Introduction
When designing software, performance is usually a top priority, and as newer technologies and techniques become available, it is important to evaluate them to determine if they will be useful for the solution.
This articles doesn't attempt to be an in-depth coverage of the Entity Framework. It merely presents findings for various methods of using Entity Framework and their performance characteristics so decisions can be made and the best techniques and technology can be chosen for the solution.
Test Environments
The following environments were used to run the tests in the article:
- Windows 7 x64, Intel® Core™2 Duo 2.64GHz, 8 GB RAM
- Windows Server 2008 R2 x64, AMD Phenom™ Quad-Core 1.8 GHz, 8 GB RAM
Except where noted, all tests were compiled and run using .NET Framework 4.0.
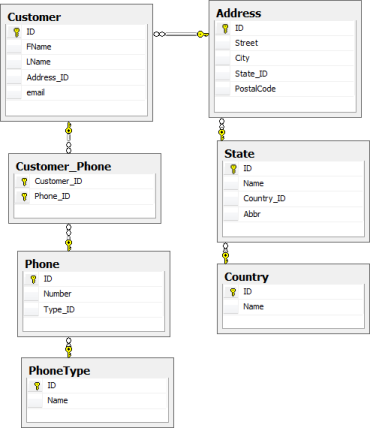
Database Schema
The database schema for these tests was designed to be representative of a common scenario; storing customer related information.
Test Harness
The application uses a small private class to store information about each test:
private class TestRun
{
public TestRun(string name, Action test)
{
Name = name;
Test = test;
}
public string Name { get; private set; }
public Action Test { get; private set; }
public double ExecuteTime { get; set; }
}
A collection of these objects is created for each test to be run.
Tests.Add(new TestRun("Clear",new Action(ADOTests.Clear)));
Tests.Add(new TestRun("ADO Insert", new Action(ADOTests.InsertCustomers)));
Tests.Add(new TestRun("ADO Get", new Action(ADOTests.GetCustomers)));
Tests.Add(new TestRun("Clear", new Action(ADOTests.Clear)));
Tests.Add(new TestRun("EF Batch Insert", new Action(EFTests.InsertCustomers_Batch)));
Tests.Add(new TestRun("Clear", new Action(ADOTests.Clear)));
Tests.Add(new TestRun("EF Single Insert", new Action(EFTests.InsertCustomers_Single)));
Tests.Add(new TestRun("EF Get", new Action(EFTests.GetCustomers)));
Tests.Add(new TestRun("EF Get Compiled", new Action(EFTests.GetCustomers_Compiled)));
Tests.Add(new TestRun("EF Get Compiled NoTracking",
new Action(EFTests.GetCustomers_CompiledNoTracking)));
Tests.Add(new TestRun("EF Get Execute", new Action(EFTests.GetCustomers_Execute)));
Tests.Add(new TestRun("EF Get NoTracking", new Action(EFTests.GetCustomers_NoTracking)));
Each set of tests is run five times to produce an average.
for(int x = 0; x < 5; x++)
{
foreach(var test in Tests)
{
test.ExecuteTime = DoTest(test.Test,test.Name);
LogComplete(test);
}
LogToFile();
}
Each test is itself run the specified number of times, 10 in this case.
private const int ITERATIONS = 10;
for(int x = 0; x < ITERATIONS; x++)
{
Console.WriteLine("{0} test: {1}", testName, x + 1);
Stopwatch.Reset();
Stopwatch.Start();
test();
Stopwatch.Stop();
executeTime += Stopwatch.Elapsed.TotalSeconds;
Console.WriteLine("Total Seconds for {0}: {1}", testName,
Stopwatch.Elapsed.TotalSeconds);
Console.WriteLine("---------------------------");
}
The Clear method is handled as a special case since it only needs to be run once. The purpose of this method is simply to clear any rows from the tables that were entered from previous tests or test runs.
if(testName == "Clear")
{ test(); return 0;
}
ADO.NET Baseline
ADO.NET has been around for quite a few years, and is a technology most developers are familiar with for data access. The first set of tests will use this familiar technology to establish a baseline for comparisons.
