Introduction
The first thing we learn to do with SQL is writing a SELECT
statement to get data from one table. This kind of statement seems to be
straightforward and very close to the language we speak.
But real-world queries are often much more sophisticated than
those simple SELECT statements.
First of all, usually the data we need is split into several
different tables. This is a natural consequence of data normalization, which is
an essential feature of any well designed database model. And SQL gives you the
power to put that data together.
In the past, DBAs and developers used to put all necessary
tables and/or views in the FROM clause and then use the WHERE clause to define
how the records from each table would combine with the other records. (To make
this text a bit more readable, from now on, I will simplify things and say
"table" instead of "table and/or view").
But there's been a long time since we have a standard for
bringing these data together. And this is done using the JOIN operator (ANSI-SQL 92). Unfortunately, there are some details about JOIN operators that
remain obscure for many people.
Below I will show different syntaxes of joins supported by T-SQL
(that is SQL Server 2008). I will outline a few concepts I believe they
shouldn't be forgot each time we combine the data from two tables or more.
Getting Started: 1 Table, no Join
When you have only one object to query, the syntax will be quite
simple and no join will be used. The statement will be the good and old
"SELECT fields FROM object" plus any other optional
clause you might want to use (that is WHERE, GROUP BY,
HAVING, or ORDER BY).
One thing that end users don't know is that we DBAs usually hide
lots of complex joins under one nice and easy-to-use view. This is done for
several reasons, ranging from data security to database performance. For
instance, DBAs can give permissions for the end users to access one single view
instead of several production tables, obviously increasing data security. Or
considering performance, DBAs can create a view using the right parameters to
join the records from several tables, correctly using database indexes and thus
boosting query performance.
All in all, joins might be there in the database even when the
end users don't see them.
The Logic Behind Joining Tables
Many years ago, when I started working with SQL, I learned there
were several types of joins. But it took me some time to understand what
exactly I was doing when I brought those tables together. Maybe because people
are so scared of mathematics, it is not frequently said that the whole idea
behind joining tables is about Set
Theory. Despite the fancy name, the concept is so simple we are taught
it in elementary school.
The drawing in Figure 1 is quite similar to the ones found in my
kids' books from First Grade. The idea is to find correspondent objects in the
different sets. Well, this is precisely what we do with SQL JOINs!
Once you understand the analogy, things will start to make
sense.
Consider that the 2 sets in are tables and the numbers we see
are the keys we will use to join the tables. So in each set, instead of
representing the whole records, we are only seeing the key fields from each
table. The result set of this combination will be determined by the type of
join we consider, and this is the topic I will show now. To illustrate our
examples, consider we have 2 tables, shown below:
Table 1
| key1
| field1
| field2
| key2
| key3
|
| 3
| Erik
| 8
| 1
| 6
|
| 4
| John
| 3
| 4
| 4
|
| 6
| Mark
| 3
| 7
| 1
|
| 7
| Peter
| 6
| 8
| 5
|
| 8
| Harry
| 0
| 9
| 2
|
Table 2
| key2
| field1
| field2
| field3
|
| 1
| New York
| A
| N
|
| 2
| Sao Paulo
| B
| N
|
| 4
| Paris
| C
| Y
|
| 5
| London
| C
| Y
|
| 6
| Rome
| C
| Y
|
| 9
| Madrid
| C
| Y
|
| 0
| Bangalore
| D
| N
|
The script to create and populate those tables are available as
one attached file (SQLServerCentral.com_JOIN.sql) in the Resources
section below.
You will notice this script does not fully implement referential
integrity. I intentionally left the tables without foreign keys to better
explain the functionality of the different types of joins. But I did so for
didactical purposes only. Foreign keys are extremely useful to guarantee data
consistency and they should not be left out of any real-world database.
Well, now we are ready to go. Let's check the types of joins we
can use in T-SQL, the correspondent syntax and the result set that each one
will generate.
The Inner Join
This is the most common join we use in SQL. It returns the
intersection of two sets. Or in terms of tables, it brings only the records
from both tables that match a given criteria.
We can see in Figure 2 the Venn diagram illustrating the inner
join of two tables. The result set of the operation is the area in red.
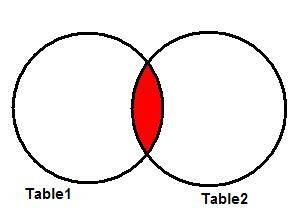
Figure 2: Representing the INNER JOIN
Now check the syntax to combine the data from Table1 and Table2 using an
INNER JOIN.
