Introduction
This visualizer for Visual Studio 2008 enables any string (in hex format) to be parsed as ASN1 / DER encoded data (if possible).
If you don't know what ASN1 / DER encoded data is, you probably won't need this visualizer, but you can find lots of data about this encoding because it's used in all kind of protocols (I've seen it most on security related protocols like SCEP, OCSP, .CER files, .PEM files, .REQ files, etc.)
Example of Usage
Convert a byte[] into a string (you can do this in the watch or the quickwatch directly):
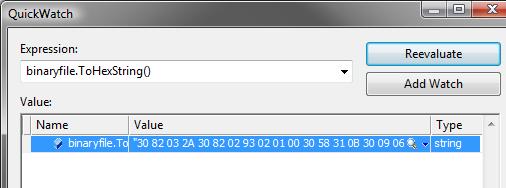
It will show something like this:

The information displayed in each node is:
("Type of data", "length of data") UnB: "length of the unused bytes (should be 0 always) -> "data decoded".
Example
The selected node is of type "Sequence" with 11 bytes of length, no unused bytes, and [#]: 2 means it has 2 children (sequences and sets don't have data themselves, they hold other nodes).
The following node is of type "Object Identifier" with a length of 3 bytes, no unused bytes, and it's OID value is "2.5.4.7" (the "(localityName)" is the common name of the OID, and will be displayed if found on the resources of the application).
The "path" on the top should be useful if you have a recursive structure for reading ASN1 Data, it shows you the child[#] path to your current location.
Background
Developing a SCEP/OCSP client for my company, I found it very tedious to parse and navigate through the recursive structure the ASN1 encoded data creates. So I needed a way to see this data in a better way.
I found an editor, the ASN.1 Editor by Lipinshare (www.lipinshare.com) and it was useful, but not integrated with my development environment (.NET 2008). So I started looking around their code, and checking articles about Visualizers for Visual Studio till this came out.
I later added an XML with the OID descriptions for readability, and some menu options for expanding/collapsing the tree, and looking up things directly.
I thought this would help developers who are in this same situation, as well as developers who want to look at how a visualizer for Visual Studio works.
Using the Code
Using the visualizer is quite simple (installation instructions are inside the zip file in the readme.txt). After you have it installed, just watch (or quickwatch) a string, and click on the Spyglass button to bring up the visualizer. If the format of the string is not valid, the visualizer will show a message accordingly.
Creating a Visualizer for Visual Studio is not that complicated, and there are great articles on how to make them (http://geekswithblogs.net/technetbytes/archive/2008/06/11/122792.aspx is the one I used). The tricky part about this visualizer was that Visual Studio doesn't support visualizers for Arrays, so i couldn't do a visualizer for a byte[] like I wanted, so I had to make it a string visualizer (for hex strings).
This implied some conversions which I put on both the visualizer initialization (from hex to byte[]) and on the ASN1Generator class (byte[] to hex). In the screenshot above, I'm simply using an extension that calls that method.
Extension
public static string ToHexString(this byte[] value)
{
return ASN1Generator.ByteArrayToHexString(value);
}
Method
public static string ByteArrayToHexString(byte[] pBytes)
{
string lString = "";
foreach (byte lB in pBytes)
{
lString += lB.ToString("X2") + " ";
}
return lString.Trim();
}
The conversion from hex string to byte array is more complicated:
public static byte[] HexStringToByteArray(string pHexString)
{
string lNewString = "";
for (int i = 0; i < pHexString.Length; i++)
{
char c = pHexString[i];
if (IsHexDigit(c))
lNewString += c;
}
if (lNewString.Length % 2 != 0)
{
lNewString = lNewString.Substring(0, lNewString.Length - 1);
}
int lByteLength = lNewString.Length / 2;
byte[] bytes = new byte[lByteLength];
int j = 0;
for (int i = 0; i < bytes.Length; i++)
{
string hex = new String(new[] { lNewString[j], lNewString[j + 1] });
bytes[i] = HexToByte(hex);
j = j + 2;
}
return bytes;
}
(That is not my code, but I can't remember where I got that function.)
