Introduction
In this article you gain a basic understanding of how to use some Machine Learning topics in Javascript. I will use the Encog framework. I will show you how to use Encog objects to accomplish Optical Character Recognition, , Simulated Annealing, Genetic Algorithms, and Neural Networks. Encog also includes several GUI widgets that make it easy to display the output from common machine learning tasks.
Background
Encog is an advanced Machine Learning platform for Java, C#, Javascript, and C/C++. Additionally, Encog can generate code for http://www.heatonresearch.com/wiki/Meta_Trader_4. This article focuses on using Encog for Javascript. Encog for Javascript allows you to create interactive web applications that make use of Artificial Intelligence. For more information on Encog, visit the following URL:
http://www.heatonresearch.com/encog
Using the Code
All of the examples covered in this article can be found in the accompanying download.
This code is also hosted at the following GitHub repository.
https://github.com/encog/encog-javascript
You can see all of the examples covered in this article running live at the following URL:
http://www.heatonresearch.com/fun
The Encog framework is contained in two Javascript files. The first JavaScript file contains all of the core Machine Learning functions. This JavaScript file is named encog-js. The second file contains all of the GUI widgets, and is named encog-widget.js. You can see the two files included here.
<script src=" encog-js-1.0.js"></script>
<script src="encog-widget-1.0.js"></script>
Euclidean Distance
We will start by looking at Euclidean Distance. Euclidean Distance is a very simple concept that is used in many different Machine Learning techniques. Euclidean Distance provides a number that determines the similarity between two arrays of the same length. Consider the following three arrays:
Array 1: [ 1, 2, 3]
Array 2: [ 1, 3, 2]
Array 3: [ 3, 2, 1]
We can calculate the Euclidean Distance between any two of the above arrays. This is useful for determining how similar the arrays are to each other. Consider if we wanted to find out if Array 2 or Array 3 is closer to Array 1. To do this we calculate the Euclidean distance between Array 1 and Array 2. Then we calculate the distance between Array 1 and Array 3. Whichever array has the shortest distance is the most similar.
Mathematically the Euclidian Distance is calculated with the following equation.
Figure 1: Euclidean Distance
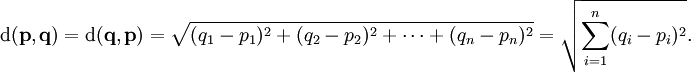
Using this formula, we can now calculate the Euclidean distance.
d(a1,a2) = sqrt( (a2[0]-a1[0])^2 + (a2[1]-a1[1])^2 + (a2[1]-a1[1])^2 )
d(a1,a2) = sqrt( (1-1)^2 + (3-2)^2 + (2-3)^2 )
d(a1,a2) = sqrt( 0+1+1 )
d(a1,a2) = sqrt(2) = 1.4
d(a1,a3) = sqrt( (a3[0]-a1[0])^2 + (a3[1]-a1[1])^2 + (a3[1]-a1[1])^2 )
d(a1,a3) = sqrt( (3-1)^2 + (2-2)^2 + (1-3)^2 )
d(a1,a3) = sqrt( 4+0+4 )
d(a1,a3) = sqrt(8) = 2.3
From this we can see that Array 2 is closer to Array 1 than is Array 3.
The following JavaScript code implements Euclidean Distance calculation.
ENCOG.MathUtil.euclideanDistance = function (a1, a2, startIndex, len) {
'use strict';
var result = 0, i, diff;
for (i = startIndex; i < (startIndex + len); i += 1) {
diff = a1[i] - a2[i];
result += diff * diff;
}
return Math.sqrt(result);
};
Euclidean Distance can be used to create a simple optical character recognition. You can see this application running here:
Figure 2: Javascript OCR

You can see this program running at the following URL:
http://www.heatonresearch.com/fun/ocr
The HTML5 (touch device enabled) Javascript application that you see below implements basic Optical Character Recognition using simple Euclidean Distance comparisons. To make use of this example draw a digit in the large rectangle below. Click the "Recognize" button and the program will attempt to guess what digit you drew. The accuracy is not perfect, but it does do a reasonably good job.
The program is already trained with the digits. You can remove any of these digit entries, or create your own. To train the OCR for a new character simply draw that character and click the "Teach" button. This will add the character to the list of characters known by the program.
