Introduction
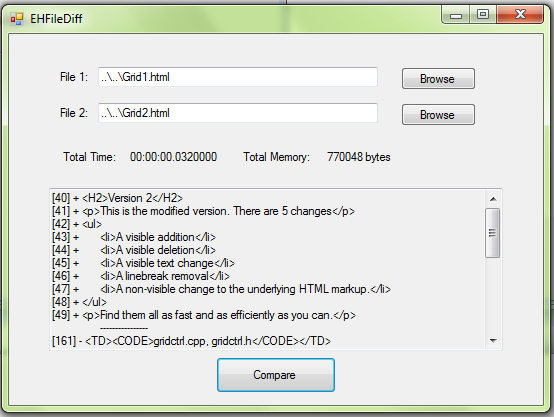
This is my C# entry to the Code Lean and Mean Competition. The idea of the contest is basically to create the leanest and meanest file diff program that can show the differences of Grid1.html and Grid2.html, running as fast as possible and using the least amount of memory.
I have also submitted an entry for the C++ version, called MeanFileCompare. I found the C# version much more challenging because it seems like no matter what you do, a ton of memory is allocated. My intentions were to use the least amount of memory possible and get a fast time. I will explain more of my memory optimizations further down in the article.
Using my techniques, I was able to get diff times for a first time run in the 30 to 50 ms time ranges, and of 4 to 10 ms running a second time after all the JITting has taken place.
Using the Code
I used a byte-to-byte comparison to do the diff because I wanted to display line numbers as well as the text, so I needed to be able to count the number of newlines in the file. Here is the main loop of the file comparison:
public void CompareFiles(string file1, string file2)
{
try
{
_compareFile1 = new CompareFile(file1);
_compareFile2 = new CompareFile(file2);
}
catch (FileNotFoundException ex)
{
_output.Append(ex.Message);
return;
}
while (true)
{
if (_compareFile1._buffer[_compareFile1._currentBufferIndex] ==
_compareFile2._buffer[_compareFile2._currentBufferIndex])
{
if (_compareFile1._buffer[_compareFile1._currentBufferIndex] == '\n')
{
_compareFile1._currentLineNumber++;
_compareFile2._currentLineNumber++;
_compareFile1._startOfLine = _compareFile1._currentBufferIndex + 1;
_compareFile2._startOfLine = _compareFile2._currentBufferIndex + 1;
}
_compareFile1._currentBufferIndex++;
_compareFile2._currentBufferIndex++;
if (_compareFile1._currentBufferIndex == _compareFile1._totalBytesInBuffer)
{
_compareFile1.ReadMoreData();
}
if (_compareFile2._currentBufferIndex == _compareFile2._totalBytesInBuffer)
{
_compareFile2.ReadMoreData();
}
if (_compareFile1._fileCompletelyRead || _compareFile2._fileCompletelyRead)
{
if (_compareFile1.EndOfFile || _compareFile2.EndOfFile)
{
if (!_compareFile1.EndOfFile || !_compareFile2.EndOfFile)
{
FindDifferences();
}
break;
}
}
}
else
{
_compareFile1.ReadMoreData();
_compareFile2.ReadMoreData();
FindDifferences();
if (_compareFile1.EndOfFile && _compareFile2.EndOfFile)
{
break;
}
}
}
_compareFile1.CloseFile();
_compareFile2.CloseFile();
}
Lean and Mean
The whole idea of this competition was to keep your program Lean and Mean, so to keep in the spirit of the competition, I allocated a 2K buffer and read in chunks to perform the diff, while an easier way would have been to read in the full file and perform the diff using the entire 187,731 bytes, but I don't think that would be keeping your program "lean".

If I need to increase the buffer due to comparing a line that exceeds the 2K size limit, or if a comparison of differences is exceeding the limit, I increase the buffer size in 2K blocks until the line or comparison has been satisfied.
To make things even leaner, I did not even create a separate buffer to read the data into. I created an unsafe pointer so I could append the data being read from the file directly into the buffer.
[DllImport("kernel32.dll", SetLastError = true)]
public static extern unsafe bool ReadFile(IntPtr handle, IntPtr buffer,
UInt32 numberOfBytesToRead,
out UInt32 numberOfBytesRead,
IntPtr overlapped);
.
.
.
unsafe bool ReadBytes(int offset, UInt32 bytesToRead, ref UInt32 bytesRead)
{
fixed (byte* pBuffer = _buffer)
{
IntPtr p = (IntPtr)(pBuffer + offset);
if (ReadFile(_fileHandle, p, bytesToRead, out bytesRead, IntPtr.Zero))
{
return true;
}
return false;
}
}
History
- 8/31/2009 - Initial release.

