Introduction
This is the third article on an Introduction to Distributed System Design (ITDSD). This article briefly introduces the basic concepts, history and current situation of distributed engineering in theory, as well as its future development direction. Let us understand why we learn Distributed Engineering, the status of distributed engineering in computer science and the problems to be solved in distributed engineering. You can click on the links below to find the first three articles:
History
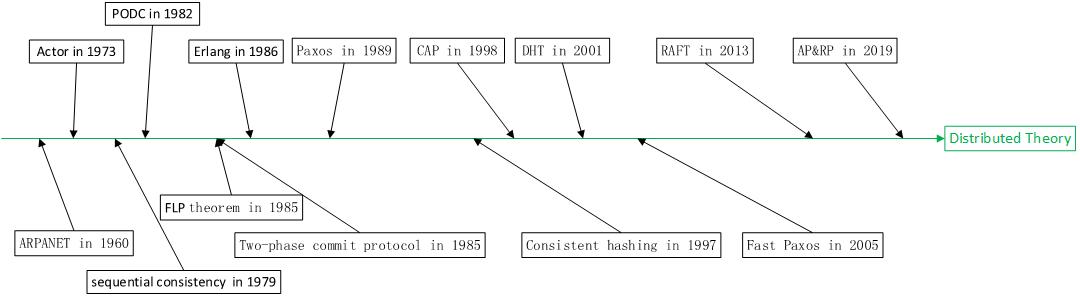
Distributed engineering is a practical engineering science. So there will be the same phenomenon as other engineering projects, that is, practice will take precedence over theory. ARPANET [1], which was recognized as the first distributed system at the end of 1960, was born in the United States. From the 1950s to the 1960s, influenced by the Manhattan Project, computer theory ushered in the era of the Big Bang. In that era, most of the computer theories we use today were invented. As a new subject, most of the scientists in that year were just graduated and were in their prime. Today, most of them are old people, and some scientists have died. Here, we pay tribute to those scientists who have contributed to computer theory.
Carl Hewitt invented the actor model in 1973 [2]. This model attempts to establish virtual objects corresponding to reality in the computer network and establish relationships between them. The virtual objects in the computer network are responsible for processing the requests generated by the real scene. The actor model has a far-reaching impact on object-oriented and object-oriented databases in later languages. It is an important theoretical basis for dividing computer software modules according to product functions.
In 1979, Lamport put forward the theory of sequential consistency [3]. Consistency theory was first used in system design. It mainly plays a role in hardware and computer system. During this period, scientists tried to find a way to maintain data consistency in multiple hardware, so a variety of consistency theories were born.
Symposium on Principles of Distributed Computing (PODC) was officially established in 1982 [4]. This indicates that distributed technology has become an independent research direction.
In 1985, three scientists Fischer, Lynch and Paterson published FLP theorem [5]. It proves that it is impossible to reach an absolute consensus using asynchronous communication. But then in 1988, Lynch, Dwork and Stockmeyer published a paper entitled "Consensus in the Presence of Partial Synchrony" [6]. This makes people confused about the reliability and stability of distributed systems. If the distributed system is an unstable system, then the software system built on it is also an unstable system. Finding an algorithm to stabilize the distributed system has become a new problem. Considering the background of hardware explosion development at that time. The instability of the hardware system has really put scientists on the nerves.
In 1985, the two-stage submission protocol [7] was invented by Mohan, Bruce Lindsay. This is the earliest known protocol that uses voting to maintain consistency in distributed systems.
In 1986, an important industrial practice in distributed engineering was initiated, which was the birth of Erlang language [8]. Obviously, Ericsson can't wait for scientists to debate whether the distributed system is stable. A large number of telephone exchanges all over the world are in urgent need of a large distributed system for processing. It was developed by Joe Armstrong, Robert Virding, and Mike Williams. Joe Armstrong died last month, April 20, 2019, to pay my respects.