You will notice that anything that you draw is first cropped, and then downsampled. The high resolution characters that you draw are downsampled onto a 5x8 grid. This downsampled grid is then compared to similarly downsampled grids for each of the digits. To see the grids that the program was trained with click the character in the list that you would like to see. This grid is then converted to a 1d array. A 5x8 grid would have 40 elements. Now that the characters are arrays, recognizing a new character is just a matter of finding the known character with the shortest length to what you just drew.
The following Javascript performs this search, and implements a Euclidean distance calculation.
var c, data, sum, i, delta;
for(c in charData )
{
data = charData[c];
sum = 0;
for(var i = 0; i<data.length; i++ )
{
delta = data[i] - downSampleData[i];
sum = sum + (delta*delta);
}
sum = Math.sqrt(sum);
if( sum<bestScore || bestChar=='??' )
{
bestScore = sum;
bestChar = c;
}
}
Flocking
This example shows a fascinatingly simple algorithm called flocking. The particles seen here are flocking. Initially they start in random locations, however, they soon fill form groups and fly in seemingly complex patterns. You can also click (or touch) a location and the particles will repel from the location you touched.
Figure 3: Flocking
You can run this example online at the following URL:
http://www.heatonresearch.com/fun/flock
It might take up to a minute (or so) for well-established flocks to emerge. Even after these flocks emerge they will often split and recombine. To start over click "Clear". It is also possible to click "Big Bang", which uses no random initialization at all. The particles are all placed in the middle of the universe and quickly move outward assuming their "complex" patterns.
Craig Reynolds with his simulation program, Boids, first simulated flocking behavior on a computer in 1986. Flocking seems like a very complex behavior. It is exhibited by many different animals, using many different names. A flock of birds. A swarm of insects. A school of fish. A herd of cows. All different names to describe essentially the same behavior.
At first glance, a flocking algorithm may seem complex. I would probably create an object to handle the individuals in the flock. I would need to define a flock object to hold flock members. Routines would need to be developed to determine which direction the flock should go. We would also have to decide how a flock should split into two or more flocks. What criteria determine how big a flock can get? How are new members admitted? You can see some real-life examples of bird flocking here.
The flocking algorithm is actually very simple. It has only three rules.
- Separation - avoid crowding neighbors (short range repulsion)
- Alignment - steer towards average heading of neighbors
- Cohesion - steer towards average position of neighbors (long range attraction)
These three rules are all that it takes. Flocking is truly an example of "Simple Complexity".
I wanted to keep this example as utterly simplistic as possible, yet still exhibit seemingly complex behavior. The particles are all moving at a constant speed. Each particle has an angle that defines the direction the particle is moving. The particles cannot speed up or slow down. They can only turn.
The above three rules each specify an "ideal angle" for the particle to move towards. The desire to obey each of the three rules is dampened by a specific percent. These are the three numbers you see at the bottom. You can play with these three and see how they affect things. Many combinations will not produce flocking behavior at all. The default values I provide work well.
If you want to see the effect of one of the three rules in isolation, set that rule to 1.0 and the others to 0.0. For example, if you isolate cohesion, then you will end up with all of the particles converging to a few locations in the universe.
There is no randomness in this universe at all. Other than placing the particles in initial random locations, no further random numbers are generated. You can even click the "big bang" button, and eliminate all randomness from the system. If you click "big bang" all particles will be placed in the center with motion in the same direction. It does not take long for a complex pattern to emerge. Flocking is a great example of how very simple rules can produce very complex systems.
Euclidean distance is very important to this example. Each particle has two dimensions, an x-coordinate and a y-coordinate. Using Euclidian distances we can find the nearest neighbors. This introduces another important Machine Learning algorithm, called “K Nearest Neighbors”. Where K is the number of neighbors that you want to find.
