileA++;
if (fileB.Position >= fileB.Length)
{
Console.WriteLine(args[0] + ":" + iLineFileA.ToString() +
" through end of file (does not exist in " + args[1] + ")");
break;
}
if (bWantNextB)
{
sB = Program.ReadLine(fileB, x);
iLineFileB++;
}
if (sA != sB)
{
if (-1 == (iDiff = (Program.DiffDistance(fileA, sB, 10,
x) == -1) ? Program.DiffDistance(args[1] + ":" +
iLineFileB.ToString().PadRight(6) + " (+) " + sB, args[1] + ":",
"+", fileB, sA, iLineFileB, out iLineFileB, x) : -1))
{
if (-1 == (iDiff = Program.DiffDistance(args[0] + ":" +
iLineFileA.ToString().PadRight(6) + " (-) " + sA, args[0] +
":", "-", fileA, sB, iLineFileA, out iLineFileA, x)))
{
Console.WriteLine(args[0] + ":" + iLineFileA.ToString().PadRight(6) +
" (-) " + sA);
bWantNextB = false;
continue;
}
}
Console.WriteLine("------------------------------------------------------------");
}
bWantNextB = true;
}
if (fileB.Position < fileB.Length)
Console.WriteLine(args[1] + ":" + iLineFileB.ToString() +
" through end of file (does not exist in " + args[0] + ")");
[NOTE: code comments have been removed for the sake of brevity. For full comments, please download my source code at the top of the article.]
Most of the code here is simply displaying changes to the end user, leaning heavily on the overloaded DiffDistance function to do the dirty work of looking for when and how far away a discrepancy is rectified in a target file. There is also some extra logic here to do a reverse comparison on file B against file A so that additions to file B aren't overlooked.
I wrote DiffDistance in two ways. The first simply goes through a file looking for the first occurance of a line of text and returns a number indicating how many lines it counted during its search. It will return -1 if the search never completed. I also added a parameters that limits how many lines its allowed to search. I use this version of DiffDistance to help minimize the amount of time required to detect changes between the file (when a line is removed and replaced with another line) by scanning ahead only a few lines in the reverse direction before proceeding with a full scan in each direction. It's a simple optimization, but it helps under many circumstances.
static int DiffDistance(FileStream file, string sLine, int iMax)
{
long lPreserveFilePos = file.Position;
int iDiff;
for (iDiff = 0; (iDiff <= iMax) && (file.Position < file.Length); iDiff++)
if (ReadLine(file) == sLine)
break;
if ((file.Position >= file.Length) || (iDiff > iMax))
iDiff = -1;
file.Position = lPreserveFilePos;
return iDiff;
}
[NOTE: code comments have been removed for the sake of brevity. For full comments, please download my source code at the top of the article.]
The other version of DiffDistance actually does a full scan and displays text for us to send to the user. To avoid creating a large string buffer (thus using possibly lots of memory), the lines are read twice, which increases processing time by a small factor.
Other than the formatting, this version does essentially the same as the other:
static int DiffDistance(string sOriginalOutput, string sPrepend, string sType,
FileStream file, string sLine, int iLineCount, out int iNewLineCount, byte[] buffer)
{
long lPreserveFilePos = file.Position;
int iDiff;
string sRead;
iNewLineCount = iLineCount;
for (iDiff = 0; file.Position < file.Length; iDiff++)
{
iNewLineCount++;
if (sLine == (sRead = Program.ReadLine(file, buffer))) break;
}
if (file.Position < file.Length)
{
file.Position = lPreserveFilePos;
Console.WriteLine(sOriginalOutput);
for (iDiff = 0; file.Position < file.Length; iDiff++)
{
if (sLine == (sRead = Program.ReadLine(file, buffer))) break;
Console.WriteLine(sPrepend + (iLineCount + iDiff +
1).ToString().PadRight(6) + " (" + sType + ") " + sRead);
}
return iDiff;
}
if (file.Position >= file.Length)
{
iDiff = -1;
file.Position = lPreserveFilePos;
iNewLineCount = iLineCount;
}
return iDiff;
}
[NOTE: code comments have been removed for the sake of brevity. For full comments, please download my source code at the top of the article.]
Points of Interest
I have always been a big fan of the ? operator, which acts like a shortened if statement. For example, these two are functionally equivelant:
iResult = (iValue > 10) ? 10 : iValue;
.. versus ..
if (iValue > 10)
iResult = 10;
else
iResult = iValue;
Results
Running this on my Windows 7 64-bit machine at home yields about 80ms of execution time at 900 KB of combined memory use, but my development machine at the office yields 91ms at 3.5 MB of combined memory use (which is Windows XP 32-bit); I found the differences in the operating systems and .Net framework very interesting. The executable file size is 8k.
Your mileage may vary.
There could stand to be some further optimizations, I'm sure, as it is a work in progress, but I want to keep the solution as simple as possible (i.e.: the simplest solution that can possibly work is often the best). If memory were not an issue for the competition, I could easily reduce the redundant reads. Also, with a bit of extra logic, Unicode support wouldn't be too far behind either.
History
v1.00 -- Aug 20, 2009 -- initial release for public scrutiny.
v1.01 -- Aug 21, 2009 -- fixed some logic that was causing the display of line numbers to be inaccurate.
v1.02 -- Aug 26, 2009 -- rewrote ReadLine() to read in full chunks of data at a time, instead of one byte at a time. This improved the processing time by leaps and bounds. I am also no longer creating and using a StringBuilder here.