SELECT t1.key1, t1.field1 as Name, t1.key2 as T1Key,
t2.key2 as T2Key, t2.field1 as City
FROM Table1 t1
INNER JOIN Table2 t2 ON t1.key2 = t2.key2;
The result set of this statement will be:
| key1
| Name
| T1Key
| T2Key
| City
|
| 3
| Erik
| 1
| 1
| New York
|
| 4
| John
| 4
| 4
| Paris
|
| 6
| Harry
| 9
| 9
| Madrid
|
Notice it returned only the data from records which have the
same value for key2 on both Table1 and Table2.
Opposed to the INNER JOIN, there is also the OUTER JOIN. There
are three types of OUTER JOINs, named full, left and right. We will look at each
one in detail below.
The FULL JOIN
This is also known as the FULL OUTER JOIN (the reserved word
OUTER is optional). FULL JOINs work like the union of two sets. Now we have in Figure 3 the
Venn diagram illustrating the FULL JOIN of two tables. The result set of the
operation is again the area in red.
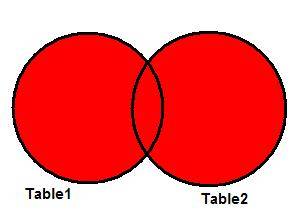
Figure 3: Representing the FULL JOIN
The syntax is almost exactly the same we saw before.
SELECT t1.key1, t1.field1 as Name, t1.key2 as T1Key,
t2.key2 as T2Key, t2.field1 as City
FROM Table1 t1
FULL JOIN Table2 t2 ON t1.key2 = t2.key2 ;
The result set of this statement will be:
| key1
| Name
| T1Key
| T2Key
| City
|
| 3
| Erik
| 1
| 1
| New York
|
| 4
| John
| 4
| 4
| Paris
|
| 6
| Mark
| 7
| null
| null
|
| 7
| Peter
| 8
| null
| null
|
| 8
| Harry
| 9
| 9
| Madrid
|
| null
| null
| null
| 2
| Sao Paulo
|
| null
| null
| null
| 5
| London
|
| null
| null
| null
| 6
| Rome
|
| null
| null
| null
| 0
| Bangalore
|
The FULL JOIN returns all records from Table1 and Table2,
without duplicating data.
The LEFT JOIN
Also known as LEFT OUTER JOIN, this is a particular case of the
FULL JOIN. It brings all requested data from the table that appears to the left
of the JOIN operator, plus the data from the right table which intersects with
the first one. Below we have a Venn diagram illustrating the LEFT JOIN of two
tables in Figure 4.
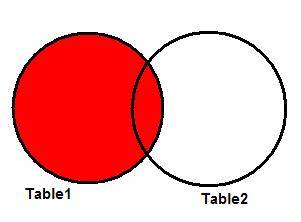
Figure 4: Representing the LEFT JOIN
See the syntax below.
SELECT t1.key1, t1.field1 as Name, t1.key2 as T1Key,
t2.key2 as T2Key, t2.field1 as City
FROM Table1 t1
LEFT JOIN Table2 t2 ON t1.key2 = t2.key2 ;
The result set of this statement will be:
| key1
| Name
| T1Key
| T2Key
| City
|
| 3
| Erik
| 1
| 1
| New York
|
| 4
| John
| 4
| 4
| Paris
|
| 6
| Mark
| 7
| null
| null
|
| 7
| Peter
| 8
| null
| null
|
| 8
| Harry
| 9
| 9
| Madrid
|
The third and forth records (key1 equals
to 6 and 7) show NULL values on the last fields because there is no information
to be brought from the second table. This means we have a value in field key2 in Table1 with no
correspondent value in Table2. We could have avoided this "data inconsistency" in
case we had a foreign key on field key2 in Table1.
The RIGHT JOIN
Also known as RIGHT OUTER JOIN, this is another particular case
of the FULL JOIN. It brings all requested data from the table that appears to
the right of the JOIN operator, plus the data from the left table which
intersects with the right one. The Venn diagram for the RIGHT JOIN of two
tables is in Figure 5.
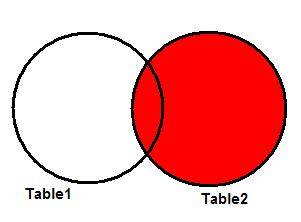
Figure 5: Representing the RIGHT JOIN
As you can see, syntax is very similar.