The above three rules can easily be implemented in Javascript. First, we calculate the ideal separation angle.
separation = 0;
if (nearest.length > 0) {
meanX = ENCOG.ArrayUtil.arrayMean(nearest, 0);
meanY = ENCOG.ArrayUtil.arrayMean(nearest, 1);
dx = meanX - this.agents[i][0];
dy = meanY - this.agents[i][1];
separation = (Math.atan2(dx, dy) * 180 / Math.PI) - this.agents[i][2];
separation += 180;
}
First, we calculate the average (mean) x and y coordinates for all of the neighbors. This average is the center of the cluster of neighbors. Then, using a little Trigonometry, we calculate the angle between us and the center of the cluster. We then add 180, because we want to move away from our nearest neighbors (so we do not bump them). This is the ideal separation angle that we should “shoot for”.
Next, we calculate the ideal alignment angle. The following code does this.
alignment = 0;
if (neighbors.length > 0) {
alignment = ENCOG.ArrayUtil.arrayMean(neighbors, 2) - this.agents[i][2];
}
The alignment is very simple. It is the average angle of all of the neighbors.
Next we calculate the cohesion. To do this we again look at neighbors, but this time we consider a much bigger set, nearly all particles. This works very similar to separation, except we move towards the center of the long-range neighbors.
cohesion = 0;
if (neighbors.length > 0) {
meanX = ENCOG.ArrayUtil.arrayMean(this.agents, 0);
meanY = ENCOG.ArrayUtil.arrayMean(this.agents, 1);
dx = meanX - this.agents[i][0];
dy = meanY - this.agents[i][1];
cohesion = (Math.atan2(dx, dy) * 180 / Math.PI) - this.agents[i][2];
}
Now that we have the ideal angle from each of the three rules we must actually turn the particle (or agent).
turnAmount = (cohesion * this.constCohesion) + (alignment * this.constAlignment) + (separation * this.constSeparation);
this.agents[i][2] += turnAmount;
So far we have looked at techniques that impose no randomness. Such techniques can be said to be deterministic. That is the outcome can always be predicted. For the reset of this article we will now do a 180. The remaining techniques are stochastic. They use randomness to solve problems.
The Traveling Salesman Problem
The Traveling Salesman Problem (TSP) involves a "traveling salesman" who must visit a certain number of cities. The shortest route that the salesman will travel is what is being sought. The salesman is allowed to begin and end at any city. The only requirement is that the traveling salesmen visit each city once. The salesman may not visit a city more than once.
This may seem like an easy enough task for a normal iterative program. Consider the magnitude with which the number of possible combinations grows as the number of cities increases. If there is one or two cities only one step is required. Three increases this to six. Table 8.1 shows how quickly these numbers grow.
Table 1: Number of steps to solve TSP with a conventional program
| Number of Cities | Number of Steps |
|---|
| 1 | 1 |
|---|
| 2 | 1 |
| 3 | 6 |
| 4 | 24 |
| 5 | 120 |
| 6 | 720 |
| 7 | 5,040 |
| 8 | 40,320 |
| 9 | 362,880 |
| 10 | 3,628,800 |
| 11 | 39,916,800 |
| 12 | 479,001,600 |
| 13 | 6,227,020,800 |
| ... | ... |
| 50 | 3.041 * 10^64 |
The formula behind the above table is the factorial. The number of cities n is calculated using the factorial operator (!). The factorial of some arbitrary n value is given by n * (n-1) * (n-2) * ... * 3 * 2 * 1. As you can see from the above table, these values become incredibly large when a program must do a "brute force" search. The example program that we will examine in the next section finds a solution to a fifty city problem in a matter of minutes. Using Simulated Annealing, rather than a normal brute-force search does this.
Simulated Annealing
Simulated annealing is a programming method that attempts to simulate the physical process of annealing. Annealing is a where a material is heated and then cooled (as steel or glass) usually for softening and making the material less brittle. Simulated annealing, therefore, exposes a "solution" to "heat" and cools producing a more optimal solution. You can run the simulated annealing example at the following URL.
http://www.heatonresearch.com/fun/tsp/anneal
Simulated annealing works by moving from the starting temperature to the ending temperature for each iteration. The cycle count allows you to specify the granularity at which the temperature decreases. The higher the temperature, the more randomness is introduced into the system. You can configure all three of these parameters.
