Introduction
We received a request to help a large enterprise who is reimagining their digital strategy and business value chain to reformat the entire business by introducing an enterprise grade information system.
In simple terms, it was a ground up development of the complete solution stack by leveraging the existing solution base. we were required to provide a solution that performed all the main business operations linked with its law, rules and administrative directives. It needed us to support the following main requirements.
- Support an architecture that dealt with a large development team from multiple locations
- Support continuous delivery and integration
- Have built-in features to easily scale up and scale out based on demand
- Have redundant servers to reduce the impact of a server failure
- Have the flexibility to change their core business processes over time
- Support integration with off-the-shelf products
- Integrate all the sub systems with a main IS system, where every activity is monitored and controlled
- Support access via multiple devices
- For security and confidentiality reasons, refrain from using an external cloud hosting solution
- Support technology diversity
Monolithic Systems Design Approach
In most systems implementations, the immediate need of the business is addressed with a quick, isolated, low cost solution that enables them to stay ahead of the disruptors and competition. This proved to be a bad idea for this customer for many reasons, even though it appeared to be a simple, user-friendly solution. This type of isolated solutioning approach eventually creates a set of entangled monolithic applications that share business capabilities across each other making them heavily dependent, and harder to manage, scale or change.
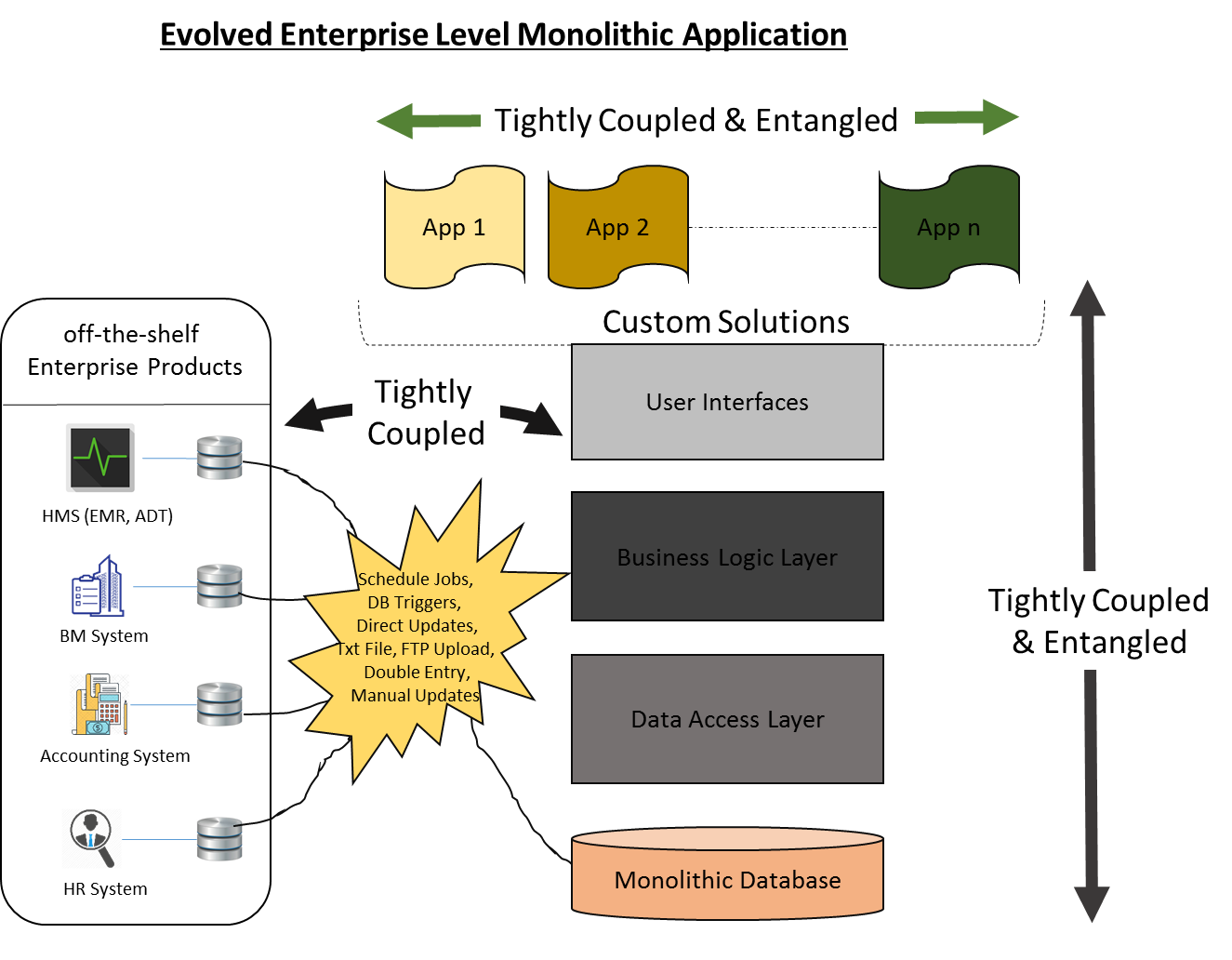
Figure 1: Tightly coupled monolithic application with ad hoc inter app integrations
As shown in the above diagram, a monolithic application is complex and its architecture is much harder to understand as one has multiple other dependent systems affecting each other. Also, the logics are not obvious especially when you are in maintenance mode looking at it from one aspect (or system point of view). In such cases, a business could lose the ability to easily maintain, quickly change, build new capabilities, and trial run strategies etc.