For the ADO.NET test, I'll be using some fairly pedestrian Stored Procedures, nothing elaborate, as the snippet below shows. The remaining Stored Procedures can be found in the downloads for this article.
CREATE PROC InsertCustomer(@FName NVARCHAR(20),@LName NVARCHAR(30),
@Address_ID INT, @Email NVARCHAR(200) )
AS
BEGIN
SET NOCOUNT ON
INSERT INTO Customer(FName, LName, Address_ID, email)
VALUES (@FName, @LName, @Address_ID, @Email)
RETURN SCOPE_IDENTITY()
END
CREATE PROC GetFullCustomer
AS
BEGIN
SET NOCOUNT ON
SELECT Customer.ID, Fname, LName, Email,
A.ID AS Address_ID, A.Street, A.City, S.ID AS State_ID, S.Name AS State,
C.ID AS Country_ID, C.Name AS Country, A.PostalCode
FROM Customer
JOIN Address A ON A.ID = Address_ID
JOIN State S ON S.ID = A.State_ID
JOIN Country C ON C.ID = S.Country_ID
END
One difference between ADO.NET and the Entity Framework is the need to create your own entity objects to materilaize data for retrieval or insertion into the database. Here are a few simple POCO classes that have been created to facilitate this. Again, nothing elaborate, but a fair representation of a common business scenario.
public class Customer
{
public Customer(){ }
public Customer(int id, string fname, string lname,
Address address, string email)
{
ID = id;
FName = fname;
LName = lname;
Address = address;
Email = email;
}
public int ID { get; set; }
public string FName { get; set; }
public string LName { get; set; }
public Address Address { get; set; }
public string Email { get; set; }
public List<Phone> Phones { get; set; }
}
Since the ADO.NET tests are being used as the baseline for comparison, and because they use techniques that should be familiar to anyone who has used it to construct data access classes, we won’t spend much time on these methods. The full code is available in the download for review.
For the insert test, a collection of 1000 Customer objects is created, each with an Address and five PhoneNumber objects. The collection is iterated over and inserted into the database. Since Customer references Address, Address must be inserted first to obtain the foreign key. Customer is then inserted, followed by Phone, and finally, Customer_Phone is populated.
public void InsertCustomer(List<ADOTest.Customer> customers)
{
int addressID = 0;
int customerID = 0;
using(SqlConnection conn = new SqlConnection(ConnectionString))
{
using(SqlCommand cmd = new SqlCommand("InsertCustomer", conn))
using(SqlCommand cmdAddr = new SqlCommand("InsertAddress", conn))
using(SqlCommand cmdPhone = new SqlCommand("InsertPhone", conn))
using(SqlCommand cmdCustomerPhone = new SqlCommand("InsertCustomerPhone", conn))
{
cmd.CommandType = System.Data.CommandType.StoredProcedure;
cmd.Parameters.Add(new SqlParameter("@FName", System.Data.SqlDbType.NVarChar));
cmd.Parameters.Add(new SqlParameter("@LName", System.Data.SqlDbType.NVarChar));
cmd.Parameters.Add(new SqlParameter("@Address_ID", System.Data.SqlDbType.Int));
cmd.Parameters.Add(new SqlParameter("@Email", System.Data.SqlDbType.NVarChar));
cmd.Parameters.Add("@ReturnValue", System.Data.SqlDbType.Int).Direction = System.Data.ParameterDirection.ReturnValue;
cmdAddr.CommandType = System.Data.CommandType.StoredProcedure;
cmdAddr.Parameters.Add(new SqlParameter("@Street", System.Data.SqlDbType.NVarChar));
cmdAddr.Parameters.Add(new SqlParameter("@City", System.Data.SqlDbType.NVarChar));
cmdAddr.Parameters.Add(new SqlParameter("@State_ID", System.Data.SqlDbType.Int));
cmdAddr.Parameters.Add(new SqlParameter("@PostalCode", System.Data.SqlDbType.NVarChar));