The following Javascript implements the annealing.
anneal.randomize = function(path, temperature) {
var length = path.length - 1;
for (var i = 0; i < temperature; i++) {
var index1 = Math.floor(length * Math.random());
var index2 = Math.floor(length * Math.random());
var d = universe.pathDistance(path, index1, index1 + 1)
+ universe.pathDistance(path, index2, index2 + 1)
- universe.pathDistance(path, index1, index2)
- universe.pathDistance(path, index1 + 1, index2 + 1);
if (d > 0) {
if (index2 < index1) {
var temp = index1;
index1 = index2;
index2 = temp;
}
for (; index2 > index1; index2--) {
var temp = path[index1 + 1];
path[index1 + 1] = path[index2];
path[index2] = temp;
index1++;
}
}
}
}
The above randomize function was setup specifically for the TSP. The Simulated Annealing algorithm inside of Encog is generic, and has nothing to do with the TSP. You must provide a randomize function for the problem you are trying to solve.
Basically, the randomize function modifies the city path according to the temperature. The above function simply flips cities in the path up to the temperature. The higher the temperature, the more flips.
Random Cities
The most common use of this program is to simply place random cities on the map. These cities will be placed in random locations over the map. Some random city combinations are harder than others. You can see a 50 random city map shown here.
Figure 4: Random Cities
Once a set of cities is “solved” it looks something like this.
Figure 5: Potential Solution
You may want to evaluate how effective simulated annealing is when you vary the parameters. To rerun, you should just randomize the path. This will allow you to start over using the same city configuration.
Cities in a Circle
You can also place the cities in a circle. This makes it easier to visualize how close Simulated Annealing came to an optimal solution. The optimal path around a circle is around the perimeter. Here you can that simulated annealing found a nearly optimal path.
Figure 6: Cities in a Circle
Genetic Algorithms
A potential solution for the TSP can also be obtained by using a Genetic Algorithm (GA). GA's use simple evolutionary operations to create a population of ever improving solutions. The entire process is simplified version biological evolution. Evolution is implemented through crossover and mutation. Crossover occurs when two solutions "mate" and produce offspring. Mutation occurs when a single solution is slightly altered.
Like Simulated Annealing GA's are also stochastic. Randomness is used during crossover to determine what characteristics the mother and father will pass on. Randomness is also introduced by mutation, which is an inherently random process.
You can see the Genetic TSP application online here:
http://www.heatonresearch.com/fun/tsp/genetic
To create a genetic algorithm with Encog you must define the mutate and crossover operations. The means by which these two are implemented are dependent on the type of solutions you are looking for.
The following code assigns a mutation operation for the TSP.
genetic.mutate = function performMutation(data)
{
var iswap1 = Math.floor(Math.random() * data.length);
var iswap2 = Math.floor(Math.random() * data.length);
if (iswap1 == iswap2)
{
if (iswap1 > 0)
{
iswap1--;
} else {
iswap1++;
}
}
var t = data[iswap1];
data[iswap1] = data[iswap2];
data[iswap2] = t;
}
This is actually very similar to the randomize operator defined for Simulated Annealing. Essentially two cities in the list are swapped by the above code. We make sure that the two random cities are not equal, because then no swap would occur.
The crossover operation is a bit more complex. The following code implements the crossover function.
genetic.crossover = function performCrossover(motherArray, fatherArray, child1Array, child2Array)
{
var cutLength = motherArray.length / 5;
var cutpoint1 = Math.floor(Math.random() * (motherArray.length - cutLength));
var cutpoint2 = cutpoint1 + cutLength;
var taken1 = {};
var taken2 = {};
for (var i = 0; i < motherArray.length; i++)
{
if (!((i < cutpoint1) || (i > cutpoint2)))
{
child1Array[i] = fatherArray[i];
child2Array[i] = motherArray[i];
taken1[fatherArray[i]] = true;
taken2[motherArray[i]] = true;
}
}
for (var i = 0; i < motherArray.length; i++)
{
if ((i < cutpoint1) || (i > cutpoint2))
{
child1Array[i] = getNotTaken(motherArray,taken1);
child2Array[i] = getNotTaken(fatherArray,taken2);
}
}
};
The above code works by taking two "cut points" the path of cities. This divides the mother and father both into thirds. Both mother and father have the same cut points. The sizes of these cuts are random. Then two offspring are created by swapping the thirds. For example, consider the following mother and father.