Even though the recent advancement (last decade or so) in web services and the web API framework managed to partially improve the situation, it also ended up with a long chain of calls that potentially lead to bottlenecks (if some of the services in the chain are more heavily called than others), hung services and cascading failures (if some of the services in the chain are unavailable), etc. Additionally, the web service (SOA) approach too has its own set of challenges when it comes to the maintainability, deployability, scalability and configurability of the business solution.
In summary, when businesses are demanding an autonomous system that has the ability to selfheal, monolithic applications are fighting their own battle with amplified complexities to deliver business agility.
Pros & Cons of Monolithis Architecture
Pros
- Less Complex
- Easy to Manage
- Easy to Maintain/ Error Tracking/ Fixing
Cons
- Limited Scalability Options
- Lack of Solution Agility
- Lack of Support for DevOps Cycle
What Other Options Do We Have?
Now let’s take a step back, and revisit this solution differently. What if we rebuild the same set of business capabilities following the trend of modularity in the physical world? This is a new way of looking at the same problem. Just visualize how an employee or a department of an organization operates and recognize the operational boundary, the role and also the responsibilities. Then think how they would deliver capabilities in helping the business to achieve its bigger operational goals. It is a flat structure with each individual employee representing capabilities, and these capabilities are orchestrated by another set of individuals at different levels of the organization. Let’s see how we can extend this thought process to redefine the architecture for this system.
Microservice Architecture

Figure 2: A microservice based architecture that gives business agility
The key advantage of Microservices Architecture is the decentralization and simplification of services. In other words, microservices are the first post-DevOps revolution architecture where changes become less expensive with built-in fail tolerance, continuous delivery and continuous integration. However, it is still a highly complex architecture with lots of moving parts. But according to the main business requirement of our solution, it was most logical to choose microservices for our solution given proven engineering rigor is in place to control the added complexities.
One of the biggest challenges in designing microservices correctly is the ‘monolithic thinking’ that each one of us trained and practiced. Monolithic thinking had to be changed before looking at any of the existing monolithic applications. Therefore, as the first step, a new solutioning technique was identified that helped in making this paradigm shift from monolithic-solutioning to microservice-solutioning.
Ideally, when trying to excerpt services, the macro level has to be looked into before going to micro level operations. Therefore, a number of examples of real world organizations were considered and various microservice-solutioning techniques were applied to identify a better technique. In one such attempt, a business is analyzed exactly the same way it operates in the manual form and all the vertical business capabilities that can be developed are categorized into a set of independent micro level services.
The art of breaking a large monolithic application starts from identifying the domains and their interactions. This is a good place to apply the domain driven design (DDD) techniques to find the bounded contexts (don't get carried away by the text book definitions, in this respect note that a bounded context could sometimes be composed of several physical services that share a single domain model as well) that will basically define the operational boundary for the microservices. A “bounded context” means an area of the business that you can identify separately having explicit boundary for its responsibility.
Let’s look at the following example related to a bank:
The Operations Department is a very important department of a bank. Is the whole “Operation Service” the bounded context to start with, or is the “Teller Service” (which is part of the “Operation Service”) the bounded context? From a feasibility point of view, “Operation Service” (macro level) would be a healthier starting point than “Teller Service” (micro level). This is where you ended up complicating simple things. Yes, once the boundary is identified that can be broken down further to identify each granular level business services.