In 1989, Lamport proposed the controversial Paxos protocol [9]. Named after the fictional legislative system used on the Greek island of Paxos. The paper was rejected because it was more like a story. It was not until 1998 that the paper was officially published.
The term consistency hash [10] was first used in Karger's paper published in 1997. Although Teradata has used this technology in distributed data developed in 1986.
In 1998, Eric Brewer proposed the CAP theorem to describe the relationship between consistency and availability and partitioning [11]. But in his article [12], he tries to describe it as a software design criterion. And there seems to be no operational way to implement this principle.
In 2001, DHT technology driven by P2P software such as Freenet, gnutella, BitTorrent and Napster was widely used [13]. It originally came from papers that Ian Clarke did not publish in any Journal [14]. DHT technology plays an important role in P2P and distributed memory database.
Lambert's improved Paxos algorithm fast Paxos was invented in 2005. This is the first time that Paxos algorithm has been used as a version of application code.
In 2013, RAFT algorithm was invented with reference to Paxos algorithm [15]. Before 2011, a ZAB algorithm similar to RAFT algorithm was published. ZAB algorithm is used in ZooKeeper. ZooKeeper is a node used to provide system configuration information in distributed systems. Because ZooKeeper is widely used in distributed systems. So RAFT algorithm has become popular.
In 2019, I invented the AP&RP method to solve the problem of boundary demarcation of multitasking systems. The paper [16] was published in April.
Distributed database has a tortuous history. Here, we will focus on [17]. In the early 1960s, DBMS was a hard disk-based key-value database. And this database quickly evolved a distributed architecture. After the rise of relational DBMS in 1970, database technology has changed from distributed architecture to centralized architecture [18]. During this period, there is a deep relationship with the rapid development of hardware. After 2000, with the beginning of NOSQL movement, database began to develop into key-value distributed system.
In 1999, Google Inc. Engineers such as Sanjay Ghemawat [19] and Jeff Dean [20] have promoted a series of distributed engineering practices. Including MapReduce, Google File System, Bigtable, etc. It directly promotes the industrialization of distributed technologies such as big data, memory database and micro services. It has made great contributions to the industrialization of distributed engineering.
Distributed Problems to Be Solved
We can see that there are many problems in distributed research. What is the core issue of distributed engineering? I agree with the statement in Borowsky, Elizabeth, Gafni, Eli's paper [21] in 1993, ”Demarcation of the border between solvable and unsolvable distributed tasks under various models is the holy grail of the theory of distributed computing.”
That is to say, the core problem to be solved in distributed Software Engineering is: can any software system be distributed, how to distribute and distribute the results? There is no answer to this question before this article. That is to say, distributed is only a research direction before that. In the past, there was no known way to solve the core problem of distributed engineering. Only the methodology to solve the core problem is given in this paper. Distribution has changed from a research direction to a engineering.
The answer is whether any software system can be distributed, how to distribute and distribute the results. First of all, software systems should be classified. We classify software systems into four categories. They are Single-Sask-Computing, Multitask-Computing, Single-Task-Computing&Sharing-Data-Sets, Multitask-Computing&sharing-Data-Sets. This classification involves three concepts. The first task is the program logic expressed in discrete mathematics. It consists of one or more steps of calculation process. Computing means that the calculation unit completes the operation of program logic. Shared data sets refer to the data generated after each task is completed, whether it is reserved for the next execution or other tasks to use together. For these four situations, we analyse as follows.
- Single-Task-Computing. It's easiest to understand, for example, the calculation of generating π. Whether this algorithm can be distributed is a mathematical concept. It is known that only a few mathematical algorithms can be further refined into distributed ones.
- Multitask-Computing. It can be understood as the simultaneous execution of multiple mathematical algorithms. That is, we traditionally separate computer processes from each other. This completely isolated computer process can be distributed. For example, a computer system on two hardware can be understood as a generalized distributed system.