[m1, m2, m3 ,m4, m5, m6, m7, m8, m9, m10]
[f1, f2, f3 ,f4, f5, f6, f7, f8, f9, f10]
We now impose the cut points.
[m1, m2] [m3 ,m4, m5, m6] [m7, m8, m9, m10]
[f1, f2] [f3 ,f4, f5, f6] [f7, f8, f9, f10]
This would produce the following two children.
[m1, m2] [f3 ,f4, f5, f6] [m7, m8, m9, m10]
[f1, f2] [m3 ,m4, m5, m6] [f7, f8, f9, f10]
Depending on another random event, each child solution potentially be mutated. Mutation is the process by which "new information" is added to the populations genetics. Otherwise we are simply passing around traits that were already present.
XOR Neural Network
Neural Networks are another Machine Learning method that is based on biology. Neural Networks are very loosely based on the human brain. A neural network is built of neurons connected by synapses. Each synapse has a weight. These weights form the memory of the neural network. You can see a neural network here.
Figure 7: A neural network
This is actually the neural network that we will be creating in the next section. You can see from the above neural network that it has an input and an output layer. The neural network receives stimuli from the input layer and responds by the output layer. There also may be hidden layers, which also contain neurons. The hidden layers aid in the processing.
The XOR neural network is a neural network with 2 inputs and 1 output. The two inputs receive boolean numbers (0 or 1). The output neuron also outputs boolean numbers. The idea is to cause the neural network to perform the same as the XOR operator.
0 XOR 0 = 0
1 XOR 0 = 1
0 XOR 1 = 1
1 XOR 1 = 0
The output from the XOR operator is only 1 when the two inputs disagree.
You can see the output from the XOR example here.
Training XOR with Resilient Propagation (RPROP)
Training Iteration #1, Error: 0.266564333804989
Training Iteration #2, Error: 0.2525674154011323
Training Iteration #3, Error: 0.2510141208338126
Training Iteration #4, Error: 0.2501895607116004
Training Iteration #5, Error: 0.24604660296617512
Training Iteration #6, Error: 0.24363697465430123
Training Iteration #7, Error: 0.24007542622000883
Training Iteration #8, Error: 0.23594361591893737
Training Iteration #9, Error: 0.23110199069041137
Training Iteration #10, Error: 0.22402031408256806
...
Training Iteration #41, Error: 0.0169149539750981
Training Iteration #42, Error: 0.012983289628979862
Training Iteration #43, Error: 0.010217909135985562
Training Iteration #44, Error: 0.007442433731742264
Testing neural network
Input: 0 ; 0 Output: 0.000005296759326400659 Ideal: 0
Input: 1 ; 0 Output: 0.9176637562838892 Ideal: 1
Input: 0 ; 1 Output: 0.9249242746585553 Ideal: 1
Input: 1 ; 1 Output: 0.036556423402042126 Ideal: 0
As you can see from the above it took 44 training iterations to teach the neural network to perform the XOR. The weights of the neural network start as random numbers. The training process gradually adjusts the weights to produce the desired output. The stochastic (or random) part of a neural network is weight initialization. Beyond that, the neural network is deterministic. Given the same weights and input, a neural network will always produce the same output.
You may notice in the above output that the output is not exact. The neural network will never train to exactly 1.0 for the output for a 1. You will also never see the same results twice from this network, because of the random starting weights. Also some random weights are totally un-trainable. Because of this you will sometimes see the XOR network hit the max iterations of 5,000 and then give up.
You can see this example at the following URL.
http://www.heatonresearch.com/fun/ann/xor
We will now look at how this program was constructed. First we create the input and ideal arrays.
var XOR_INPUT = [
[0,0],
[1,0],
[0,1],
[1,1]
];
var XOR_IDEAL = [
[0],
[1],
[1],
[0]
];
The above two arrays hold the inputs and ideal outputs. This "truth table" will be used to train the neural network.