cmdAddr.Parameters.Add("@ReturnValue", System.Data.SqlDbType.Int).Direction = System.Data.ParameterDirection.ReturnValue;
cmdPhone.CommandType = System.Data.CommandType.StoredProcedure;
cmdPhone.Parameters.Add(new SqlParameter("@Number", System.Data.SqlDbType.NVarChar));
cmdPhone.Parameters.Add(new SqlParameter("@Type_ID", System.Data.SqlDbType.Int));
cmdPhone.Parameters.Add("@ReturnValue", System.Data.SqlDbType.Int).Direction = System.Data.ParameterDirection.ReturnValue;
cmdCustomerPhone.CommandType = System.Data.CommandType.StoredProcedure;
cmdCustomerPhone.Parameters.Add(new SqlParameter("@Customer_ID", System.Data.SqlDbType.Int));
cmdCustomerPhone.Parameters.Add(new SqlParameter("@Phone_ID", System.Data.SqlDbType.Int));
foreach(var customer in customers)
{
if(conn.State != System.Data.ConnectionState.Open)
conn.Open();
addressID = InsertAddress(customer.Address, cmdAddr);
cmd.Parameters["@FName"].Value = customer.FName;
cmd.Parameters["@LName"].Value = customer.LName;
cmd.Parameters["@Address_ID"].Value = addressID;
cmd.Parameters["@Email"].Value = customer.Email;
cmd.ExecuteNonQuery();
customerID = (int)cmd.Parameters["@ReturnValue"].Value;
foreach(Phone phone in customer.Phones)
{
InsertCustomerPhone(customerID, phone, cmdPhone, cmdCustomerPhone);
}
}
}
}
}
For the retrieval test, the GetFullCustomer Stored Procedure shown above is executed and the returned SqlDataReader is iterated over and used to materialize the Customer objects.
public List<customer> GetAllCustomers()
{
List<customer> customers = new List<customer>();
using(SqlConnection conn = new SqlConnection(ConnectionString))
{
using(SqlCommand cmd = new SqlCommand("GetFullCustomer", conn))
using(SqlCommand cmd2 = new SqlCommand("GetPhonesForCustomer", conn))
{
cmd.CommandType = System.Data.CommandType.StoredProcedure;
cmd2.CommandType = System.Data.CommandType.StoredProcedure;
conn.Open();
SqlDataReader dr = cmd.ExecuteReader();
while(dr.Read())
{
Country country = new Country(dr.GetInt32(9), dr.GetString(10));
State state = new State(dr.GetInt32(7), dr.GetString(8), country);
Address addr = new Address(dr.GetInt32(4), dr.GetString(5), dr.GetString(6),
state, dr.GetString(11));
addr.ID = dr.GetInt32(4);
Customer customer = new Customer(dr.GetInt32(0),
dr.GetString(1), dr.GetString(2), addr, dr.GetString(3));
customer.Phones = new List<phone>();
cmd2.Parameters.AddWithValue("@CustomerID", customer.ID);
SqlDataReader dr2 = cmd2.ExecuteReader();
while(dr2.Read())
{
customer.Phones.Add(new Phone(dr2.GetInt32(0), dr2.GetString(1),
new PhoneType(dr2.GetInt32(2), dr2.GetString(3))));
}
cmd2.Parameters.Clear();
dr2.Close();
customers.Add(customer);
}
}
}
return customers;
}
ADO.NET Results
As you can see from these results, five iterations of the tests produce very consistent results. I’ll use these results as comparison for the Entity Framework tests to follow. Of course, these results will vary on different systems, and your results may not be the same.
| Insert
| Get
|
Test run 1
| 6.36829512
| 0.28734904
|
Test run 2
| 5.0966758
| 0.28829696
|
Test run 3
| 5.12760286
| 0.28650676
|
Test run 4
| 9.86927334
| 0.67176426
|
Test run 5
| 5.1557739
| 0.28186196
|
Entity Framework Tests
This article is not an in-depth coverage of the Entity Framework; there are many other resources available for that, so I would not delve too deeply into it. The objective is to make a comparison between ADO.NET and the methods available from the Entity Framework.
