The Problem
It is often a requirement to allow users to load information from Excel: users love Excel. However the problem comes with allowing a certain amount of flexibility: where in the spreadsheet will the information be and what happens if the user rearranges the columns?
Also there is the problem of validating values, and providing feedback to the user on where there are errors/issues. You can display a dialog that shows where there are issues that causes the operation to be canceled, but then the user has to figure out where to fix the problem.
One can be a Nazi about it and require columns to be fixed, but that limits the ability to organize data in a way that is easier to use. The user may also be using the spreadsheet to hold information besides what will be uploaded, so it is nice not to require the header row to be in the first row of the first column. There could also be columns that not all users have a reason to use, and if the user deletes the column, maybe he should be allowed to.
Overview
The program is implemented as an Excel add-in project. I tried to create a flexible environment for the user. I also stressed flexibility in implementation so that it will be easy for somebody else to take the code. A header row is almost a necessity for usability since otherwise the user will not know where to put his data, so this is one limitation I did put on the user. In my case I am requiring:
- A specific header text for each column.
- The header row is a single row.
- The data be a contiguous set of rows right below the header row.
- The searched for header to determine the header row must be in a column/row in which column + row < 100.
- All the headers must be within the first 100 columns.
- There cannot be a cell with the contents equal to the searched for header (the first header text in the list) before the cell that contains the header text in the Excel sheet.
- To end a scan, all cells be empty or invalid.
These requirements could be easily changed, but there is obviously a need for some sort of limitations.
The first thing that is required is to find a cell that contains the string that is the header text for one of the columns. For this I created a method that scans cells from the upper left corner, doing a diagonal scan:
public static bool ScanForText(Worksheet worksheet, object search,
out int columnIndex, out int rowIndex)
{
string searchText = search.ToString().ToLower();
for (int i = 1; i <= 100; i++)
{
for (rowIndex = 1, columnIndex = i; rowIndex <= i; rowIndex++, columnIndex--)
if (worksheet.Cells[rowIndex, columnIndex].Value != null &&
worksheet.Cells[rowIndex, columnIndex].Value.ToString().
ToLower() == searchText) return true;
}
columnIndex = -1; rowIndex = -1;
return false;
}
Notice that I have put a limit of the sum of the row and columns for the search must be less than 100, which seemed reasonable to me, but can be easily changed. Calling this method is fairly straightforward, and simply checking the return flag from this method determines the result of the search. If the header text is not found, then I just display a message box and return.
The Worksheet Reader
The Worksheet Reader (WorksheetReader) class is a generic class that is responsible for finding the header row, reading and validating the data, and then transferring to a collection of concrete class with the properties the same as the column headers. The constructor has an Excel Worksheet argument, which it saves, and also sets up the collection of Header objects (HeaderTextColumn class) that associate an Excel row with a header text in the list. The other argument is the information about the columns that are to be read, including the header title, validation, which consists of an enumeration of ValueValidator. This enumeration is used to generate the HeaderTextColumn collection, and, later provides the validators for the dictionary used by the RowValidator.
public WorksheetReader(Excel.Worksheet worksheet)
{
_worksheet = worksheet;
_headerColumns = valueValidators.Select
(i => new HeaderTextColumn(i.HeaderText, i.Required)).ToArray();
_valueValidators = valueValidators;
}
There is an instance of the HeaderTextColumn class for each field (“Header”). Since it uses the same collection as used to generate ValueValidator instances, there is only one place required for adding a field (of course, we still need a class that actually implements the properties for finally saving the data {the Model}). The HeaderTextColumn contains three properties:
- A property for the header string.
- A property for the column containing the header text.
- A property for a flag that indicates if the header is required to continue processing.
After finding the row containing the headers, the next task is finding the column for each header text. Again I limit the search to 100, but in this case it is 100 columns. In this case I use a method associated with the WorksheetReader class to do the scan, passing the row to search. The method contains a simple search:
private bool ScanForHeaders(int rowIndex)
{
int counter = 0;
for (var columnIndex = 1; columnIndex < 100; columnIndex++)
{
if (_worksheet.Cells[rowIndex, columnIndex].Value != null)
{
Excel.Range cell = _worksheet.Cells[rowIndex, columnIndex];
string cellText = cell.Value.ToString().ToLower();
var headerColumn = _headerColumns.FirstOrDefault
(i => i.CellText.ToLower() == cellText);
if (headerColumn != null)
{
headerColumn.SetColumn(cell);
if (_headerColumns.Count() == ++counter) break;
}
}
}
return _headerColumns.All(i => !i.Required || i.ColumnIndex > 0);
}
You will notice that I check to see if all columns have been found, and stop the search once that occurs. Also the return checks if all required columns have been found.