Selecting the operational boundary for a service is always tricky. If you pick a large operation as a microservice function, it will not give the architectural value of a microservice. But if you excerpt an ultra-small function as a microservice, that will not deliver value for the business as it creates high friction/dependency among services.
Additionally, when we talk about microservices, we also talk about services that have the ability to deliver self-managed important business capabilities. As part of such autonomous services that interact with each other to provide business agility, it is important to consider what happens when parts of these services or system fail and how a system reacts to overcome failure.
Microservice Architecture - Message Streaming Solutions
Any complex system needs a lightweight and flexible way to interact with each other to deliver true business capabilities. This is true for microservices as well. There are some calls that need immediate responses, while others can wait for some time. Then again, some other systems need to be just notified about an incident.
It is true that microservices allow capability decoupling, but they require extra consideration when cross-communicating with each other. When one service depends on another in delivering business capability (especially when a synchronous response is needed to be given immediately), the coupling becomes tighter. However, you have a number of options here:
Synchronous – This method allows one service to directly call the other service and wait for its response before responding back to the UI.
HTTP (Hyper Text Transfer Protocol) – You can use HTTP, a stateless protocol, as the standard. An HTTP request can be made expecting a response accumulating data from the downstream service. Since the call is made asynchronously, you may have to block the thread while waiting for the response.
Figure 3: An application synchronously calling a downstream microservice
Asynchronous – This method will allow one service to communicate with one or more down streaming microservices simultaneously.
Microservice Architecture - Event Driven Architecture
Events represent a stream of information (data) about things that took place. “Event driven” is an architectural capability of a system to react to its environments. In more formal terms, Event-Driven Architecture (EDA) is a software architectural pattern promoting the production, detection and consumption of, and reaction to events.
Let’s look at the following example:
- The Signup Microservice creates a new user and publishes a "User-Created" event.
- The Notification Service receives the event and attempts to send an email with a welcome message back to the user.
- The UserManager Service also receives the event and attempts to add the records to the user master table.
There are many advantages of adopting EDA. When a system responds to events instead of “just-in-time” querying, it can easily be developed to be autonomous, fault tolerant, and resilient. Additionally, when the architecture is driven by events, it is not only extremely loosely coupled but also well distributed.
One of the main challenges of this type of distributed system is to maintain data consistency across services. A solution is to use an event-driven, eventually consistent approach. In this method, event sources publish events of incidents that have taken place and then the subscribers (to events) react to those events and respond/update their environment respectively, making the overall environment eventually consistent.
Microservices Architecture - Complex Event Processor
Figure 6: Overall architecture of the proposed system
MicroService Architecture – Developing a Concept for a Architecture Framework
In this DDD design exercise, we have used the more familiar knowledge and understanding of manually operated systems to develop the respective software system. In manual systems, records are maintained by people by hand, using documents and files. Despite all the problems they have, most manual systems have one big advantage and that is their stable processes and operational model, which has evolved over many generations to deal with complex situations.
Consider the following examples. Think of a fairly big hardware shop with many departments and employees. On a rainy day, if the main cashier is absent, will they close the cashier cubical with a message saying “Service Not Available”? Rather, they will let the next capable officer take over duties to handle the situation. During busy lunch hours, most banks put additional resources to handle the load in Teller Services. In such situations, the local bank manager takes the call based on priorities to reduce service-delivery-capacity of one service and increase another. When a land is sold, the deed transfer takes place but not immediately, but records get eventually consistent. In summary, even when the most critical services are not available, manually operated systems have their own ways to continue with their main operations. This is the concept that we try to incorporate into our microservice architecture design.
MicroService Architecture – Develop the Solutioning Approach
Figure 7: A typical organization is delivering business services using its resources
Now, let’s look inside a typical organization once more. In an organization, we have employees and each employee has a designated job or a set of operations to perform. Each of these jobs eventually links to the main services delivered by the organization. With that understanding, shall we identify each of these operations that an employee performs as a set of internal microservices? So in the operational boundary of a worker, there may be five or six such services. Moving on, let’s also look at the work environment (the locker which is used to secure the belongings, and the desk that holds the files and stationery) of the worker. This environment is a container that hosts the worker to perform jobs, and this could be a Docker container in the microservice world. The desk and files are like a local database of an internal microservice.
Each department consists of many employees, and these employees need to communicate with each other. Again, departments and business units also need to communicate with each other in delivering true business value to the end users. You can imagine this as a situation where one microservice is needing to call another service synchronously or asynchronously to complete its operation. If the microservice needs an immediate response, then directly calling the dependent service could be an option. If it can wait for the response, then a message queue could be a good option. This solutioning needs to take place agreeing with the way the same problem is handled and managed in the manual system.