Rather than using the POCO objects created for the ADO.NET tests, Entity Framework maps the database schema, and produces the entity classes derived from System.Data.Objects.DataClasses.EntityObject, as shown below.

Entity Framework Insert and Retrieve Test 1
Entity Framework creates a class derived from System.Data.Objects, named Entities in this case. The ObjectContext class, among other things, maintains the connection to the database and ObjectStateManager, which is used to maintain the state and relationships between entities in the ObjectContext
The first insert method used with Entity Framework adds all of the customers to the ObjectContext via the AddToCustomer method, then inserts them into the database by calling the ObjectContext.SaveChanges method. SaveChanges will act on all entities that have been added or modified to the ObjectContext since it was last called. Since all Customer and related entities have been added prior to the call to SaveChanges, it will process all entities. When the SaveChanges method is called, the ObjectStateManager is used to determine the operation that needs to be performed, insert in this case. If any entities attached to the ObjectContext have been modified, an update would occur on those, likewise for deletes.
public void InsertCustomers_Batch(List<Customer> customers)
{
using(Entities context = new Entities())
{
foreach(Customer customer in customers)
{
context.AddToCustomer(customer);
}
context.SaveChanges();
}
}
The AddToCustomer method is a method added to the ObjectContext class generated by the Entity Framework designer, and wraps the ObjectContext.AddObject method for use, specifically with Customer entities.
public void AddToCustomer(Customer customer)
{
base.AddObject("Customer", customer);
}
Eventually, the ObjectContext.AddSingleObject method is called, and the entity is assigned an EnityKey and attached to the RelationshipManager and exposed via the ObjectStateManager in the ObjectContext class.
internal void AddSingleObject(EntitySet entitySet, object entity, string argumentName)
{
RelationshipManager relationshipManager = EntityUtil.GetRelationshipManager(entity);
EntityKey key = FindEntityKey(entity, this);
if (key != null)
{
EntityUtil.ValidateEntitySetInKey(key, entitySet);
key.ValidateEntityKey(entitySet);
}
this.ObjectStateManager.AddEntry(entity, null, entitySet, argumentName, true);
if (relationshipManager != null)
{
relationshipManager.AttachContext(this, entitySet, MergeOption.AppendOnly);
}
}
The RelationshipManager causes all associated entities to also be added to the ObjectContext session.
The ObjectContext.SaveChanges checks for an existing IEntityAdapter implementation, or creates one if not found, and calls its Update method. Using the SqlClient provider, the IEntityAdapter is, of course, implemented as a SqlDataAdapter.
public int SaveChanges(bool acceptChangesDuringSave)
{
if (this._adapter == null)
{
IServiceProvider providerFactory =
connection.ProviderFactory as IServiceProvider;
if (providerFactory != null)
{
this._adapter =
providerFactory.GetService(typeof(IEntityAdapter)) as IEnityAdapter;
}
if (this._adapter == null)
{
throw EntityUtil.InvalidDataAdapter();
}
}
try
{
objectStateEntriesCount = this._adapter.Update(this.ObjectStateManager);
}
When SaveChanges is called, the Entity Framework generates a SQL statement to perform the necessary operations: insert, update, delete. Using the SQL Profiler, we can see the SQL statement that was created for the AddToCustomer operation and will be executed.
You’ll notice here that the order for the insert statements is the Address rows, followed by the Phone rows, then the Customer rows, and finally the Customer_Phone rows, just as in the ADO.NET test above.