The return value allows it to be determined if all required headers have been associated with a column. To help in displaying an error to the user, there is another method in WorksheetReader that formats an error message that contains a list of missing headers:
private string HeadersErrorMessage()
{
IEnumerable<string> names = _headerColumns.Where(
i => i.Required && i.ColumnIndex == 0).Select(i => i.CellText);
return string.Format(
"The following required headers are missing from the header row:{0} {1}.",
Environment.NewLine, string.Join(", ", names));
}
The following shows the error message being displayed when a required header is missing:
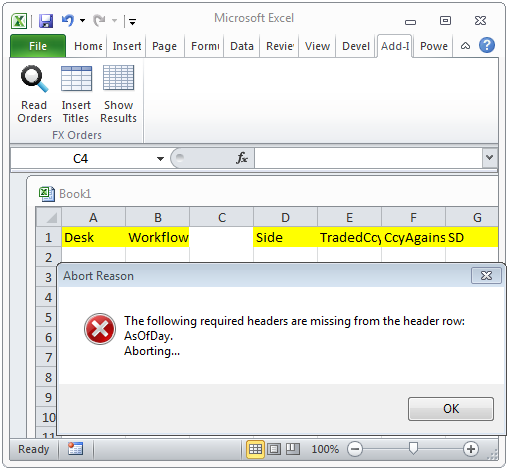
Now that we have the row that contains the headers, and the columns for each header, it is possible to start reading each subsequent row. This is also accomplished by a static method:
private bool GetSingleItem(int rowIndex, out RowValidator validator)
{
validator = new RowValidator();
bool isNotEndingRow = false;
foreach (HeaderTextColumn headerColumn in _headerColumns)
{
int columnIndex = headerColumn.ColumnIndex;
if (columnIndex > 0)
isNotEndingRow |= headerColumn.UpdateFromCell(validator,
_worksheet.Cells[rowIndex, columnIndex]);
}
return isNotEndingRow;
}
The return is either an instance of a RowValidator class or null. A null will be returned whenever not a single valid value is found in any of the columns associated with the headers. Thus a blank row will ensure that a null will be returned, which will halt the loading of rows.
This is called by the GetItems method, which reads all the data rows, and stopping the process once a row is found that does not seem to be a data row:
private bool GetItems(int rowTitleIndex)
{
_validators = new List<RowValidator>();
do
{
RowValidator validator;
if (GetSingleItem(++rowTitleIndex, out validator))
_validators.Add(validator);
else
break;
} while (true);
foreach (var validator in Validators)
validator.MarkErrors();
return _validators.Any(i => i.IsValid);
}
It also is responsible for going through all the validators and calling the MarkErrors method after the reading is complete, and for returning a Boolean false if no data records were found.
If no valid records are found, processing is halted at this point with a message box:

There is one important method in the HeaderColumn class, UpdateFromCell. The UpdateFromCell method updates the instance of RowValidator (the validator associated with the column header) passed as an argument with the value from the cell.
public bool UpdateFromCell(RowValidator record, Excel.Range cell)
{
try
{
record.SetValue(CellText, cell);
return null != cell.Value;
}
catch (ValidatorException)
{
return false;
}
}
The RowValidator instance has a SetValue (and GetValue) method that will update the value associated with the specified header text. This SetValue method is used in a try/catch block because the SetValue method is responsible for validating the value. If the value does not validate, the RowValidator will throw a ValidatorException. This allows the UpdateFromCell to return a value indicating if the value is good.
