Introduction
Quicksort is a well known algorithm used in data sorting scenarios developed by C. A. R. Hoare. It has the time complexity of O (n log n) on average case run and O (n2) on worst case scenario. But Quicksort is generally considered to be faster than some of sorting algorithms which possess a time complexity of O (n log n) in average case. The fundamental of Quicksort is choosing a value and partitioning the input data set to two subsets in which one contains input data smaller in size than the chosen value and the other contains input data greater than the chosen value. This chosen value is called as the pivot value. And in each step, these divided data sets are sub-divided choosing pivots from each set. Quicksort implementations are recursive and stop conditions are met when no sub division is possible.
Background
In this attempt, the main idea was to implement a parallelized Quicksort to run on a multi-core environment and conduct a performance evaluation. This parallelization is obtained by using MPI API functionalities to share the sorting data set among multi processes.
Basic Implementation Steps
- Perform an initial partitioning of data until all the available processes were given a subset to sort sequentially
- Sort the received data set by each process in parallel
- Gather all data, corresponding to the exact partitioned offsets without performing any merging
Initial Data Partitioning and Sub Array Allocations
The scheme of initial data partitioning contains the following steps:
- Each process performs an initial partitioning of data using pivots if there’s any process available to share its data set.
- Send one part of data to the sharing process and start partitioning the remaining data set if there’s more processes available.
- Else perform a sequential Quicksort on the data set.
- Send locally sorted data set to its original sender.
This scheme requires a proper allocation of processes in each partitioning and data sharing steps. The scheme I used is to allocate data considering its rank and a calculation schema which determines which processes will share the data set.
Process Allocation Scheme
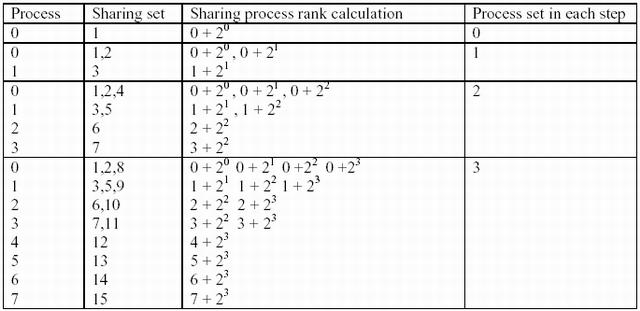
Processes are allocated using the following equation:
Process p with the rank r will share its partition with the process rank.

With this calculated rank, each process will try to find its data partition sharing process. If the process is there, then the partition is sub divided and shared with the process which possesses that particular rank. If there is no such process, then the partition is sequentially sorted and sent back to the parent process who originally shared the sorted set. Each of these calls is implemented to run recursively.
Choosing Which Partition to Share
In most cases, partitions produced by regular sampling may differ in size. So when any partitioning is performed to share the data set, the largest sub partition is kept within the lead process and the smaller set is sent to the receiving process. There are two reasons to send the smaller partition. They are:
- It reduces the amount of communication overhead by transferring the smaller data set.
- In process allocation schema, the process that is responsible in partitioning will be the process next in line to share the data set once again before the receiving process. So if any more processes are in the pool, the sending process has more chance in sharing its data set than the receiving process.
Example: For a data set to be sorted using three processes, 0th process will send the smaller data set to 1st partition. Then the remaining process number 2 will be assigned to process number 0 to share its data set. So before 1st process gets a data sharing process, the process number 0 that created the partitions has the chance of having another process to share its data set.
The performance gain was checked using a slightly changed parallel Quicksort implementation where the lead process always keeps the first half of the array. This altered version ran against the smaller partition sharing Quicksort implementation. Sorting time tends to be smaller on smaller partition sharing implementation than the first half of array sharing implementation.
Implementation
Parallel Quicksort was implemented using OpenMPI, one of the open source MPI implementations available. The program is written in C language.
Function sort_recursive
This function is called recursively by each process in order to perform the initial partitioning when a sharing process is available or to sequentially sort the data set. Finally it sends the sorted data set to its sharing process. The pivot for each step is chosen as the element indexed at [size / 2], which takes the middle value of the array. Also a specific index value is used to keep the number of increments while calculating the rank of next process in line to share the data set recursively.