The AddObject and SaveChanges methods do not produce an ObjectQuery, so we cannot use the ToTraceString() method to view the SQL statements that will be executed. We can, however, use the SQL Profiler to see the statements that were executed when SaveChanges is called.
exec sp_executesql N'insert [dbo].[Address]([Street], [City], [State_ID],[PostalCode])
values(@0, @1, @2, @3)
select[ID] from [dbo].[Address]
where @@ROWCOUNT > 0 and [ID] = scope_identity()',N'@0 nvarchar(3),
@1 nvarchar(7),@2 int,@3 nvarchar(5)',@0=N'686',@1=N'Anytown',@2=1,@3=N'12345'
exec sp_executesql N'insert [dbo].[Phone]([Number], [Type_ID])
values(@0, @1)
select[ID]
from[dbo].[Phone]
where @@ROWCOUNT > 0 and [ID] = scope_identity()',N'@0 nvarchar(1),@1 int',@0=N'3',@1=1
exec sp_executesql N'insert [dbo].[Customer]([FName], [LName], [Address_ID],[email])
values(@0, @1, @2, @3)
select[ID]
from[dbo].[Customer]
where @@ROWCOUNT > 0 and [ID] = scope_identity()',N'@0 nvarchar(2),
@1 nvarchar(7),@2 int,@3 nvarchar(12)',@0=N'EF',@1=N'Doe1000',@2=1073064,
@3=N'john@doe.com'
exec sp_executesql N'insert [dbo].[Customer_Phone]([Customer_ID], [Phone_ID])
values(@0, @1)',N'@0 int,@1 int',@0=1084372,@1=7711908
It’s also interesting to note here that when processed in a batch mode, there appears to be no order to the inserts. Using ADO.NET or a single insert with Entity Framework, rows are inserted in a FIFO order from the collection. When processing Entity Framework batch inserts, however, they appear to be in random order. As can be seen from the code, the customer’s last name is appended with the index of the entity being created; the same number is used for the street property in the associated address.
for(int x = 0; x < NumCustomers; x++)
{
EFTest.Customer customer = EFTest.Customer.CreateCustomer(0, "EF",
"Doe" + (x + 1));
customer.email = "john@doe.com";
customer.Address = CreateAddress(x + 1);
CreatePhones(NumPhones, customer);
Customers.Add(customer);
}
private EFTest.Address CreateAddress(int x)
{
EFTest.Address addr = EFTest.Address.CreateAddress(0, x.ToString(),
"Anytown", "12345");
addr.StateReference.EntityKey =
new System.Data.EntityKey("Entities.State", "ID", 1);
return addr;
}
When inserted into the database, however, we can see that Customers seem to be added in LIFO order while Addresses are inserted in a somewhat random order.
Retrieving Entities
When retrieving entities from the data store using the Entity Framework, a System.Data.Objects.ObjectQuery is constructed. An ObjectQuery can be constructed in a variety of ways as we will see. The first test will use method notation. An ObjectQuery does not query the database immediately, and can be stored for future use. The database is queried when an action, such as ToList() in this case, is called.
Here, an instance of the ObjectContext for this model, Entities, is created, and used to form an ObjectQuery for the customer entities. The related entity associations are added using the LINQ to SQL Include method. The ObjectQuery is implicitly executed with the ToList() call, and the results are materialized into a collection of Customer entities.
public List<Customer> GetAllCustomers()
{
using(Entities context = new Entities())
{
List<Customer> customers = context.Customer
.Include("Address")
.Include("Address.State")
.Include("Address.State.Country")
.Include("Phone")
.Include("Phone.PhoneType")
.ToList();
return customers;
}
}
Just as with the AddToCustomer method, Entity Framework generates a SQL statement; however, it is easier to view the generated statement. The ToTraceString() method of the ObjectQuery can be called to view the generated SQL statement as in the below statement that was created from the ObjectQuery above.