The SetValue in the Validator calls the Validate method of the ValueValidator class to save the value, and validate; if there is a problem with the validation, it will throw a ValidatorException to indicate that the row has an invalid value.
public void SetValue(string headerText, Excel.Range cell)
{
ValueValidator foundValidator = _validators[headerText];
foundValidator.Validate(cell);
}
The Start method of the WorksheetReader is called to initiate the reading, calling each of the methods above in order, checking that the operation was successful, displaying a message on errors and aborting, or continuing the processing if the operation was successful:
public void Start()
{
int rowTitleIndex;
int columnIndex;
string searchText = _headerColumns.Select(i => i.CellText).First();
if (!ExcelHelper.ScanForText(_worksheet, searchText, out columnIndex,
out rowTitleIndex))
MessageBox.Show(string.Format(
"Did not find a the header row.{0}(Searching for cell " +
"containing '{1}'){0}Aborting...",
Environment.NewLine, searchText), "Abort Reason",
MessageBoxButtons.OK, MessageBoxIcon.Error);
else if (!ScanForHeaders(rowTitleIndex))
MessageBox.Show(HeadersErrorMessage() + Environment.NewLine + "Aborting...",
"Abort Reason", MessageBoxButtons.OK, MessageBoxIcon.Error);
else if (!GetItems(rowTitleIndex))
MessageBox.Show(string.Format(
"Did not find any valid records during scan.{0}Aborting...",
Environment.NewLine), "Abort Reason", MessageBoxButtons.OK,
MessageBoxIcon.Error);
else if (typeof(T) == typeof(object))
return;
else if (!ReportResults())
return;
else
Transfer();
}
The Validator
The Validator is used to validate and store the values of a single record or row, which can have numerous values, each associated with a header. The heart of the RowValidator is the ValueValidator collection. This list is provided as an argument in the constructor, and is used to generate the Dictionary used for saving and validating the data.
public RowValidator(IEnumerable<ValueValidator> validators)
{
foreach (var validator in validators)
{
_validators.Add(validator.HeaderText, validator);
}
The importance of this collection can be easily seen in that it is the only variable associated with the RowValidator. What is critical to understand is that this collection is not a simple collection because a new ValueValidator instance must be generated for each row for each RowValidator. If a simple collection was passed, then each RowValidator would be using the same instance of each ValueValidator associated with a particular column. What is passed is a generator that generates new instances of a ValueValidator each time the iterator is executed using yield return. To add a property to the collection, a line of code in the iterator would look something like the following:
yield return new ValueValidator("Desk", value =>
StaticValidators.Concatenate(
() => StaticValidators.IsNotNullOrEmpty(value),
() => StaticValidators.ToUpper(ref value),
() => StaticValidators.IsOneOf(value, "NBEM")),
true);
Using yield return I think yields a cleaner solution than using the ValueValidator constructor in the RowValidator class, or someplace else. Very seldom have I used yield return, but this is definitely an instance that I think the value of the yield return shines in a new way.
The constructor for the ValueValidator is:
public ValueValidator(string headerText, Func< apper, string> validator,
bool required)
{
_validator = validator;
HeaderText = headerText;
Required = required;
Validate(null, false);
}
Notice that the validator argument is of type Func<StringWapper, string>. The StringWapper just wraps a string in a class. This is because string is immutable, and I will want to be able to update the string. Later I will cover samples of validators that update the Value.
public class StringWrapper
{
public string Value { get; set; }
public StringWrapper(string value) { Value = value; }
public static implicit operator string(StringWrapper value)
{
return value.Value;
}
public int Length { get { return Value.Length; } }
public override string ToString() { return Value; }
}
You will note that I added a little bit of extra functionality so that I would not always have to specify the Value property when using the StringWrapper class. Unfortunately, whenever there is an assignment to the Value property, we need to specify the property.
The validation methods are contained in a separate static class named StaticValidators. The Concatenate method in the command above is one of the critical methods in this class. It is used to concatenate a series of tests on a value when it is set:
public static string Concatenate(params Func<string>[] tests)
{
return tests.Select(test => test.Invoke()).
FirstOrDefault(result => result != null);
}
This function allows any number of tests to be run, going through its arguments, running the test specified in each argument, and going on to the next test if the test returns a null. A sample of a test method is as follows:
public static string IsOneOf( apper value, params string[] values)
{
Contract.Assert(values != null && values.All(i => i != null),
"One of the values is null");
if (values.Any(i => i == value)) return null;
return String.Format("{{0}} must be one of the following values: {0}",
String.Join(", ", values));
}
You will notice “{{0}}” in the String.Format call. Currently the ValueValidator Validate method will insert the header title into the returned error message.
A number of tests have already been created in this application, and it is quite easy to add more. These methods are currently contained as static methods within the StaticValidators class.
