Introduction
This article is a contribution to the Code Lean and Mean challenge. The competition presentation states: In days of yore, it was a badge of honour to be able to fit a full file manager, spreadsheet application, appointment reminder, and Tetris Easter Egg within a 32KB executable.
This executable is as much as 22.5 KB, and only computes the smallest differences between two files. Not much room left for the spreadsheet.
The Challenge
Create an application that will calculate and display the changes between two text files as fast as possible using the least amount of memory possible. Provide timing data and maximum memory use data.
Background
The diff utility is described here, the related LCS (Longest Common Subsequence) algorithm is very well detailed here. The main application of this algorithm is in DNA studies, with our lines only composed of one letter, but our files being several millions lines long.
Issues
The LCS algorithm requires each line in a file to be compared (for equality) with all lines in the other file. The only shortcut is to exclude matching lines at the beginning and end of both files.
The algorithm is quadratic, and requires to fully populate a table with one row per line in one file and one column per line in the other. If the files are around a hundred lines, that's 10000; for files around 3000 lines, 10 millions. Don't hope to quickly compare two translations of the Bible.
The processing time also grows quadratically with the file sizes. So there is no global design trade off between memory usage and processing speed, at least with this proven algorithm. Finding new ways, unexplored by several thousands of researchers world-wide is, except for some geniuses, kind of Adventures in Wonderland, so I will stick to this algorithm.
Design
The process is purely sequential:
Check the file names and start the timer.
Open and access the files.
Exclude the matching lines at the beginning and end (if any).
Index the remaining lines.
Fill up the LCS array with the result of line comparisons.
Extract the mismatching line indexes from the LCS array.
Output the results and stop the timer.
Report time and memory consumption.
The aim for each step is to be thrifty with memory, albeit efficient and quick in processing.
Working code
Data Design
The contents of the files are accessed through memory mapping, saving some space.
The line addresses in the memory mapping space are stored in two vectors.
CAtlFileMapping<CHAR> FileMaps[2]; UINT iFirstWorkLine = 0; vector<LPCSTR> Lines[2];
The LCS data for each pair of lines is stored as:
struct LCSInfo
{
SHORT size; bool bMatch; };
This is a trade-off: recording the matching status of the pair avoids multiple readings and comparisons of the same lines, but increases the memory footprint. Packing the bool in the short would divide the array footprint by two, but will increase, more than proportionally, the processing time for recording and comparing, and be quickly compensated by an increase of 41% of the file sizes.
The LCSInfo data is stored in a single vector with bi-dimensional access:
class LCSArray : public vector<LCSInfo>
{
public:
reference operator()(UINT i, UINT j)
{
static const size_t s1 = Lines[1].size();
ATLASSERT((i < Lines[0].size()) && (j < s1));
return operator[](s1 * i + j); }
} LCS;
LCS is allocated once at its unmoving size.
Process Flow
Steps 1 & 2: Check the file names, start the timer, open and access the files.
At the end of step 1, a timer is initialized and the files are opened and mapped. On multi processor machines, the step is parallelized, which may be unnecessary in most cases.
Step 3: Exclude the matching lines at the beginning and end (if any).
Two parallel threads (if multiprocessing) look for the first mismatching char from the beginning and end of the files:
size_t
iFirstMismatch = 0,
iLastMismatch = 0;
#pragma omp parallel sections
{
#pragma omp section
{
PCHAR
pc0 = FileMaps[0],
pc0Max = pc0 + FileMaps[0].GetMappingSize(),
pc1 = FileMaps[1];
for (; (*pc0 == *pc1) && (pc0 != pc0Max); ++pc0, ++pc1)
if (*pc0 == '\n')
++iFirstWorkLine;
for (; pc <= pcLast ; ++pc)
if (*pc == '\n')
Lines[i].push_back(pc + 1);
}
If no mismatch is found, the files are identical and the program terminates.
Step 4: Index the remaining lines.
In each file, a thread (if multiprocessing) looks for the '\n' characters between the first and last mismatches, and stores the addresses in a Lines vector.
The vectors are first allocated for an approximate line length computed from the beginning matching lines, or 1024 lines, if none.