SELECT t1.key1, t1.field1 as Name, t1.key2 as T1Key,
t2.key2 as T2Key, t2.field1 as City
FROM Table1 t1
RIGHT JOIN Table2 t2 ON t1.key2 = t2.key2 ;
The result set of this statement will be:
| key1
| Name
| T1Key
| T2Key
| City
|
| null
| null
| null
| 0
| Bangalore
|
| 3
| Erik
| 1
| 1
| New York
|
| null
| null
| null
| 2
| Sao Paulo
|
| 4
| John
| 4
| 4
| Paris
|
| null
| null
| null
| 5
| London
|
| null
| null
| null
| 6
| Rome
|
| 8
| Harry
| 9
| 9
| Madrid
|
Observe now that records with key1 equal
to 6 and 7 no longer appear in the result set. This is because they have no
correspondent record in the right table. There are 4 records showing NULL
values on the first fields, because they are not available in the left table.
The CROSS JOIN
A CROSS JOIN is in fact a Cartesian product. Using CROSS JOIN
generates exactly the same output of calling two tables (separated by a comma)
without any JOIN at all. This means we will get a huge result set, where each
record of Table1 will be duplicated for each record in Table2. If Table1 has N1
records and Table2 has N2 records, the output will have N1 times N2 records.
I don't believe there is any way to represent this output in a
Venn diagram. I guess it would be a three dimensional image. If this is really
the case, the diagram would be more confusing than explanatory.
The syntax for a CROSS JOIN will be:
SELECT t1.key1, t1.field1 as Name, t1.key2 as T1Key,
t2.key2 as T2Key, t2.field1 as City
FROM Table1 t1
CROSS JOIN Table2 t2 ;
As Table1 has 5 records and Table2 has
another 7, the output for this query will have 35 records (5 x 7).
Please check the attached file (SQLServerCentral.com_JOIN_CrossJoin.rpt).
Quite honestly, I don't remember at this very moment not a
single real-life situation that I do need to generate a Cartesian product of
two tables. But whenever you need, CROSS JOIN is there, anyway.
Besides, you should be concerned about performance. Say you
accidentally run in your production server a query with a CROSS JOIN over two
tables with 1 million records. This is surely something that will give you a
headache. Probably your server will start showing performance problems, as your
query might run for some time consuming a considerable amount of the server
resources.
The SELF JOIN
The JOIN operator can be used to combine any pair of tables,
including combining the table to itself. This is the "self join".
Self joins can use any JOIN operator.
For instance, check this classical example of returning an
employee's boss (based on Table1). In this example, we
consider that the value in field2 is in fact the boss'
code number, therefore related to key1.
SELECT t1.key1, t1.field1 as Name,
t1.field2, mirror.field1 as Boss
FROM Table1 t1
LEFT JOIN Table1 mirror ON t1.field2 = mirror.key1;
And this is the output to this query.
| key1
| Name
| field2
| Boss
|
| 3
| Erik
| 8
| Harry
|
| 4
| John
| 3
| Erik
|
| 6
| Mark
| 3
| Erik
|
| 7
| Peter
| 8
| Harry
|
| 8
| Harry
| 0
| null
|
In this example, the last record shows that Harry has no boss,
or in other words, he is the #1 in the company's hierarchy.
Excluding the Intersection of the Sets
Checking the previous Venn diagrams I just showed above, one may
come to a simple question: what if I need to get all records from Table1 except
for those that match with records in Table2. Well,
this is pretty useful in day-to-day business, but obviously we don't need a
special JOIN operator to do it.
Observe the result sets above and you will see you only need to
add a WHERE clause to your SQL statement, looking for records that have a
NULL
value for Table2's key. So, the result set we are looking is the red area shown
in the Venn diagram below (Figure 6).
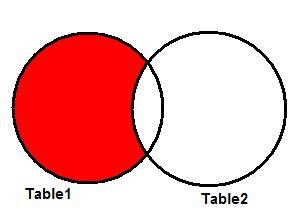
Figure 6: Non-matching records from Table1.
We can write a LEFT JOIN for this query, for instance:
SELECT t1.key1, t1.field1 as Name, t1.key2 as T1Key,
t2.key2 as T2Key, t2.field1 as City
FROM Table1 t1
LEFT JOIN Table2 t2 ON t1.key2 = t2.key2
WHERE t2.key2 IS NULL;
And, finally, the result set will be:
| key1
| Name
| T1Key
| T2Key
| City
|
| 6
| Mark
| 7
| null
| null
|
| 7
| Peter
| 8
| null
| null
|
When we do this kind of query, we have to pay attention to which
field we pick for the WHERE clause. We must use a field that does not allow
NULL values. Otherwise the result set may include unwanted records. That's why
I suggested to use the second table's key. More specifically, its primary key.
Since primary keys don't accept NULL values, they will assure our result set
will be just what we needed.
One Word about Execution Plans
These comments lead us to an important insight. We usually don't
stop to think about this, but observe that the execution plan of SQL queries
will first calculate the result set for the FROM clause and the JOIN operator
(if any), and then the WHERE clause will be executed.