To show the flexibility of this approach, it is also possible to include a substitute method:
public static string Substitute( apper value, string returnValue,
params string[] possibleValues)
{
var savedValue = value;
if (possibleValues.Any(i => i == savedValue))
{
value.Value = returnValue;
}
return null;
}
This method will replace the value with another value if there is a match in the parameters. I also use a method extensively that will force the value to be upper case:
public static string ToUpper(ref string value)
{
value.Value = value.Value == null ? null : value.Value.ToUpper();
return null;
}
The only other important methods in the Validator are GetValue and SetValue. The implementation is straightforward. I just added a Contract.Assert to both to catch any issues with keys not being in the dictionary. A third method just goes through the collection of ValueValidator instances, and checks that all are valid using LINQ:
public bool IsValid
{
get { return _validators.All(i => i.Value.IsValid); }
}
There are also a couple of methods for formatting the cells to indicate to the user the issues with the row values using the ValueValidator instances to actually change to cell formatting. The second method clears the formatting changes.
To keep things together, I have put the code to generate the collection of ValueValidator instances in the same class that is used to ultimately save the values from the Validator instances in a form that has concrete properties.
The Value Validator
The value validator is a class that is used to contain the detailed information about a cell and its value. It also contains the code that actually initiates the validation, and throws the exception if there is an error that will contain the error message:
public void Validate(Excel.Range cell, bool throwException = true)
{
_errorMessage = null;
_cell = cell;
Value = cell == null ? string.Empty : cell.Value == null ?
string.Empty : cell.Value.ToString();
IsValid = true;
var validateReturn = new apper(Value);
_errorMessage = _validator(validateReturn);
Value = validateReturn.Value;
if (!string.IsNullOrEmpty(_errorMessage))
{
_errorMessage = string.Format(_errorMessage, HeaderText);
IsValid = false;
if (throwException)
throw new ValidatorException(_errorMessage);
}
}
As can be seen, this method has a lot of responsibilities: it has to save the value, validate the value, save the cell, and the error message for marking the cell so the user can see that the value has a problem, and throw the exception required by the argument throwException.
As with the RowValidator, there are also a couple of methods for formatting the cells to indicate to the user the issues with the row values using the ValueValidator and to clear the formatting.
Formatting Excel UI
As currently implemented, the cell containing a header is given a yellow background to indicate the headers that were found. If there is an error in the cell of a data row, then the cell is given a red border, and a comment with the error message is added to the cell.
The cells are not formatted to show issues until the reading of the worksheet is completed. ValueValidator is ultimately responsible for initiating the formatting:
public void MarkErrors()
{
if (!IsValid)
_savedCellFormating = ExcelHelper.AddErrorComment(_cell, _errorMessage);
}
The MarkErrors method in the ValueValidator class is called by MarkErrors in the AbstractVailidator class:
public void MarkErrors()
{
foreach (var validator in _validators)
validator.Value.MarkErrors();
}
This is called by the GetItems method of the WorksheetReader class after completion of the reading of records (this will also make it easy to use a BackgroundWorker).
There is also a RestoreFormatting method in the ValueValidator that uses information saved in a class during the MarkErrors execution to restore cell properties to formats before the MarkErrors methods are executed. The methods are called on each Validator when the WorksheetReader class is disposed of:
public void Dispose()
{
if (_validators != null)
{
var validators = _validators.ToArray();
for (int i = _validators.Count - 1; i > -1; i--)
validators[i].RestoreFormatting();
}
if (_headerColumns != null)
foreach (var headerColumn in _headerColumns)
headerColumn.RestoreFormatting ();
}
The calling of the RestoreFormatting has to be done in the reverse order of the MarkErrors to ensure that formatting changes done during MarkErrors are undone in the same order since there could be shared borders. That is why the validators are saved in an array and a for loop is used instead of a foreach loop. The destructor is responsible for reversing the rows, and the Validator code is responsible for reversing the columns. The ValueValidator actually calls the helper method that does the restore. Obviously we have to ensure that the WorksheetReader is disposed of to ensure that the restore is done. In the code the dispose is called before a new instance of the WorksheetReader is initialized. Since a new instance of the WorksheetReader is created each time, in the implementation of the Dispose method to clean up the formatting of the Excel worksheet, this cleanup works perfectly. If an attempt was made to use the same instance, and not reset all formatting, there would be a great deal of increased complexity to deal with errors in contiguous cells which are identified by the border changing color.
Transfer of Data from Validator
The final step is to transfer to an object, if that is desired. This object must be designed to have all properties that match the header text if the static ValidatorAdapter class’ Convert method will work effectively. Reflection is used to transfer data from the Validator to the object.