The IsHexDigit(char) function just makes sure only valid hex chars get into the final parsed string (no spaces or weird chars).
The HexToByte(string) function converts a 1 or 2 char hex value into a byte.
After the string data gets converted back to byte[], we can now parse it as ASN1/Der encoded data.
The ASN1 Node Class
Before I get into the decoding itself, I need to show you how the ASN1 nodes will be formed.
An ASN1 node has the basic properties:
- Tag - The type of data the node holds.
Enumerated - An enumerated value (basically an integer with a meaning) Integer - A simple Integer (any length) (comes backwards) BitString - A string of bits (it has its own encoding format) OctectString - Basically, a ByteArray Null - Nothing, null, empty, etc. It's always 0x05 0x00 (complete node) (no length data) - Object Identifier -An OID (universal object identifier) (it has its own encoding)
- Sequence - As its name implies, it's a sequence of items, with order.
- Set - A set of items (unordered sequence)
- Printable String - a String of printable characters
T61String -another type of string (never encountered it, so I really don't know what it's about) IA5String - (same as above) UTCTime - A datetime format always in UTC time zone (it has its own encoding) - Generalized Time - a datetime format with a time zone offset (it has its own encoding)
Tag decoding is in the ASN1Node.DecodeTag(byte) function.
- Length - The length of the data
Length decoding is in the ASN1Node.DecodeLength(byte[],out int) function, it's used in the decoding of the node, so it will be talked over later.
- Data - The data of the Node itself
Data decoding is in the ASN1Node.DecodeData(bool) function.
RawData - The complete Node (Tag + Length + Data) (used for copying, for example) UnusedBytes - This should always be empty, it's an array of bytes that were left unused (Example: A sequence says it has 1000 bytes length, but its children only sum up to 900 bytes, this property will hold the remaining 100 bytes) - Child Nodes - A collection of the nodes that belong to this one (its children in the tree).
Decoding the Data
This is the tricky part, because ASN1 structures are recursive and type-less (almost any structure can contain anything). So the first step was to get what type of data we are looking at.
The first byte of a ASN1 Der encoded array is the type of data it contains (again, tricky, because there are various definitions and a lot of variable data types).
At the second byte starts the length of the data:
- If the data is less than 127 bytes long, this byte tells us the length.
- If the data is longer than that, this byte tells us the length of the real length of the data (how many bytes it takes to tell you the length of the rest of the data)
So if we have a 0x02, we know the actual data is 2 bytes long. But if we have 0x83, all we know is that the next 3 bytes tell us what the data length is.
I combined all this into a function:
private static byte[] DecodeTagAndLength(
byte[] pBytes,
out ulong oLength,
out byte oTag,
out byte[] oData)
{
oTag = pBytes[0];
int lSkip;
oLength = DecodeLength(pBytes.Skip(1).ToArray(), out lSkip);
oData = pBytes.Skip(lSkip + 1).Take((int) oLength).ToArray();
return pBytes.Skip(lSkip + 1 + (int)oLength).ToArray();
}
Well, actually 2 functions, the above one will get the Type of the data (called Tag), call another function to decode the length, return the actual data in the oData output parameter, and return the remaining data in the array for further processing.
The DecodeLength function will get the actual length of the data to take, and will return the amount of bytes that the length data took, so we can skip them to get to the data.
private static ulong DecodeLength(byte[] pBytesWithNoTag, out int oSkip)
{
oSkip = 0;
if (pBytesWithNoTag.Length == 0)
return 0;
if (pBytesWithNoTag[0] > 0x80)
{
int lLen = pBytesWithNoTag[0] - 0x80;
byte[] lRealLen = new byte[8];
for (int i = 0; i < lLen; i++)
{
lRealLen[7 - lLen + 1 + i] = pBytesWithNoTag[i + 1];
}
oSkip = lLen + 1;
return BitConverter.ToUInt64(lRealLen.Reverse().ToArray(), 0);
}
oSkip = 1;
return pBytesWithNoTag[0];
}
So, basically we have a byte array with all the data, with the DecodeTagAndLength function we can get both the data of that node, its type, its length and as a result of the function, the remaining data of the array for further decoding.
So, our recursive decoding function would look like this:
private byte[] Decode(byte[] pRawData)
{
if (pRawData == null)
{
throw new ArgumentNullException
("pRawData", "FullRawData cannot be null when Decode is called");
}
FullRawData = pRawData;
try
{
byte[] lRemainingData = DecodeTagAndLength
(FullRawData, out mLength, out mTag, out mData);
TryDecodeInternalData();
FullRawData = FullRawData.Take(FullRawData.Length -
lRemainingData.Length).ToArray();
return lRemainingData;
}
catch( IndexOutOfRangeException ex)
{
throw new FormatException("Decoder couldn't decode RawData.", ex);
}
catch (Exception ex)
{
throw new FormatException("Decoder couldn't decode RawData.", ex);
}
}
The TryDecodeInternalData() will decode the children (if any) by calling the Decode function again.
private void TryDecodeInternalData()
{
ASN1Node lNode;
byte[] lRemaining = new byte[] {};
if ((Tag == (byte)ASN1DataType.Sequence) || (Tag == (byte)ASN1DataType.Set))
{
try
{
lNode = new ASN1Node();
lRemaining = lNode.Decode(Data);
ChildNodes.Add(lNode);
while (lRemaining.Length > 0)
{
lNode = new ASN1Node();
lRemaining = lNode.Decode(lRemaining);
ChildNodes.Add(lNode);
}
}
catch (FormatException ex)
{
Trace.TraceError("Format Exception decoding
Internal Data of Sequence or Set: " + ex.Message);
UnusedBytes = lRemaining;
}
catch (Exception ex)
{
Trace.TraceError("Unknown Exception decoding
Internal Data of Sequence or Set: " + ex.Message);
throw;
}
}
else if ((Tag == (byte)ASN1DataType.OctetString) ||
(Tag == (byte)ASN1DataType.Bitstring) || (Tag) >= 0xA0)
{
try
{
lNode = new ASN1Node();
lRemaining = lNode.Decode(Data);
if (lNode.mTag != 0)
{
ChildNodes.Add(lNode);
}
if (lRemaining.Length == 0)
{
UnusedBytes = lRemaining;
}
}
catch (FormatException)
{
return;
}
catch (Exception ex)
{
Trace.TraceError("Unknown Error decoding Internal Data: " + ex.Message);
return;
}
}
}
Basically this function is divided in two parts. First, if the node is an array container (a Sequence, or a Set) it needs to have children (if it has data in it). This means that the data inside the Sequence or Set nodes need to be ASN1 Der encoded nodes themselves.
The second part of the function (the else part) is a TRY TO DECODE ANYWAY. Even if the type of the node is not a Sequence or a Set, it can contain ASN1 nodes (many protocols insert data inside OCTECT STRINGS for example) so we try to decode the data anyway. It was divided because if an error occurs in the first part of the function, we need to abort, because the Sequence or Set is not well formed. But if an error occurs inside the second part of the function, we can continue (the OCTECT STRING just contained random data, for example).
I know there is a better way to go about this last function, but I did not have the time to modify it again yet. Feel free to "better" it in any way you please, and, if you can, post it as a comment here so I can update the code.
After this, we have our nodes, so we can safely walk through them to show them in the treeview (or to get data from them, or anything you want).
ASN1 Generator Class
To be continued...
History
- 2009/09/15 - Initial post
- 2009/09/16 - Added images and some code to the article, no changes to the code.
- 2009/09/16 - Changed licensing type to CPOL, re-uploaded code with this change and some minor compiler warnings corrections (some unreachable code removed)
- 2009/09/17 - More changes to the article, small changes to the code (removed some extra tag text in the message of some exceptions)
I would appreciate any comments, suggestions, bugfixes, or tips in general about this code, or any better ways to do things. Added functionality and all those things are welcome too!