#pragma omp parallel for
for (int i = 0; i < 2; ++i)
{
PCHAR
pc = FileMaps[i] + iFirstMismatch,
pcMax = FileMaps[i] + FileMaps[i].GetMappingSize(),
pcLast = pcMax - iLastMismatch ;
if (iFirstWorkLine)
Lines[i].reserve(FileMaps[i].GetMappingSize() * iFirstWorkLine /
iFirstMismatch);
else
Lines[i].reserve(1024);
Lines[i].push_back(NULL);
Lines[i].push_back(pc++);
for (; pc <= pcLast ; ++pc)
if (*pc == '\n')
Lines[i].push_back(pc + 1);
}
Step 5: Fill up the LCS array with the result of line comparisons.
The LCS array is allocated at its known size, and the line pairs are processed sequentially. From now, no parallelizing is possible as each step depends on its predecessor.
size_t sizeLCS = (Lines[0].size() + 1) * (Lines[1].size() + 1);
LCS.resize(sizeLCS);
UINT
iStart = 1,
jStart = 1;
const UINT
iEnd = Lines[0].size() - 2,
jEnd = Lines[1].size() - 2;
for (UINT i = iStart; i <= iEnd; ++i)
for (UINT j = jStart; j <= jEnd; ++j)
{
if (MatchLines(i, j))
LCS(i, j).size = LCS(i - 1, j - 1).size + 1,
LCS(i, j).bMatch = true;
else if (LCS(i - 1, j).size > LCS(i, j - 1).size)
LCS(i, j).size = LCS(i - 1, j).size;
else
LCS(i, j).size = LCS(i, j - 1).size;
}
The MatchLines() function is called there once on each line pair, and uses approximately one third of the processing time.
inline bool MatchLines(UINT i, UINT j)
{
static const size_t
s0 = Lines[0].size() - 1,
s1 = Lines[1].size() - 1;
ATLASSERT((i < s0) && (j < s1));
if (Lines[0][i+1] - Lines[0][i] != Lines[1][j+1] - Lines[1][j])
return false;
PCCH
ps0 = Lines[0][i],
ps1 = Lines[1][j];
while (*ps0 == *ps1)
if (*ps1 == '\n')
return true;
else
++ps0, ++ps1;
return false;
}
If sizes are equals a char comparison is performed until a '\n' is found.
Step 6: Extract the mismatching line indexes from the LCS array.
The mismatching line indexes and types are extracted in reverse order from the LCS array and pushed to a Diffs stack.
UINT
y = iEnd,
x = jEnd;
while ((y > 0) || (x > 0))
{
if (LCS(y, x).bMatch)
--y, --x;
else if ((x > 0) && ((y == 0) || (LCS(y, x - 1).size > LCS(y - 1, x).size)))
AddDiffLine(1, x, DIFF_ADDED), --x;
else if ((y > 0) && ((x == 0) || (LCS(y, x - 1).size <= LCS(y - 1, x).size)))
AddDiffLine(0, y, DIFF_REMOVED), --y;
}
size_t nDiffLines = Diffs.size();
cout << endl << nDiffLines << " difference(s) found in "
<< omp_get_wtime() - fstartTime << " second(s)." << endl;
At this step, all the computing is done, so the intermediate time is output. Less than half of the total execution time is spent.
Step 7: Output the results and stop the timer.
The result line indexes and types are popped from the Diffs stack and output through std::cout::operator<<() to stdout with a simple formatting. The timer is then stopped.
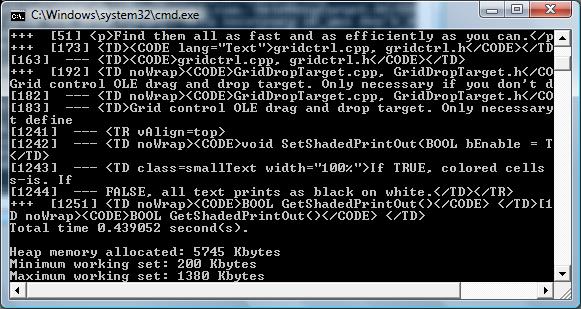
For a test with 21 lines, the output time is over the computing time.
Step 8: Report time and memory consumption.
The memory resource footprint is reasonable, the processing time is highly dependant on the system load, varying sometimes by a factor 2 in some seconds.
Conclusion
The small memory vs. high efficiency compromises are easily spotted on this simple linear process.
Nobody is perfect, cheers!
History

