Web pages provide a plethora of information and mineable data. Unfortunately, most of them are not using the XML based XHTML but the classic HTML. Therefore, we decided to extend the ANKHOR XML parser to accept most HTML content.
With this extension, it is now quite simple to e.g. extract all <img> references from a web page and convert it into a table.
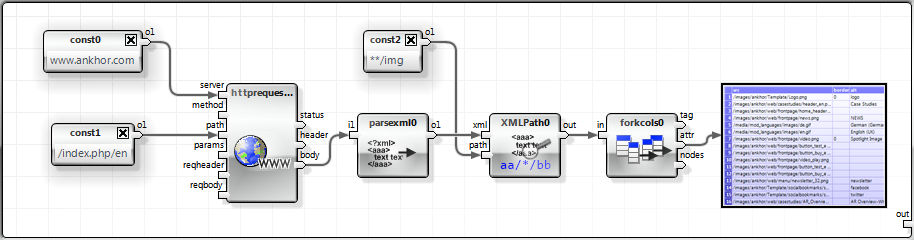
I have created a simple web crawler for testing purposes that walks through all reachable documents on a given domain starting at the root. It uses a while loop to iterate through the access depth. A HEAD request is executed in parallel for all resources that are reachable at this level and have not been accessed in one of the iterations before.
Resources with type text/html are fetched and all references such as links, images or scripts extracted and merged into a list. The list of already visited resources is then removed from this list of references to form the list for the next iteration. The loop ends when no new resources are found. Only references to the same domain are followed to avoid crawling over foreign territory.
The result is a table of all referenced resources of the domain.

A reverse match is then executed to find all inbound references, which is later used to build a scatter plot with inbound and outbound connections. So now this is enough information to build four simple charts: three bar charts with the number of resources by status code, depth and resource type and the scatter plot with in and outbound connections.
Here, we have the charts for two different domains.
All data elements have tooltips, so it is possible to see which pages are responsible for e.g. 404 status codes.
Another way to visualize the domain is using a balloon tree to display the crawling pattern. Easily accessible pages are close to the centre – hard to find resources are in leafs. The type of resource is colour coded and all nodes have their URL as tooltips.
The Graph building operator is composed of four macros. The “Edges” macro generates all internal edges as a two column table. The “ColorCodes” macro selects the color for the nodes based on the mime type of the resource. The “Graph” macro builds the graph image and the “Scale800” macro scales the resulting graph to a width of 800 pixels.
The “ColorCodes” macro shows a frequently used concept of selecting elements into groups based on identical (or similar) values in one column. In this case, I use the mime type as the group indicator.
- Identify Groups: Reduce the list of mime types to the unique values and sort them alphabetically.
- Build Group ID: Generate a uniue Identifier for the groups, in this case, I select a specific color using a palette creating macro that picks the given number of colors from a standard palette.
- Group Membership: Find the group that each member of the incoming list belongs to. An alternative would be to use the optional second output of the "
uniquerows" operator that returns the mapping from source rows to unified rows, but it would need an additional translation step due to the sorting. - Assign ID: Select the ID based on the determined group membership.
While I don't think it is wise to provide an easy to (mis)use web crawler with everyone, I would be more than happy to share it with anybody who has a compelling idea for more interesting mining targets on one's own website.
CodeProject
Author
Dr. Ulrich Sigmund