- Single-Task-Computing&Sharing-Data-Sets. This is more common in integrated circuits or controllers. For example, vehicle speed sensors collect speed data and use speed data to modify the display screen. This situation cannot be further refined into distributed. But broadly speaking, this situation is the same as the second one. It can also be considered as a generalized distributed system for scenarios where multiple Single-Task-Computing&Sharing-Data-Sets work together.
- For the last case, Multitasking-Computing&Sharing-Data-Sets is what we often call software systems in asynchronous networks. Using AP&RP method, we can clearly point out whether this situation can be distributed, how to distribute and how to distribute the results. The actor model is also the object-oriented model or the method of product function partition. They do not have the ability to judge whether they can be distributed or not. Different partitioning schemes need to be constantly tried to determine whether they will lead to data conflicts. Until a partitioning scheme with fewer errors is found, it is also impossible to give distributed results. The same consistency hash table does not give any answers. Consistency hashing usually uses the maximum redundancy method to attempt to cover all possible segmentation results.
So far we know that class 1 and 3 of any given software system cannot be distributed or can be distributed in a few specific cases. The second category is naturally distributed architecture. Finally, the fourth class can solve the distributed problem by AP&RP. At this point, we give the methodology to solve the core problem.
Stability in Distributed Systems
The stability of distributed systems is often referred to as availability. FLP theorem first points out that distributed system is a very unstable system. This includes the famous Halting problem [22] which has been plaguing scientists.
Through further observation, which is divided into hardware and software problems, here we first from the hardware point of view. Whether the hardware is stable or not follows another rule: the bathtub curve [23]. Every hardware has a process from instability to stability to aging. Suppose there are n hardware components in a distributed system. The average damage probability of each hardware is x, which is determined by the basic probability formula. The probability of damage to any server in the cluster is x1*x2*x3…*xn. So we get Theorem 1.
Theorem 1. The Overall Instability Of Distributed Systems Increases With the Increase of Hardware.
That is to say, the probability of damage increases with the increase of distributed cluster. From another point of view, with the increase of distributed cluster, any hardware damage will lead to the reduction of the total damaged area of the cluster, that is, the damaged area of the cluster will be reduced to 1/n. So we get Theorem 2.
Theorem 2. The Damage Area of Distributed System Decreases With the Increase of Hardware.
So don't worry about distributed cluster stability anymore! And why instability has increased. Because they translate into a reduction in the damaged area. So what we need to do is to reduce the Sequential dependency in the cluster, that is, irreplaceable hierarchical relationships. Avoid any single point of service stopping leading to further expansion of the damaged area. Interestingly, it is very similar to the modern management system of enterprises. So we get Theorem 3.
Theorem 3. Hierarchical Relations and Their Irreplaceability Expand the Damage Area.
Software and hardware problems are very similar. In order to improve the reusability of code, software introduces a lot of hierarchical relationships in software engineering. This hierarchical relationship is also projected into the distributed system along with the distribution of software. The same hardware distribution rules apply to software. So we can get the theorem that distributed systems are damaged.
Theorem 4: The Hierarchical Relationship of Any Single Point in a Distributed System, Irreplaceability and Ultimately Affected Area Determine the Damaged Area.
In order to reduce any single point of damage in distributed systems, more damage is caused. We need to reduce the hierarchical relationships in distributed systems and the irreplaceability of any single point. But we know that system services that receive messages cannot be replaced. Otherwise, new atomic relations will be created. That is to say, different processing results from receiving two identical messages will not be reconciled in the system. So the smallest damage area is the same as the smallest service unit that receives messages in the distributed system.
Consistency in Distributed Systems
FLP theorem has proved that there is no absolute consistency in the distributed. I think this is a simple inference based on the conservation of energy. That is, the dissemination of information has direction and energy consumption. Information transmission from any source to any destination requires energy consumption and abides by the law of conservation of energy. Therefore, the time of information dissemination cannot be zero. So the description of this propagation process includes sequence consistency and consistency based on time t [24]. They all describe the same situation. Based on the simple probability principle, the less hardware involved in this propagation, the less energy and the less time, the lower the probability of damage. On the contrary, the more unreliable it is, that is, inconsistency is prone to occur. That is to say, there is no absolute consistency in terms of energy conservation. The evaluation of consistency in any system is based on the comparison results in its coordinate system. For example, WAN is more unstable than LAN, and LAN is more unstable than hardware. Therefore, it is more meaningful to establish a distributed accuracy evaluation system.