SELECT
[Project2].[ID] AS [ID],
[Project2].[FName] AS [FName],
[Project2].[LName] AS [LName],
[Project2].[email] AS [email],
[Project2].[ID1] AS [ID1],
[Project2].[Street] AS [Street],
[Project2].[City] AS [City],
[Project2].[PostalCode] AS [PostalCode],
[Project2].[ID2] AS [ID2],
[Project2].[Name] AS [Name],
[Project2].[Abbr] AS [Abbr],
[Project2].[ID3] AS [ID3],
[Project2].[ID4] AS [ID4],
[Project2].[Name1] AS [Name1],
[Project2].[C1] AS [C1],
[Project2].[C2] AS [C2],
[Project2].[C3] AS [C3],
[Project2].[C4] AS [C4],
[Project2].[ID5] AS [ID5],
[Project2].[Number] AS [Number],
[Project2].[Type_ID] AS [Type_ID]
FROM ( SELECT
[Extent1].[ID] AS [ID],
[Extent1].[FName] AS [FName],
[Extent1].[LName] AS [LName],
[Extent1].[email] AS [email],
[Extent2].[ID] AS [ID1],
[Extent2].[Street] AS [Street],
[Extent2].[City] AS [City],
[Extent2].[PostalCode] AS [PostalCode],
[Extent3].[ID] AS [ID2],
[Extent3].[Name] AS [Name],
[Extent3].[Abbr] AS [Abbr],
[Extent4].[ID] AS [ID3],
[Extent5].[ID] AS [ID4],
[Extent5].[Name] AS [Name1],
1 AS [C1],
1 AS [C2],
1 AS [C3],
[Project1].[ID] AS [ID5],
[Project1].[Number] AS [Number],
[Project1].[Type_ID] AS [Type_ID],
[Project1].[C1] AS [C4]
FROM [dbo].[Customer] AS [Extent1]
LEFT OUTER JOIN [dbo].[Address] AS [Extent2] ON [Extent1].[Address_ID] = [Extent2].[ID]
LEFT OUTER JOIN [dbo].[State] AS [Extent3] ON [Extent2].[State_ID] = [Extent3].[ID]
LEFT OUTER JOIN [dbo].[State] AS [Extent4] ON [Extent2].[State_ID] = [Extent4].[ID]
LEFT OUTER JOIN [dbo].[Country] AS [Extent5] ON [Extent4].[Country_ID] = [Extent5].[ID]
LEFT OUTER JOIN (SELECT
[Extent6].[Customer_ID] AS [Customer_ID],
[Extent7].[ID] AS [ID],
[Extent7].[Number] AS [Number],
[Extent7].[Type_ID] AS [Type_ID],
1 AS [C1]
FROM [dbo].[Customer_Phone] AS [Extent6]
INNER JOIN [dbo].[Phone] AS [Extent7] ON [Extent7].[ID] = [Extent6].[Phone_ID] )
AS [Project1] ON [Extent1].[ID] = [Project1].[Customer_ID]
) AS [Project2]
ORDER BY [Project2].[ID] ASC, [Project2].[ID1] ASC, [Project2].[ID2] ASC,
[Project2].[ID3] ASC, [Project2].[ID4] ASC, [Project2].[C4] ASC
Results
The retrieval times are, on average, about three seconds greater using the Entity Framework. This difference can be explained when you understand that when Entity Framework is materializing the data retrieved from the database, it is also storing information in the ObjectStateManager used for maintaining state, which, of course, adds time to process.
Let’s see what can be done to improve these times.
Entity Framework Insert Test 2
Rather than adding all of the Customer and related entities to the ObjectContext and database at once, we can try adding them individually. This is similar to the ADO.NET method above.
public void InsertCustomers_Single(List<Customer> customers)
{
using(Entities context = new Entities())
{
foreach(Customer customer in customers)
{
context.AddToCustomer(customer);
context.SaveChanges();
}
}
}
Results
The results are closer to those from the ADO.NET insert test. The difference can be attributed to the Entities Framework generating the SQL statement and using the system Stored Procedure sp_executesql rather than using the ADO.NET method of calling a recompiled Stored Procedure.
Retrieving Entities with NoTracking
As was identified above, the state management features of Entity Framework does add time to the retrieval process. State management, however, is not necessary in all instances. For instance, when an entity is disconnected from an ObjectContext, as is the case when transporting it between layers in a multi-tiered application, all state information is lost. In this case, applying state management during materialization is not useful.