The heart of this adapter is in the constructor:
public static List<T> Convert(IEnumerable<RowValidator> validators)
{
var results = new List<T>();
var properties = typeof(T).GetProperties();
foreach (var validator in validators.Where(i => i.IsValid))
{
var instance = new T();
foreach (var property in properties)
{
try
{
var value = validator.GetValue(property.Name);
object convertedValue = FixValue(property.PropertyType, value);
property.SetValue(instance, convertedValue, null);
}
catch (ArgumentException e)
{
DisplayValidatorIssue(e.Message);
}
}
results.Add(instance);
}
return results;
}
The FixValue method uses the TypeDescriptor.GetConverter method to convert to the proper type, if a converter is available, otherwise the code could have trouble if a conversion is required, and there will probably be an exception thrown in the constructor. The nice thing is that the Reflection SetValue will cast the object to the correct type:
private static object FixValue(Type targetType, object value)
{
if (value.GetType() == targetType)
return value;
try
{
TypeConverter converter = TypeDescriptor.GetConverter(targetType);
return converter.ConvertFrom(value);
}
catch
{
DisplayConverterIssue(targetType, value);
return value;
}
}
Note on TypeConverter: TypeConverter is used in WPF for converting during binding. This means that it is really good at converting to/from a string value, being able to convert colors, and many other types.
Configuration Class
In this example there is a single class named Order used to configure the reader. It has a method that generates the validators required to ensure that values read are correct, and a simple property associated with each item in the collection and whose name matches the header text value in the collection items. Because of the design of the ValidatorClassAdapter adapter, the properties can be most types as long as there is a way to convert the string value using the TypeConverter associated with the type. Beware that there may be an exception if it is not possible to convert the value, so it is important that the validation for the property in the ValueValidator checks to ensure that the string is the correct one for the type.
It is not necessary to have the ValueValidator generator in the same class as the properties, but I like this solution because everything is in one class. You may prefer to just have a class for the properties, and create the ValueValidator generator someplace else.
Still this design is really nice because it is easy to create a project that will handle many different types of transfers in a project, and have no duplication. All the core code could easily be put into a separate project, and added to a library.
Excel Add-in Code
The Excel part of the code starts with creating a new project of type Excel 2010 Add-In under the Office group. This automatically adds an Excel Host Item which contains a file called ThisAddIn.cs. This can be renamed, but seems more trouble than it is worth (I think it should be much easier). I really do not need much in this ThisAddIn.cs file, and simplify it from what is provided, and include information so that the ribbon will be loaded:
public partial class ThisAddIn
{
private void InternalStartup()
{
}
protected override Microsoft.Office.Core.IRibbonExtensibility
CreateRibbonExtensibilityObject()
{
return new FoxExcelAddInRibbon();
}
}
Next I add a new Ribbon (XML) item to the project, calling it FoxExcelAddInRibbon (don’t like leaving the name as Ribbon1). This adds an XML file and a cs file to the project. If you open up the FoxExcelAddInRibbon.cs file you will see the code I added to the ThisAddIn.cs file. In the ribbon code you will see a lot of code, most of it generated for me, but I did a little cleanup. The only code I added were event handlers to handle the ribbon button, and some code to get a custom image defined as a resource. I kept the code in this fairly simple, probably should have made it simpler. In the ribbon XML, I have the three buttons defined:
="1.0"="UTF-8"
<customUI xmlns="http://schemas.microsoft.com/office/2009/07/customui"
onLoad="Ribbon_Load">
<ribbon>
<tabs>
<tab idMso="TabAddIns">
<group id="FxOrders"
label="FX Orders">
<button id="ButtonExecuteOrders"
size="large"
label="Read Orders"
onAction="OnExecuteOrders"
getImage="GetCustomImage"
tag="Search"/>
<button id="ButtonInsertTitleRow"
size="large"
label="Insert Titles"
onAction="OnInsertTitleRow"
imageMso="CreateTableTemplatesGallery"/>
<button id="ButtonShowResults"
size="large"
label="Show Results"
onAction="OnShowResults"
imageMso="GroupListToolQuickView"
screentip=" Show results in new window"/>
</group>
</tab>
</tabs>
</ribbon>
</customUI>
Make sure that there is no space between the first “<” and the start of the file because the software is fussy about any space here. I used one custom icon button (the first) where I have the name of the procedure in the code-behind in the getImage attribute, and pass the name of the resource in the tag attribute. The other two buttons use predefined images that can be found in the Office2010IconsGallery Word file which can be downloaded as http://www.microsoft.com/en-us/download/details.aspx?id=21103.
