Introduction
This article explains an application that can process any tree structure of strings, such as
an XML document or a JSON document.
My application needs a scheme file and a config file to define the target document structure.
Using the code
I abstract the input document into a tree structure combined by tree nodes. Each node contains a scheme phrase and each phrase
is combined by words.
The word is a string vector. Each input char of the input document has an input type before it is saved in the word. There is the input type:
enum ObjectType{
NORMAL_WORD,
KEY_WORD,
INVALID_WORD,
SEPARATE_LETTER,
SPECIAL_LETTER,
IGNORE_LETTER,
NORMAL_LETTER,
INVALID_LETTER,
SCHEME_PHRASE
};
The type has key word, invalid word, special letter, ignore letter, invalid letter, and so on. These letters and words are defined in the config file which
is input at the initialization stage of our application. They are saved in a
Dictionary class.
bool Dictionary::init(std::string configFile){
FILE *file = NULL;
fopen_s(&file,configFile.c_str(),"r");
if (file == NULL) return false;
insertWords(file,KEY_WORD);
insertLetters(file,SPECIAL_LETTER);
insertLetters(file,SEPARATE_LETTER);
insertLetters(file,IGNORE_LETTER);
insertLetters(file,INVALID_LETTER);
fclose(file);
return true;
}
Each line of the config file is a type of input object and they are separated by ','. After filtering the input letters and constructing them into words,
a file analysis class is used to analyze the input strings and organize them into a tree model. The file analysis class uses the
Scheme class to match
the input document. The match equation is defined in a scheme file.
void Scheme::init(std::string config){
if (dictionary == NULL) return;
FILE *file = NULL;
fopen_s(&file,config.c_str(),"r");
while(file != NULL && !feof(file)){
std::string sentence;
readSentence(file,sentence);
if (sentence.empty() == true) continue;
SchemePhrase equation;
unsigned int offset = 0;
analyzeSentence(sentence,offset,&equation);
equations.push_back(equation);
}
if (file != NULL) fclose(file);
}
void FileAnalysis::analyze(){
std::vector<InputObject*> elements;
while(true){
InputObject* object = fileReaders->getNextObject();
if (object == NULL) break;
elements.push_back(object);
}
std::vector<Memo> &process = scheme->match(elements);
TreeNode *curNode = tree->getRoot();
for(unsigned int p = 0; p < process.size(); ++p){
Memo &m = process[p];
if (m.operation->getType() == SCHEME_PHRASE){
SchemePhrase * phrase = dynamic_cast<SchemePhrase*>(m.operation);
if (phrase->getOperation() == UPCHILD){
curNode = curNode->getFather();
}else if (phrase->getOperation() == DOWNCHILD){
curNode = curNode->getLastChild();
}
}else if (m.operation->getType() == NORMAL_WORD){
curNode->makeChild(dynamic_cast<Word*>(m.operation)->getContent(),
dynamic_cast<Word*>(m.object)->getContent());
}
}
}
The tree node uses a component design pattern. Each of them has a value and a name parameter and has the pointers to its children which are the same type.
class BaseNode
{
public:
BaseNode(void);
~BaseNode(void);
void setName(std::string n){ name = n; }
void setValue(std::string v){ value = v;}
std::string getName(){return name;}
std::string getValue(){return value;}
private:
std::string name;
std::string value;
};
class TreeNode :
public BaseNode
{
public:
TreeNode(TreeNode *father = NULL,std::string name="", std::string value = "");
virtual ~TreeNode(void);
TreeNode* getNode(std::string name, std::string value = "");
void addNode(TreeNode node){elements.push_back(node);}
TreeNode* makeChild(std::string name, std::string value = "");
TreeNode* getFather();
TreeNode* getLastChild();
TreeNode* getElement(int i){return &elements[i];}
unsigned int size(){return elements.size();}
std::vector<TreeNode*> getNodes(std::string name, std::string value = "");
std::string get(std::string name);
std::vector<std::string> gets(std::string name);
void clear();
private:
TreeNode *father;
std::vector<TreeNode> elements;
};
After processing the input document, the node of the tree can be got by the name value.