This can be controlled by setting the MergeOption on the ObjectQuery. The default setting is AppendOnly, which means that only new entities are added to the ObjectContext; any existing entities are not modified. By using MergeOptions.NoTracking, you can disable state management for the ObjectQuery.
public List<Customer> GetAllCustomers_NoTracking()
{
using(Entities context = new Entities())
{
var customers = context.Customer
.Include("Address")
.Include("Address.State")
.Include("Address.State.Country")
.Include("Phone")
.Include("Phone.PhoneType");
customers.MergeOption = MergeOption.NoTracking;
return customers.ToList();
}
}
Results
We can see here that state management adds a considerable amount of time to the execution of the ObjectQuery. Without tracking, the times are closer to those for the ADO.NTET test, which is as expected since ADO.NET does not incorporate state management either.
Retrieving Entities with CompiledQuery
One of the benefits of using Stored Procedures is that they can be precompiled rather than compiled each time, reducing the time needed for execution. Similar to what happens when code is JITed when run the first time, Entity Framework can use a CompledQuery. As the name and JIT reference implies, the CompileQuery is compiled the first time it is executed, and then reused for subsequent executions as long as it remains in scope.
Here, an ObjectQuery is constructed using Entity Expression syntax to perform the same query as the previous test.
public static Func<Entities, IQueryable<Customer>> compiledQuery =
CompiledQuery.Compile((Entities ctx) => from c in ctx.Customer
.Include("Address")
.Include("Address.State")
.Include("Address.State.Country")
.Include("Phone")
.Include("Phone.PhoneType")
select c);
public List<Customer> GetAllCustomers_Compiled()
{
using(Entities context = new Entities())
{
return compiledQuery.Invoke(context).ToList();
}
}
Results
The first set of results shows the time for running the above test using an empty database, i.e., no inserts have been performed. You can easily see the time for the query to be compiled and then executed the first time, and the reduction in time for subsequent executions.
| Empty data – Compile Query |
| Test run 1 | 0.06587061 |
| Test run 2 | 0.00436616 |
| Test run 3 | 0.00411366 |
| Test run 4 | 0.00692281 |
| Test run 5 | 0.00413088 |
In a practical application, we can also see the time reduction from the first time compilation of the query and subsequent calls.
| | EF Gets Compiled |
| Iteration 1 | 3.4879755 |
| Iteration 2 | 3.0695143 |
| Iteration 3 | 2.7637209 |
| Iteration 4 | 2.6596132 |
| Iteration 5 | 2.695845 |
However, when looking at the overall average, there is very little difference compared with the non-compiled queries, which is a bit misleading.
| EF Gets | EF Gets Compiled |
| Test run 1 | 3.1006031 | 2.92106378 |
| Test run 2 | 2.5866506 | 2.547442 |
| Test run 3 | 2.6016029 | 2.5337393 |
| Test run 4 | 2.68804502 | 2.62037566 |
| Test run 5 | 2.5479289 | 2.50857524 |
Retrieving Entities with CompiledQuery and NoTracking
Both of the above methods, CompiledQuery and NoTracking, can be combined.
public List<Customer> GetAllCustomers_CompiledNoTracking()
{
using(Entities context = new Entities())
{
var query = compiledQuery(context);
((ObjectQuery)query).MergeOption = MergeOption.NoTracking;
return query.ToList();
}
}
Results
| EF Gets Compiled NoTracking |
| Test run 1 | 2.00207252 |
| Test run 2 | 1.90965804 |
| Test run 3 | 1.87372962 |
| Test run 4 | 1.90671946 |
| Test run 5 | 1.88587232 |
Points of Interest
The first version of this code was run using .NET Framework 3.5 SP1 and didn't show much of a difference between compiled and non-compiled queries. However, when updating I used .NET Framework 4.0 and found very good improvements.
The results from running the tests on the server were also higher than expected, but could possibly be attributed to a low end server. Of course, results may vary with better hardware.
Conclusion
Again, the results from these tests will vary based on the hardware, environment, and other factors, and are not meant to be definitive, only informative.
History
10/31/2009 - Initial posting
10/25/11 - Correct code in GetAllCustomers to remove unnecessary looping
Correct code in InsertCustomer to not skew results from creating SqlParameters