Next we create a three-layer neural network. The input layer has 2 neurons, the hidden 3 neurons and the output layer has a single neuron.
var network = ENCOG.BasicNetwork.create( [
ENCOG.BasicLayer.create(ENCOG.ActivationSigmoid.create(),2,1),
ENCOG.BasicLayer.create(ENCOG.ActivationSigmoid.create(),3,1),
ENCOG.BasicLayer.create(ENCOG.ActivationSigmoid.create(),1,0)] );
network.randomize();
The network is created and randomized. Calling randomize fills the weights with random values.
There are several different ways to train a neural network. For this example we will use RPROP.
var train = ENCOG.PropagationTrainer.create(network,XOR_INPUT,XOR_IDEAL,"RPROP",0,0);
We will now cycle through training iterations until the error drops below an acceptable level.
var iteration = 1;
do
{
train.iteration();
var str = "Training Iteration #" + iteration + ", Error: " + train.error;
con.writeLine(str);
iteration++;
} while( iteration<1000 && train.error>0.01);
Now the neural network is trained. We will loop through the input array and submit each to the neural network. The output from the neural network is displayed.
var input = [0,0];
var output = [];
con.writeLine("Testing neural network");
for(var i=0;i<XOR_INPUT.length;i++)
{
network.compute(XOR_INPUT[i],output);
var str = "Input: " + String(XOR_INPUT[i][0])
+ " ; " + String(XOR_INPUT[i][1])
+ " Output: " + String(output[0])
+ " Ideal: " + String(XOR_IDEAL[i][0]);
con.writeLine(str);
}
This is a very simple introduction to neural networks. I also did a Java and C# article focusing just on neural networks. You can find those here.
- <ahref="http:>Introduction to Neural Networks for Java
- <ahref="http:>Introduction to Neural Networks for C#
Additionally, if you would like a basic introduction to neural networks, the following article may be useful.
http://www.heatonresearch.com/content/non-mathematical-introduction-using-neural-networks
Classification Neural Network
We will now look at a slightly more complex neural network use to classify. This neural network will learn to classify. You will see how the neural network learns to classify data points in the training set, as well as nearby data points that were not provided in the training data.
You can run the example from this URL:
http://www.heatonresearch.com/ann/classification
This example makes use of a feedforward neural network to demonstrate classification. To make use of this application draw several colored dots onto the drawing area. Make sure you have at least two colors, or there will be nothing to classify. Once you have drawn something click begin, and the neural network will begin to train. You will see how other regions near the data points you provided are classified.
The above neural network has two input neurons and three output neurons. The hidden layer structure is defined by the drop list. For example, if you choose 2:10:10:3, you will have a network that looks like the following image. This network has two hidden layers, with 10 neurons each.
The input neurons represent the x and y coordinates of a dot. To draw the above image the program loops over a grid of x and y coordinates. The neural network is queried for each of the grid components. The cell in the upper left is [0,0], the cell in the lower right is [1,1]. Data to a neural network with sigmoid activation functions should usually receive input in the range between 0 and 1, so this range works fine. The center would be [0.5,0.5].
The output from the neural network represents the RGB color that that grid square should have. The value of [0,0,0] would represent black, and the value [1,1,1] would represent white.
As you draw on the drawing region you are providing training data. The input neurons will represent the x and y coordinate that you placed the data at. The expected, or ideal, output will represent the color that you chose for that location.
Lets look at a simple example. If you draw only two data points, then the area will be divided in half. Here you can see a red and blue data point provided.
Figure 8: Classification with two points
For the application to get the error level low it only needs to make sure that the blue data point is in a blue region, and the red data point is in a red region. All other points are "guessed" based on the other points. With such a very small amount of data, it is difficult for the neural network to really guess where the border between the two zones actually is.
If you provide more training data you will get a more complex shape. If you chose to create a two-color random image, will you will be given data points similar to the following.
Figure 9: Classification with more points
Here the neural network creates a much more complex pattern to try to fit around all of the data points.
You might also choose to create a complex multi-color pattern. Here random colors were generated for the points. The neural network will even blend colors to try to compromise and lower the error as much as it can.
Figure 10: Classification with several colors
It is even possible to learn complex inter-winding shapes such as the following.
Figure 11: Classification of spirals
Further Reading
This article provides an introduction to Machine Learning in Javascript. If you would like to learn more about Machine Learning you may be interested in the following links.
History
- October 16, 2012: First version, using Encog JS v1.0