std::vector<TreeNode*> TreeNode::getNodes(std::string name, std::string value){
std::vector<TreeNode *> result;
for(unsigned int i = 0; i < elements.size(); ++i){
if (elements[i].getName() == name && (value == "" || elements[i].getValue() == value)){
result.push_back(&(elements[i]));
}
}
return result;
} Examples
To init the schema file and the config file:
ModelTree tree;
Dictionary dic;
Scheme sch(&dic);
FileAnalysis analysis;
TreeNode * root;
analysis.setDictionary(&dic);
analysis.setScheme(&sch);
analysis.setTree(&tree);
dic.init("config\\config.txt");
sch.init("config\\scheme.txt");
analysis.setFile("input.txt");
analysis.analyze();
To process the input document and print them:
root = tree.getRoot();
printNode(root,0);
Then process the JSON document. The input config:
meta;
44;125;93;123;91;34;58;
32;9;10;
0;1;2;3;4;5;6;7;8;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;127;
;
The input schema:
;{"element":\d ["value"|\[ self [, self]* \]]1 \u [,"element":\d ["value"|\[ self [, self]* \]]1 \u]* }
The input file:
{ "programmers": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "be@gmail.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "abc@gmail.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "ell@163.com" }
],
"authors": [
{ "firstName": "Isaac", "lastName": "Asimov", "genre": "sciencefiction" },
{ "firstName": "Tad", "lastName": "Williams", "genre": "fantasy" },
{ "firstName": "Frank", "lastName": "Peretti", "genre": "christianfiction" }
],
"musicians": [
{ "firstName": "Eric", "lastName": "Clapton", "instrument": "guitar" },
{ "firstName": "Sergei", "lastName": "Rachmaninoff", "instrument": "piano" }
] }
The output:
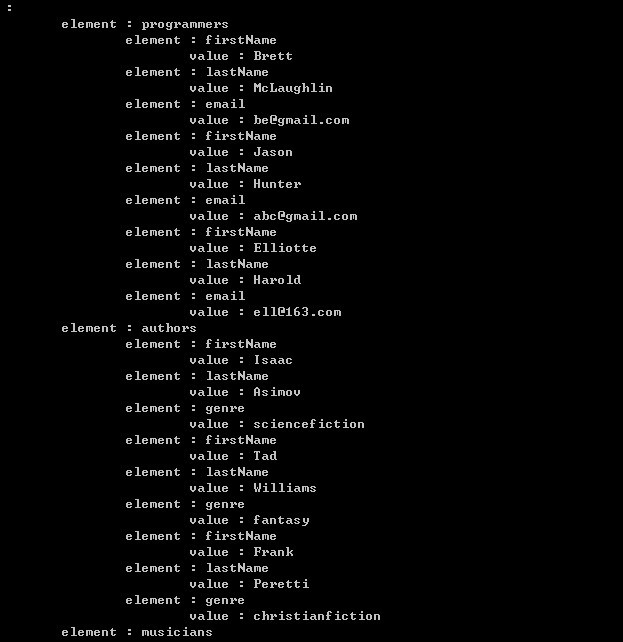
Then process the XMLdocument.
The input config:
meta;
60;61;62;63;92;34;47;
32;9;10;
0;1;2;3;4;5;6;7;8;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;127;
;
The input schema:
;<element\d [attribute[="\dvalue\u"]1]* >[value|self]*\u</element>
;<element\d [attribute[="\dvalue\u"]1]* \u/>
The input file:
<book title="facebook" >
<auther><lxdfigo name="lxd" >
<age value="16" />
</lxdfigo></auther>
<price value="216.0" />
<date value="2012-2-3" />
</book>
<book2 title="facebook" >
<auther><lxdfigo name="lxd" >
<age value="16" />
</lxdfigo></auther>
<price value="216.0" />
<date value="2012-2-3" />
</book2>
<book title="facebook" >
<auther><lxdfigo name="lxd" >
<age value="16" />
</lxdfigo></auther>
<price value="216.0" />
<date value="2012-2-3" />
</book>
<book2 title="facebook" >
<auther><lxdfigo name="lxd" >
<age value="16" />
</lxdfigo></auther>
<price value="216.0" />
<date value="2012-2-3" />
</book2>
The output:


