Introduction
Quite some time ago, I published an article on how to detect the encoding of an given text. In this article, I describe the next step on the long way to text classification: the detection of language.
The given solution is based on n-gram and word occurrence comparison.
It is suitable for any language that uses words (this is actually not true for all languages).
Depending on the model and the length of the input text, the accuracy is between 70% (only short Norwegian, Swedisch and Danisch classified by the "all" model) and 99.8%, using the "default" model.
Background
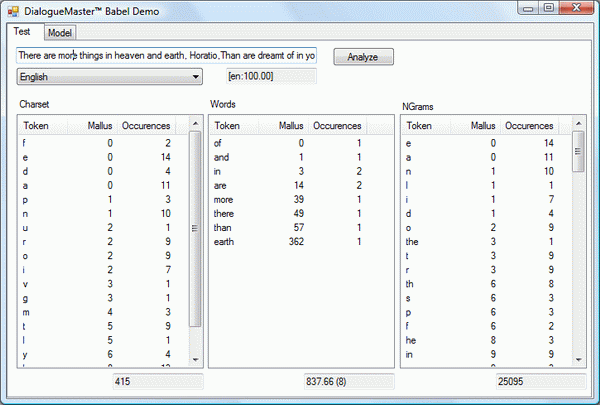
The language detection of a written text is probably one of the most basic tasks in natural language processing (NLP). For any language depending processing of an unknown text, the first thing to know is which language the text is written in. Luckily, it is one of the easier challenges that NLP has to offer. The approach I have chosen to implement is widely known and pretty straightforward. The idea is that any language has a unique set of character (co-)occurrences.
The first step is to collect those statistics for all languages that should be detectable. This is not as easy as it may sound in the first place. The problem is to collect a large set of test data (plain text) that contains only one language and that is not domain specific. (Only newspaper articles may lack the use of the word “I” and direct speech. Using Shakespeare plays will not be the best approach to detect contemporary texts. Medical articles tend to contain too many domain specific terms which are not even language specific (major, minor, arteria etc…).) And if that would not be hard enough, the texts should not be copyrighted. (I am not sure if this is a true requirement. Are the results of statistical analytics of copyrighted texts also copyrighted?) I have chosen to use Wikipedia as my primary source. I had to do some filtering to "clean" the sources from the ever present English phrases that occur in almost any article – no matter what language they are written in (I actually used Babel itself to detect the English phrases). The clean up was in no way perfect. Wikipedia contains a lot of proper names (i.e., band names) that often contain a “the” or an “and”. This is why those words occur in many languages even if they are not part of the language. This must not necessarily be a disadvantage, because Anglicism is widely spread across many languages. I created three statistics for each language:
- Character set
Some languages have a very specific Character set (e.g., Chinese, Japanese, and Russian); for others, some characters give a good hint of what languages come in question (e.g., the German Umlauts).
- N-Grams
After tokenizing the text into words (where applicable), the occurrences of each 1, 2, and 3-grams were counted. Some n-grams are very language specific (e.g., the "TH" in English).
- Word list
The last source of disambiguation is the actually used words. Some languages (like Portuguese and Spanish) are almost identical in used characters and also the occurrences of the specific n-grams. Still, different words are used in different frequencies.
A set of statistics is called a model. I have created some subsets of the "all" model that meet my needs the best (see table below). The "common" model contains the 10 most spoken languages in the world. The “small” and “default” are based on my usage scenarios. If you are from another part of the world, your preferences might be different. So please take no offence in my choice of what languages are contained in which model.
All statistics are ordered and ranked by their occurrences. Within the demo application, all models can be studied in detail. Classification of an unknown text is straightforward. The text is tokenized and the three tables for the statistics are generated. The result table is compared to all tables in the model, and a distance is calculated. The comparison table from the model that has the smallest distance to the unknown text is most likely the language of the text.

Sample model
Using the code
Quick word about the code
Babel is part of a larger project. I wanted the Babel assembly to work stand-alone. Since some of the used classes originally were scattered across many assemblies, I used the define "_DIALOGUEMASTER" to indicate whether to use the DialogueMaster™ assemblies or implement (a probably simpler) version in place.
Any impartand DialogueMaster™ class is remotable. The clients need only one assembly containing all the interface definitions. This is why Babel uses so many interfaces where they might seem to bloat the code in the first place. Additionally, DialogueMaster™ offers lots of PerformanceCounters. I chose to omit them for an easier usage of the assembly (no installation and no admin rights needed).
What I actually want to say is: the code is not as readable and clean as it could (and should) be.
Classify text
Usage of the code is straightforward. First, you must chose (or create your own) model. The ClassifyText method returns a ICategoryList which is a list of ICateogry (name-score pairs) items sorted descending by their score.
using System;
class Program
{
static void Main(string[] args)
{
DialogueMaster.Babel.BabelModel model = DialogueMaster.Babel.BabelModel._AllModel;
String s = System.Console.ReadLine();
while (s.Length > 0)
{
DialogueMaster.Classification.ICategoryList result = model.ClassifyText(s, 10);
foreach (DialogueMaster.Classification.ICategory category in result)
{
System.Console.Out.WriteLine(" {0} : {1}", category.Name, category.Score);
}
s = System.Console.ReadLine();
}
}
}
Define your own model
From existing set
To define your own model from the existing set of languages, simply create a new BabelModel and add the required languages from the _AllModel.
class Program2
{
static void Main(string[] args)
{
DialogueMaster.Babel.BabelModel model = new DialogueMaster.Babel.BabelModel();
model.Add("de", DialogueMaster.Babel.BabelModel._AllModel["de"]);
model.Add("en", DialogueMaster.Babel.BabelModel._AllModel["en"]);
model.Add("sv", DialogueMaster.Babel.BabelModel._AllModel["sv"]);
String s = System.Console.ReadLine();
while (s.Length > 0)
{
DialogueMaster.Classification.ICategoryList result = model.ClassifyText(s, 10);
foreach (DialogueMaster.Classification.ICategory category in result)
{
System.Console.Out.WriteLine(" {0} : {1}", category.Name, category.Score);
}
s = System.Console.ReadLine();
}
}
}
Add new language
To add a new language is pretty straightforward. All you need is some learn data text.
class Program3
{
static void Main(string[] args)
{
DialogueMaster.Babel.BabelModel model = new DialogueMaster.Babel.BabelModel();
TokenTable klingonTable = new TokenTable(new FileInfo("LearnData\\Klingon.txt"));
TokenTable vulcanTable = new TokenTable(new FileInfo("LearnData\\Vulcan.txt"));
model.Add("kling", klingonTable);
model.Add("vulcan", klingonTable);
model.Add("en", DialogueMaster.Babel.BabelModel._AllModel["en"]);
String s = System.Console.ReadLine();
while (s.Length > 0)
{
DialogueMaster.Classification.ICategoryList result = model.ClassifyText(s, 10);
foreach (DialogueMaster.Classification.ICategory category in result)
{
System.Console.Out.WriteLine(" {0} : {1}", category.Name, category.Score);
}
s = System.Console.ReadLine();
}
}
}
Points of interest
Supported languages
| Language Code | Language | Quality | Default | Common | Large | Small |
|---|
| nl | Dutch | 13 | x | | x | |
| en | English | 13 | x | x | x | x |
| ca | Catalan | 13 | | | | |
| fr | French | 13 | x | x | x | x |
| es | Spanish | 13 | x | x | x | x |
| no | Norwegian | 13 | x | | x | |
| da | Danish | 13 | x | | x | |
| it | Italian | 13 | | | x | x |
| sv | Swedish | 13 | x | | x | |
| de | German | 13 | x | x | x | x |
| pt | Portuguese | 13 | x | x | x | |
| ro | Romanian | 13 | | | | |
| vi | Vietnamese | 13 | | | | |
| tr | Turkish | 13 | | | x | |
| fi | Finnish | 12 | | | x | |
| hu | Hungarian | 12 | | | x | |
| cs | Czech | 12 | | | x | |
| pl | Polish | 12 | | | x | |
| el | Greek | 12 | | | x | |
| fa | Persian | 12 | | | | |
| he | Hebrew | 12 | | | | |
| sr | Serbian | 12 | | | | |
| sl | Slovenian | 12 | | | | |
| ar | Arabic | 12 | | x | | |
| nn | Norwegian, Nynorsk (Norway) | 12 | | | | |
| ru | Russian | 11 | | x | x | |
| et | Estonian | 11 | | | | |
| ko | Korean | 10 | | | | |
| hi | Hindi | 10 | | x | | |
| is | Icelandic | 10 | | | | |
| th | Thai | 9 | | | | |
| bn | Bengali (Bangladesh) | 9 | | x | | |
| ja | Japanese | 9 | | x | | |
| zh | Chinese (Simplified) | 8 | | x | | |
| se | Sami (Northern) (Sweden) | 5 | | | | |
References
History
- 10/10/2009: Initial version released.

