Contents
Introduction
This article presents an application that calculates and displays the differences between two text files. It is written to meet the challenge in the Code Lean and Mean[^] programming competition of Code Project[^]. This entry is for the .NET (C#) category. When FIFFConsole is run with the test files included in the challenge, it completes in 109 ms (or less) and takes about 952 kB of memory on AMD 1.6 GHZ laptop with 2GB RAM. I claim that the algorithm that it implements, for most practical purposes, runs in linear time and space, O(m), where m is the number of differences between the two files.
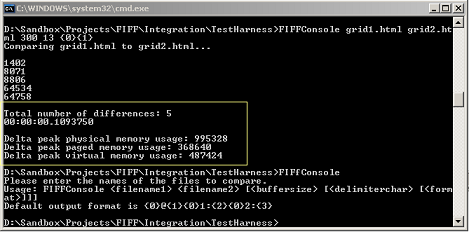
Sample call: FIFFConsole grid1.html grid2.html 250 13
After the original publication, a request was made to extend the functionality to allow the comparison of files in a non-sequential order. For example, if the first file contains two lines and the second file contains the same two lines but in reverse order, then no differences should be reported between the files. In other words, if a token form one file exists somewhere in the body of the other file, then that token is excluded from any differences reported between the files. This feature is added in version 0.2 of the application as a scope change where the original performance metrics are unchanged or slightly improved.

Sample call: FIFFConsole grid1.html grid2.html 13 true 250
The presentation follows the mini software development life cycle (SDLC) that led to the proposed solution.
Analysis
Any successful software endeavor has a set of well understood requirements. IBM has an excellent resource on Requirements: An introduction by Scott McEwen[^].
In our case, the problem domain is defined by the following needs:
- Calculate and display the differences between two text files
- Version 0.2: Provide an option to compare files in a non-sequential order
- Provide small footprint and high performance
- Report execution time
- Report memory usage
- Provide value to a wide variety of developers
These needs lead us to the following features:
- Provide mechanism for file name input
- Provide support for various text file formats
- Devise an algorithm that will require least amount of file reads and memory storage
- version 0.2: Support partial and full file reads
- Allow room for performance tuning
- Allow room for future optimizations
- Measure execution time
- Measure memory usage
- Allow basic output re-formatting
The following non-features have not been considered a priority and may have been omitted completely:
- Security and access layers
- Character encoding concerns
- Thread-safety
- Asynchronous calls
- Exception handling
- Graphical user interface
These features and non-features translate to the following requirements:
- Use .NET C# Console Application with two required arguments that specify the file names
- Use up to 3 additional arguments that specify the buffer size, the token delimiter, and the output format
- Version 0.2: Use additional argument to specify whether the comparison is ordered
- Version 0.2: Use internal flag to specify whether the comparison is case sensitive
- Store only hash codes and file positions to preserve space
- Store only hash codes that differ and clear them as soon as the difference is resolved
- Scan files at most twice
- Scan ahead no more than is necessary and sufficient
- version 0.2: Provide an option to optimize scanning for ordered comparisons
- Use efficient hash code generating function as provided by the .NET framework [^]
- Use interfaces to allow for different implementation of the file read and temporary storage objects
- Use
System.IO.FileStream [^] for the file read interface implementation because it is sufficiently optimized - Use
System.Collections.Generic.List(T) [^] for the temporary storage interface implementation because it is sufficiently optimized - Use generic class [^] for the algorithm class to supply it with the interface implementation information
- Use
System.DateTime.Now.Ticks [^] to record execution time
- Version 0.2: Use
System.Diagnostics.Stopwatch [^] to accurately measure elapsed time
- Use
System.Diagnostics.Process [^] to record memory usage - Use
System.Text.UTF8Encoding [^] to support both Unicode and ASCII text, UTF-8[^]
Algorithm
In the heart of the solution is the algorithm used to calculate the text file differences. It reads chunks of data from each file until it detects a difference. Then it re-reads the same chunk, token by token. The definition of token is flexible; in some configurations, it may be a word, in others it may be a line, etc. Once the first token difference is reached, the tokens' hash codes get stored in temporary storage. The temporary storage can be an array but it can also be a hash table, B tree, etc. Reading from the files continues in this manner until a token from one file is found hashed in the other's file temporary storage. At this point, the difference is finalized, the temporary storage is cleared and we continue by reading chunks of data. This algorithm is symmetric.
- Version 0.2: While this principle is preserved, the algorithm is extended to allow for the files to be fully read and their tokens stored prior to processing in the case of not ordered or not optimized comparisons.
Alternatively, the Longest common subsequence problem (LCS)[^] provides a proven method for file comparisons. However, in my opinion, a variation of it can be used here because we deal with large files with small differences that are at a coarser granularity (line level).
- Version 0.2: The LCS method cannot be applied to not ordered comparisons at all.
Here is the pseudo-code:
open file A, B
if (hash A != hash B)
{
while not (EOF A or B)
{
if (read buffer A != read buffer B)
{
read and store token A, B (if optimized, read one token only)
while (store A or B is not empty)
{
matched = (token A or B exists in store B or A respectfully)
if (ordered and matched and (index token A in store B +
index token B in store A > 0)) or (not ordered and not matched)
{
report and clear store A, B to index token B, A in store A, B
}
if (ordered and matched and (index token A in store B =
index token B in store A)) or (not ordered and matched)
{
clear store A, B at index token B, A in store A, B
}
if (ordered and optimized)
{
if not matched
{
read and store token A, B (if optimized, read one token only)
}
else
{
clear store A, B
}
}
if (store A or B is empty)
{
report and clear store A, B
}
get next token A, B at index = (matched || not ordered) ? 0 : Min(
index token A, B in store B, A) + 1
}
}
}
}
close file A, B
With limited knowledge of the Big-O[^] notation and computer science complex theory, I am unable to provide upper bounds for the time and space usage of the algorithm. However, here are my thoughts. The space consumption is in the temporary storage of hash codes and the time consumption is in searching it. Let n be the longest single difference between the two files as measured by the number of tokens in that difference and let m be the total number of differences. Then the algorithm runs in linear space, O(n), and completes in polynomial time, O(m*(1 + 2 + ... + n)) = O(m*n^2).
The worst case scenario is when the two files are completely different. Then, provided that we tokenize by line, n = Min(k, l) where k is the number of lines in the first file and l is the number of lines in the second file, and m = 1. Thus, the algorithm finishes in O(n^2) time. If, for example, we used sorted list rather than an array, we could run a binary search on it in O(log n) time, but we would have to include O(n) time for insertion into the list. Since the frequencies of insertions and searches are the same, there is no gain in that approach.
The best case scenario is when the two files are the same, n = 0, m = 0. Then the algorithm finishes in constant time and space, O(1).
For the purposes of the competition, as we compare large files with small changes, the max length of a difference between two such files is independent of their length. In other words, it is a constant. Therefore, the algorithm runs in linear space and time, O(m), n~1!
- Version 0.2: In the case of not ordered or not optimized comparisons, the two files are read into memory prior to processing. Thus, provided we tokenize by line and p = Max(k, l) where k is the number of lines in the first file and l is the number of lines in the second file, the algorithm runs in polynomial space O(p) and time O(p + ... + 2 + 1).
Note: The implementation is not suitable for comparing large files with a lot of changes. For instance, while 3MB (or any other size) files with 3 different tokens (changes) can be compared in less than 100ms, 3MB with 15000 different tokens (changes) takes up to 2 minutes.
Design
Activity Diagram
The activity diagram below is just a visual representation of the principle behind the algorithm mentioned above. It is straightforward in terms of actions and decision points. The activity diagram helps identify the objects and operations that will be needed during implementation.
Class Diagram
The class diagram below describes the objects that are used to implement the algorithm. Notice that since the FIFFBroker does not care about the source of the data and the kind of temporary storage that it is going to use as long as certain operations are available to it, IFIFFStream and IFIFFData are defined as interfaces. This provides easy opportunity for future optimizations. The FIFFTuple stored temporary while accumulating a difference is of two integer values in order to save space. The output formatting, reading buffer, and token delimiter are defined independently to allow for performance tuning and basic customizations.
Sequence Diagram
The sequence diagram mimics the activity diagram but it helps ensure that all the objects and operations needed to complete the task at hand are identified correctly. Redundant objects and/or operations can be exposed, too.
Implementation
For more details, please have a look at the uploaded source files.
- Calculate and display the differences between two text files:
try
{
FIFFBroker<FIFFStream, FIFFData> broker = new FIFFBroker<FIFFStream, FIFFData>();
Console.Write(broker.Compare(args[0], args[1]));
}
catch (Exception e)
{
Console.WriteLine("Exception: " + e.Message);
}
- Measure and report execution time:
Stopwatch stopWatch = new Stopwatch();
stopWatch.Start();
stopWatch.Stop();
Console.WriteLine(stopWatch.Elapsed);
DateTime.Now.Ticks - startTime.Ticks));
- Measure and report memory usage:
Process FIFFProcess = Process.GetCurrentProcess();
long startPeakWorkingSet64 = FIFFProcess.PeakWorkingSet64;
FIFFProcess.Refresh();
Console.WriteLine("Delta peak physical memory usage: {0}",
FIFFProcess.PeakWorkingSet64 - startPeakWorkingSet64);
See also: GC.Collect Method[^].
Console.WriteLine("Memory used before collection: {0}", GC.GetTotalMemory(false));
GC.Collect();
Console.WriteLine("Memory used after full collection: {0}",
GC.GetTotalMemory(true));
Integration
To run FIFFConsole version 0.2, open a command prompt, browse to the directory that contains the executable, and invoke it with the following arguments:
- <filename1> - The path and name of the first text file, required, default: N/A
- <filename2> - The path and name of the second text file, required, default: N/A
- <delimiterchar> - The byte representation of the token delimiter, optional, default: 32 (i.e. whitespace)
- <ordered> - The flag indicating whether to perform non-sequential comparison, optional, default: false
- <buffer> - The size of the chunks read while scanning for differences, optional, default: 4096 (i.e. 4K)
- <format> - The output format, optional, default: {0}1:{1}{2}{0}2:{3}{4}{0} (where {0} = new line, {1} = the position the difference starts in file 1, {2} = the text that is present in file 1 at this position, {3} = the position the difference starts in file 2, {4} = the text that is present in file 2 at this position)
If you want to automate the process and/or compare multiple files at once, you can write a script to select these files, invoke FIFFConsole, and store the result as needed. Here is one such script that given a file in a modified folder, finds the corresponding file (with the same filename) in an original folder, and stores the file difference in another folder. This script is written by Natasha Guigova. A version of it has been used for quality assurance (QA) regression testing.
strBaseFolder = "C:\Sandbox\Test\Original"
strCurrentFolder = "C:\Sandbox\Test\Modified"
strResultFolder = "C:\Sandbox\Test"
strExeFile = "%comspec% /c C:\Sandbox\Test\FIFFConsole.exe"
Set objShell = CreateObject("WScript.Shell")
Set objFSO = CreateObject("Scripting.FileSystemObject")
Call runCompare
Function runCompare
On Error Resume Next
If objFSO.FolderExists(strResultFolder) = False Then
objFSO.CreateFolder(strResultFolder)
End If
Set objCurrentFolder = objFSO.GetFolder(strCurrentFolder)
Set colFiles = objCurrentFolder.Files
For Each objFile in colFiles
strFileBase = strBaseFolder & "\" & objFile.Name
strFileCurrent = strCurrentFolder & "\" & objFile.Name
strFileResult = strResultFolder & "\" & Replace(objFile.Name,
".html" , ".txt")
strCMD = strExeFile & " " & strFileBase & " " & strFileCurrent &
" 13 true 250 > " & strFileResult
objShell.Run strCmd,0,TRUE
Next
End Function
If Err = 0 Then
MsgBox "Task Completed"
Else
MsgBox "Error Source: " & Err.Source & vbCrLf & _
" Error Description: " & Err.Description
End If
Set objShell = Nothing
Set objFSO = Nothing
Points Of Interest
The buffer argument makes a difference in the performance but not in the memory usage. It allows for chunks of data to be pre-scanned for differences and for the algorithm to be applied only to those chunks that differ rather than to the entire content of the files. I expect that the more differences there are, the smaller the buffer has to be. If it is bigger than the size of the file, it has no effect. For example, when the FIFFConsole version 0.1 is run for the test files included in the challenge on AMD 1.6 GHZ laptop with 2GB RAM with buffer size of:
- 4096 - It takes close to 300 ms to complete
- 1000 - It takes close to 150 ms to complete
- 500 - It takes close to 125 ms to complete
- 250 - It takes close to 109 ms to complete
- 100 - It takes close to 140 ms to complete
- 10 - It takes close to 500 ms to complete
- Version 0.2: The
buffer argument makes sense only in the context of ordered comparisons with optimized flag set to true. In all other cases, the files are read in completely and the algorithm is applied to the entire content of the files.
- Version 0.2: The
optimized flag applies to ordered comparisons and indicates whether the files are read in chunks or in their entirety. In the former case, the algorithm is applied only to partial (necessary and sufficient) data and the process takes significantly less time. The resulting differences are equivalent even though they may have slightly varying representations. For example, a deletion maybe reported as edition followed by deletion when there is a repeating token present in both files such as <TR vAlign=top> as in the test files.
The delimiterchar argument is a stub at tuning. It is used to define tokens. Tokens are used to calculate difference. When the delimiterchar is whitespace, we deal with words. The caveat being that it does not deal well with punctuation. 'Text' and 'Text,' will be considered different tokens. Using whitespace as a token delimiter is not recommended in the case of HTML or XML files because '<h3>Revision </h3> ' will be tokenized as '<h3>Revision' and '</h3>'. Despite the char associated with the delimiterchar, tokens are never bigger than a line. It is possible to define smarter logic for tokenizing the text but it is outside of the scope of this challenge.
Based on the output, the file contents can be restored. The output includes information for the position in file 1, the diff in file 1, and the diff in file 2. Thus,
- Addition (+) is equivalent to diff in file 1 being empty
- Deletion (-) is equivalent to diff in file 2 being empty
- Edition (.) is equivalent to both diff in file 1 and diff in file 2 present
Test Cases
Consider the following text examples and how they compare:
- This is a text
- This is a text simple
- This is a simple text
- This is a simple text, right?
- This is a complex text
- This is a complex convoluted text.
- This is convoluted text that my sister wrote.
- This text is in red
- I like ice-cream! :D
Conclusion
There are several easy ways in which the proposed implementation can be extended:
- By generating an event upon difference finalization in order to notify any subscribers
- By realizing the
IFIFFStream interface for objects other than files - By implementing a delimiter lookup table in order to support a more flexible set of tokens
- By working only with byte arrays (rather than
strings) in order to support binary files and other generic input
The algorithm and the implementation described in this article are designed to be lean, mean, scalable, and extensible. I will be glad to get your comments.
Resources
Revision History
- 2011-07-02: Applied bug fixes
- 2011-07-02: Added performance clarification (thanks to Qwertie)
- 2011-04-25: Modified size of some of the images in the article
- 2010-01-13: Added VB script for process automation (thanks to Natasha Guigova)
- 2010-01-10: Added version 0.2 with support for non-sequential file comparison
- 2009-08-27: Added to the notes in the Algorithm section claiming linear space and time execution
- 2009-08-27: Added test machine specs
- 2009-08-27: Added reference to
GC.Collect() (thanks to Luc Pattyn) - 2009-08-24: Added a conclusion
- 2009-08-24: Added time and space upper bound estimation
- 2009-08-22: Published on CodeProject