Obviously, this approach is better for fairly complex systems. But if you are willing to bargain with complexity over agility, this can work for simple systems too. In order to successfully map a software system to a real world organization, you need to correctly analyze the software system in a way that explains how it would perform in a purely manual environment. The next step is to automate that manual process with a software model. It is highly recommended to keep similar modules, communication pattern, rules and naming conventions in between manual systems and software systems for better visualization
In summary, in “Domain-Driven Design”, success is achieved by understanding the business domain better than the business. Poor collaboration between domain experts and software development teams, and lack of study and background preparation can lead to many failures throughout the solution life cycle.
Domain Driven Design (DDD), Microservices and Bounded Context
In Domain-Driven Design (DDD), the bounded context is the center point. A domain story tells you how each worker works with each other within a domain, and that is what you have to use to identify a bounded context. Then you need to also identify how they are interconnecting.
From the concept point of view, Domain Driven Design is all about modeling a solution closer to the business. As explained before, Bounded Context is an interesting concept which defines the boundary of which a ubiquitous version of a dataset presents. Then as you move out of that boundary, the same dataset starts giving different meanings. That entity which meaningfully represents the dataset for one business context is called the domain model. So as the diagram below depicts, one business context can have many physical services which are referring to the same domain model (defined for that bounded context) which is derived from entities that may have been shared across multiple other bounded contexts.
Figure 8: Business capabilities delivered in the form of micrometrics after grouping
In our approach, we choose an iterative DDD design. Let’s define the main steps of our design process below:
- Understand the main domain, sub domain and operational domains and their operations:
- Identify main business capabilities and features
- Identify the process of delivering business capabilities
- Identify process flaws and ways to improve and optimize process flow
- Define ubiquitous language
- Understand both internal and external interactions and define meaningful operational boundaries:
- Identify parties (employees/workers) involved in delivery business capabilities from the features (tasks/jobs) point of view
- Identify communication method (directly communicated, or go through a mediator)
- Identify frequency, priority, policy, efficiency and the format of interaction
- Identify and define bounded context and domain models:
- Identify operational boundaries
- Define bounded context while looking for business features which are more efficient when delivering together
- Identify the rich domain model (the anemic domain model is an anti-pattern in microservice context) for each of your bounded context. In this respect, the entities in each Bounded Context should organize itself to suit the behaviors of that domain.
- Solutioning
- Evaluate technology application
- Evaluate technology options
- Select and introduce technologies
Design Decisions and Justifications
API Manager
We obviously decided to use an APIM as the protective layer that prevents unauthorized access to the enterprise assets and services. We had three main systems:
- The main Information System (set of web/mobile applications; all of them support online access; all together they consist of close to 600 microservices; a couple of million users access it on a daily basis).
- The off-the-shelf product suites (all are web/mobile based products with the services separated; they should be connectivity independent; a couple of thousand employees access them on a daily basis).
- The remotely deployed systems (web/mobile applications; they should be connectivity independent; they support only the service functions required by the remote departments; a couple of thousand employees access it on a daily basis).
The vendor made a policy decision to run all the systems locally in the vendor data centers. The main IS system services and off-the-shelf products backend services were deployed behind the main API manager, the main protective layer of the central data center. We evaluated options to keep one API manager for all the services as that will make it easy to manage access, system maintenance, traffic control & data analysis and configuration from a central location, but given the lack of infrastructure support of the remote centers, we had to decide against it. We were also forced to introduce multiple API managers for each remote office where they had to have a local datacenter with offline access support, and also had to hire a new System Engineer to carry out the support work. However, with this design approach, we had to put additional effort making remote applications connectivity independent. We also had to introduce a custom software agent (Merge-bot) to enable local API database sync with the main database to provide consolidated reports for decision makers.
Container Based Virtualization
(Reference: https://insights.sei.cmu.edu/sei_blog/2017/09/virtualization-via-containers.html)
In true DDD application design, microservices would not have the many advantages they have today if they cannot be pared with a minimal viable hardware piece for it to run in isolation. In other words, the true power of microservices is recognized only after coupling them with containerization technologies.
In our design, containers gave us a number of advantages by reducing hardware cost, improving scalability, and supporting spatial isolation, CI/CD, safety as well as security.
Although there are many advantages in container based virtualization, we had to explicitly address the following challenges and associated risks in our design effort:
- The application within one hardware device may share resources including OS kernel, VM resources, container engine and the actual hardware of the main server. We planned to have two instances of hardware servers to mitigate this risk and a single point of failure.