int sort_recursive(int* arr, int size, int pr_rank, int
max_rank, int rank_index){
MPI_Status dtIn;
int share_pr = pr_rank + pow(2, rank_index);
rank_index ++;
if(share_pr > max_rank){
return 0;
}
int pivot = arr[size/2];
int partition_pt = sequential_quicksort(arr, pivot, size,
(size/2) -1);
int offset = partition_pt + 1;
if (offset > size - offset){
MPI_Send((arr + offset), size - offset, MPI::INT, share_pr
, offset, MPI_COMM_WORLD);
sort_recursive (arr, offset, pr_rank, max_rank,
rank_index);
MPI_Recv((arr + offset), size - offset, MPI::INT, share_pr,
MPI_ANY_TAG, MPI_COMM_WORLD, &dtIn);
}
else{
MPI_Send(arr, offset, MPI::INT, ch_pr , tag,
MPI_COMM_WORLD);
sort_recursive ((arr + offset), size - offset, pr_rank,
max_rank, rank_index);
MPI_Recv(arr, offset, MPI::INT, ch_pr, MPI_ANY_TAG,
MPI_COMM_WORLD, &dtIn);
}
Except the leading process, all other processes will execute the following lines of code:
int* subarray = NULL;
MPI_Status msgSt, dtIn;
int sub_arr_size = 0;
int index_count = 0;
int pr_source = 0;
while(pow(2, index_count) <= rank)
index_count ++;
MPI_Probe(MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD,
&msgSt);
MPI_Get_count(&msgSt, MPI::INT, &sub_arr_size);
pr_source = msgSt.MPI_SOURCE;
subarray = (int*)malloc(sub_arr_size * sizeof(int));
MPI_Recv(subarray, sub_arr_size, MPI::INT, MPI_ANY_SOURCE,
MPI_ANY_TAG, MPI_COMM_WORLD, &dtIn);
int pivot = subarray[(sub_arr_size / 2)];
sort_rec(subarray, sub_arr_size, rank, size_pool -1,
rec_count);
MPI_Send(subarray, sub_arr_size, MPI::INT, pr_source,
tag, MPI_COMM_WORLD);
free(subarray);
Experimental Results
Quicksort implementation was benchmarked with a parallel Quicksort implementation with merge and with sequential Quicksort implementation letting them to sort the same set of data in varying sizes. These test results were gathered by running a batch of sorting tasks on each test case and averaging all the obtained results.
- All these tests were performed on a Linux cluster of 7-core Intel Xeon E5420 processors with 16 GB memory.
The benchmarks were run for the following scenarios:
- Sorting data sets of 5 – 100 M with five processes for each implementation.
- Sort data set of 10 M for a process range 1 - 10 , 1 M for a process range 5 – 70.
Parallel Quicksort with Merge
This implementation belongs to Puneet C Kataria’s, [Parallel Quciksort Implementation Using MPI and Pthreads] a project aimed to implement a parallelized quicksort with minimum cost of merging by using tree structured merging. He is currently a graduate student and more details about his implementation can be found in his personal page here.
Graph1 indicates a lowest running time for parallel Quicksort with merge and the time increment tends to be very smooth and linear. The parallel quicksort without merge tends to show fluctuations with the increasing size of data set yet linear.
Graph2 indicates that the two implementations tend to show close results, yet the parallel Quicksort without merge implementation shows much irregularity than the other parallel implementation.
These results show that the overall parallel implementation with initial partitioning and merging outperforms the parallel Quicksort implementation without merge. Also the fixed partitioning shows much smoother increment of time with increasing data size on less number of processes. But the parallel Quicksort without merge shows the opposite behavior as it gets smoother with higher number of processes.
Time Complexity Analysis
With the general assumption of time complexity for sequential quicksort = n log n, Let’s take the best case sort analysis for the above implementation. So assuming that each partitioning might create two equal sections:
For a two process running, T (n) = (n/2) log (n/2)
For three process running, T (n) = max ((n/2) log (n/2) + (n/4) log (n/4)) = (n/2) log (n /2)
According to table 1, after 4 processes running, T (n) = (n/4) log (n/4)
Hence for p number of processes, T (n) = (n / k) log (n / k) where k satisfies = 2k-1 < p < = 2k
But since the implementation runs as sharing the smallest partition strategy and variable partitioning sizes, this time analysis can’t prove the average running time for the parallel Quicksort without merging. Also adding up the overhead of communication is not taken into account. Also the experimental results prove that this time complexity isn’t preserved for the average run of the implementation.
Conclusion
With the performance analysis, it’s evident that the new implementation seems to become more efficient with a higher number of processes. Also it could outperform with merge implementation in certain number of processes. But with the performance basis, the lowest running time was shown by the with merge implementation for a lesser number of processes. Without merge implementation performs less efficiently with fewer number of processes. As for the conclusion, below points can be highlighted.
- Initial partitioning can be very crucial in parallel Quicksort with MPI. After implementing parallel Quicksort without initial fixed partitioning and running it against a counter-implementation, it’s evident that the time efficiency gains from initial fixed partitioning is important. If not, a better way to perform initial partitioning through regular sampling is vital in order to gain higher performance.
- With MPI, two parallel implementations tend to show less performance on higher number of processes since MPI communication overheads. This overhead has to compensate by limiting the amount of running processes according to the data set size.
- Also partitioning through regular sampling can cause very irregular running time due to variable partitioning in each step. Also this may lead to a worst case of highly unbalanced data distributions which might lead to inefficient time performances.
- With variable partitioning in each step considering the available processes, some processes may not be efficiently used. In fact for the worst case with a higher number of processes for a small data set, some processes may leave out without any data to sort sequentially which shows inefficient use of processes.
So this analysis emphasized the point of initial partitioning combined with regular sampling that can partition input data set to equal subsets is important in order to improve performance in parallel quicksort. Also more parallelized merging and regular sampling can improve performance.
Points of Interest
This article came as a result of experimenting MPI to parallelize Quicksort to sort data in parallel. The complete report prepared is available with this article. No codes or program will be available with this article since it was written with the purpose of presenting a research study rather than to present a usable application code.
History
- 13th September, 2009: Initial post