Display of Results
If nothing else, it is good to have a way to display results in a test example like this. However, in a real application it gives the user additional confidence that his data is going to be uploaded. Since I could use Excel to display these results, this from was not absolutely required, but the project engineer wanted the capability.
I used a Windows Form for this functionality. It is possible to use WPF (I generally program in WPF), but awkward, so Windows Forms is the way to go. The form I created centers around display of data in a DataGridView control. I use the docking capability to allow the user to resize the view. The form also has a panel at the bottom with buttons to Cancel and Submit, a Label to present an overview of the conversion result, and a simple icon that is green if all rows pass validation, and yellow otherwise.
The final results are no problem displaying since the DataGridView easily binds to a collection of objects that have properties for the data to be displayed. However, the design is such that only valid rows are converters to the objects; otherwise, there is only the data in the collection of RowValidation objects where the data is actually in a dictionary. I originally tried to display the data using a DynamicObject adapter but that does not recognize properties in a DynamicObject. I coded it using DataTable and that worked, but had to convert the dictionary entries to fields in a row. Then somebody pointed out the ICustomTypeDescriptor interface with the PropertyDescriptor class. This was fairly easy to customize to interface to a data source of Dictionary<string, ValueValidator>.
All the ICustomTypeDescriptor does is provide a place to save the dictionary, and return a PropertyDescriptorCollection that contains the PropertyDescriptor instances for each property using the method GetProperties.
I created a RowValidatorDescriptor that inherits from PropertyDescriptor to provide the adapter to the ValueValidator instances. There are two important methods in this class for this implementation: PropertyType (which returns the type) and GetValue. The type in this case is always string, the GetValue has to search for the right ValueValidator and return its Value property.
I did one little customization to this class so that an icon is displayed with each row. The ICustomTypeDescriptor class includes an extra PropertyDescriptor instance for this icon field, and the PropertyDescriptor for this field returns an image that depends on whether all the ValueValidator instances IsValid property is true. The only tricky part was the LINQ statement in the GetProperties method of the ICustomTypeDescriptor:
public PropertyDescriptorCollection GetProperties(Attribute[] attributes)
{
return new PropertyDescriptorCollection(
(new[] { new RowIsValidValidatorDescriptor() }).
Cast<PropertyDescriptor>().Union(
_valueValidators.Keys.Select(
key => new RowValudValidatorDescriptor(key))).ToArray());
}
LINQ requires the Cast to ensure that the two different types of PropertyDescriptor instances would work.
Examples of Customizing
All the files required to support the customization are in the folder ExporterCustom. You will notice a couple of extra files in this folder. OrderAdapter.cs is the class that is used to transfer the information and has the validation information. CustomValidators.cs contains a special validator that is used to check if the Brokers list is a list of three character words. StringList.cs is used in OrderAdapter as the type for the Brokers. It is derived from IEnumerable<string>. The reason I use this class for the Brokers is that I can define another class, StringListTypeConverter.cs, which will convert a string to the StringList type in the ValidatorAdapter. The TypeConverter is required because the ValidatorAdapter uses a class’ TypeConverter to convert to the proper type. These two classes allow me to automatically convert a string to a list without any extra code.
Excel Issue
I have one significant issue with the restoring of the formatting. It works great if the user has made changes in the formatting, but when I try to restore the borders, and then I will get a black border. I do not know how to fix this.
Excel Add-In Note
Quite often I would find that the add-in was not running in Excel. This is almost certainly because it has been disabled. In Excel 2010 you will need to go to the File tab, click the Options button, select the Add-Ins tab/button, then select Disabled Items in the Manage combo box. Then you have to click the Go… button. In the dialog box, click on the name of the add-in in the list box and click the Enable button. Unfortunately, neither Visual Studio nor Excel informs you that the add-in has been disabled. It would be nice. It would have saved me some time if I had known about this problem.
Conclusion
If you work a lot with customers that like to input data using Excel, this is a great tool to add to your toolkit that will allow you to quickly create a new Excel export that will provide validation and feedback to the user on issues in their data. There are a number of ways that this can now be further improved by providing more information on the transfer, and I am sure that this code will evolve within my group.