Conclusion
Distributed engineering in computer theory is a very young subject. As Moore's Law enters the deceleration period, the development of hardware slows down. As well as the outbreak of the Internet industry, software systems are becoming more and more complex. Distributed engineering ushered in a rare historical opportunity. At present, due to the confusion between product logic and distributed architecture of software system, the cost of software system development, secondary development and maintenance is very high. Enterprises need to employ a large number of developers to maintain control over software systems. I estimate that with the decoupling of product logic and architecture, the development workload will initially be reduced by about half. And greatly reduce the workload and maintenance costs of secondary development. Generally speaking, the development cost of enterprises can be reduced by about 95% compared with that of now. This will greatly reduce the threshold for traditional enterprises to enter the Internet, and release a large number of developers from the heavy maintenance work. It can be predicted that in the near future, the Internet industry will once again usher in an explosive period. A large number of tools have been developed for the development of distributed software. And the real distributed operating system came into being. Distributed engineering is still very weak at present. There are eight universities in mainland China that are still doing distributed research. With the development of distributed engineering practicality. The popularization and standardization of distributed technology still need a lot of work. I hope to see more scholars, more developers, more companies and organizations invest in distributed engineering.
References
- https://en.wikipedia.org/wiki/Distributed_computing
- https://en.wikipedia.org/wiki/Actor_model
- https://en.wikipedia.org/wiki/Consistency_model#Sequential_consistency
- https://dl.acm.org/citation.cfm?id=800220&picked=prox
- https://en.wikipedia.org/wiki/Dijkstra_Prize
- Dwork, Cynthia; Lynch, Nancy; Stockmeyer, Larry (April 1988). "Consensus in the Presence of Partial Synchrony" (PDF). Journal of the ACM. 35 (2): 288–323. CiteSeerX 10.1.1.13.3423. doi:10.1145/42282.42283.
- C. Mohan, Bruce Lindsay (1985): "Efficient commit protocols for the tree of processes model of distributed transactions",ACM SIGOPS Operating Systems Review, 19(2),pp. 40-52 (April 1985)
- https://en.wikipedia.org/wiki/Erlang_(programming_language)
- https://en.wikipedia.org/wiki/Paxos_(computer_science)
- https://en.wikipedia.org/wiki/Consistent_hashing
- https://en.wikipedia.org/wiki/CAP_theorem
- https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
- https://en.wikipedia.org/wiki/Distributed_hash_tabl
- Ian Clarke. A distributed decentralised information storage and retrieval system. Unpublished report, Division of Informatics, University of Edinburgh, 1999.
- https://en.wikipedia.org/wiki/Raft_(computer_science)
- Sun shuo.”Distributed Method of Web Services”. https://www.codeproject.com/Articles/3335097/Distributed-Method-of-Web-Services
- https://en.wikipedia.org/wiki/Database
- R.A. Davenport. Distributed database technology−asurvey. Computer Networks, 2(3):155–167, 1978.
- https://en.wikipedia.org/wiki/Sanjay_Ghemawat
- https://en.wikipedia.org/wiki/Jeff_Dean_(computer_scientist)
- Borowsky, Elizabeth; Gafni, Eli (1993). "Generalized FLP impossibility result for t-resilient asynchronous computations". P 25th Annual ACM Symposium on Theory of Computing. ACM. pp. 91–100.
- https://en.wikipedia.org/wiki/Halting_problem
- https://en.wikipedia.org/wiki/Bathtub_curve
- Seth Gilbert, Nancy Lynch. "Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services". ACM SIGACT News, v.33 n.2, June 2002 [doi>10.1145/564585.564601]