- The high number of interference paths makes error finding and root course analysis of all such paths difficult especially when memory clashes (VM or container) occur. We had to educate the customer the benefit over these disadvantages and come to a common understanding before the start of the project.
- Container sprawl (unnecessary containerization) can increase time and effort spent on container management.
In response to addressing some of these issues, we introduced a software tool to manage clustering and container orchestration. We also considered continuous integration and continuous delivery when selecting the cluster management solution.
Message Queue / Service Bus / Event Processor – Progressively Advancing Architecture
Microservices were the logical response for most of our business requirements. Even though microservices deliver system flexibility and business agility, additional design decisions were required to reduce complexity, increase velocity and also improve system performance.
Considering the cost required for separate database licenses, we decided to have one database schema for each bounded context (one bounded context serves multiple microservices belonging to that context). We also introduced a user id for each schema to prevent developers from accessing data across bounded contexts. However, to accommodate data consistency when complex business transactions go across boundaries, we used an eventually consistent, event-driven approach. A key highlight is the flexibility we had in taking architectural decisions too - we adopted a polyglot persistence architecture, where the database, programming languages and also the architectural patterns were selected considering what is best for the job. So we did not have hard and fast rules that make things rigid for us.
We had serious challenges when business capabilities were enhanced in agile mode; you tend to redefine bounded-context’s boundary every time you introduce new capabilities to one context and that lead to make us run extra cycles to balance the solution. This is where the Domain Driven Design came in useful. At a time, we focused only on one business area and completed our implementation in the way it is being practiced in the real world.
When one service needs to communicate with another service in the same context, we give priority to call directly using HTTP request. This is to reduce the complexity of the system. As you may have observed in real life situations, this is like a banking service officer directly taking the manager’s approval for above-the-limit over-the-counter money withdrawal.
In the same way, when you notice that a downstream service is underperforming, you can decide to scale up the environment to see if the situation gets better. There are other situations where scaling up alone may not meet the load requirement; then you need to scale out and start distributing services to other new containers. In these situations, our practical approach was to make the newly distributed service use the original schema that was shared with other services of the same bounded context. That is to reduce the data persistency / management related complication. Again, you find somewhat similar design decisions in real life situations too. For example, think of a banking officer who is underperforming - you first give the officer training and monitor the progress (scale-up), and if the officer fails to support the load even after achieving maximum productivity limits, you add more (scale-out) service officer(s). However, as you decide to scale-out a service, your solution shifts to the next level, where you will be forced to manage an additional set of challenges in distributing requests across multiple endpoints.
In our design exercise, a few patterns emerged:
- When services are distributed within the same bounded context, we recognize them as departments and then we mimic its operational pattern in the software system. For example, in an account department, you may have multiple clerks performing duties, and they may have copies of invoices, bills, and files/journals borrowed from the main content repository to perform their duties. All the work is piled on the clerk’s desk - in the same way, we used one schema (data cashing environment) for each service that operates in the same bounded context.
- When one worker of the same department needs to communicate with another worker, you try to communicate with the worker directly. If the service is busy, you put the message into a queue for the service to pick once completing the pending work. The message queue holding messages passes them to one or more other services in a first-in-first-out (FIFO) manner. In order to accommodate this feature, we used a special base (abstract) service class implementation with common behavior to derive from.
- When one department communicates with another department, there needs to be a little more order. Therefore, for cross boundary communication, we used a Service Bus. Each department has its own service bus. Any messages that are published to the service bus are being refereed by multiple subscribers (other departments). This approach allowed cross boundary service communication to follow the open/closed principle, since the source service allows more features to be added later related to the message without changing the original service implementation. For example, a message about a user registration may need to send an email, so that the email service may be subscribed to that message. But as the system expands, you may also introduce an option to send an additional SMS. In this situation, you can do the SMS feature implementation later and get that service subscribed with the same message to introduce the SMS sending feature.
- In the middle of all these communications, we also wanted to have another platform that basically listens to all the events, ignores some and acts on certain others based on the pattern, rules and logic, while keeping low latency with high throughput. In order to achieve this requirement, we introduced a CEP (Complex Event Processor) at the middle.
This approach requires someone to constantly analyze traffic data to see if any of the downstream services are underperforming. This is where a feature rich API manager as well as a container cluster management solution comes in handy. Tuning the environment to improve performance is a continuous activity.
History
- 2019-05-06: Initial version
References