This is as true for SQL Server as any other RDBMS.
Having a basic understanding of how SQL works is important for
any DBA or developer. This will help you to get things done. In fast and
reliable way. If you are curious about this, just take a look in the execution
plan for the query above, shown
Joins and Indexes
Take a look again at the Execution Plan of that query. Notice it
used the clustered indexes of both tables. Using indexes is the best way to
make your query run faster. But you have to pay attention to some details.
When we write our queries, we expect the SQL Server Query
Optimizer to use the table indexes to boost your query performance. We can also
help the Query Optimizer choose the indexed fields to be part of your query.
For instance, when using the JOIN operator, the ideal approach
is to base the join condition over indexed fields. Checking again the Execution
Plan, we notice that the clustered index on Table2 was
used. This index was automatically built on key2 when
this table was created, as key2 is the primary key to that
table.
On the other hand, Table1 had no
index on field key2. Because of that, the query optimizer tried to be smart enough
and improve the performance of querying key2 using
the only available index. This was the table clustered index, based on key1, the
primary key on Table1. You see the query optimizer is really a smart tool. But you
would help it a lot creating a new index (a non-clustered one) on key2.
Remembering a bit about referential integrity, you see key2 should
be a foreign key on Table1, because it is related to another field in other table (which
is Table2.key2).
Personally I believe foreign keys should exist in all real-world
database models. And it is a good idea to create non-clustered indexes on all
foreign keys. You will always run lots of queries, and also use the JOIN
operator, based on your primary and foreign keys.
(Important: SQL Server will automatically create a clustered
index on primary keys. But, by default, it does nothing with foreign keys. So
make sure you have the proper settings on your database).
Non-equal Comparisons
When we write SQL statements using the JOIN operator, we usually
compare if one field in one table is equal to another field in the other table.
But this is not the mandatory syntax. We could use any logical operator, like
different than (<>), greater than (>), less than (<) and so on.
Although this fancy stuff might give you the impression that SQL
gives so much power, I feel this is more like a cosmetic feature. Consider this
example. See Table 1 above , where we have 5 records. Now let's consider the
following SQL statement.
SELECT t1.key1, t1.field1 as Name, t1.key2 as T1Key,
t2.key2 as T2Key, t2.field1 as City
FROM Table1 t1
INNER JOIN Table2 t2 ON t1.key2 <= t2.key2
WHERE t1.key1 = 3 ;
Notice this uses an inner join and we are specifically picking
one single record from Table1, the one where key1 is
equal to 3. The only problem is that there are 6 records and Table2 that
satisfy the join condition. Take a look in the output to this query.
| key1
| Name
| T1Key
| T2Key
| City
|
| 3
| Erik
| 1
| 1
| New York
|
| 3
| Erik
| 1
| 2
| Sao Paulo
|
| 3
| Erik
| 1
| 4
| Paris
|
| 3
| Erik
| 1
| 5
| London
|
| 3
| Erik
| 1
| 6
| Rome
|
| 3
| Erik
| 1
| 9
| Madrid
|
The problem with non-equal joins is that they usually duplicate
records. And this is not something you will need in a regular basis. Anyway,
now you know you can do it.
Multiple JOINs
SQL JOINs are always about putting together a pair of tables and
finding related objects that obey a given rule (usually, but not limited to,
equal values). We can join multiple tables. For instance, to combine 3 tables,
you will need 2 joins. And a new join will be necessary for each new table. If
you use a join in each step, to combine N tables, you will use N-1 joins.
One important thing is that SQL allows you to use different
types of joins in the same statement.
But DBAs and developers have to be careful on joining too many
tables. Several times, I have seen situations where queries demanded 10, 20
tables or even more. For performance reasons, it is not a good idea to do a
single query to put all data together. The query optimizer will do a better job
if you break your query it into several smaller, simpler queries.
Now consider we have a third table, called Table3, shown below.
Table 3
| key3
| field1
|
| 1
| Engineer
|
| 2
| Surgeon
|
| 3
| DBA
|
| 4
| Lawyer
|
| 5
| Teacher
|
| 6
| Actor
|
Now let's write a statement to bring the employee's name, the
city where he lives and what is his profession. This will demand us to join all
3 tables. Just remember that joins are written in pairs. So first we will join Table1 to Table2. And
then we will join Table1 and Table3. The resulting script is shown below.
SELECT t1.key1, t1.field1 as Employee,
t2.key2, t2.field1 as City,
t3.key3, t3.field1 as Profession
FROM Table1 t1
INNER JOIN Table2 t2 ON t1.key2 = t2.key2
INNER JOIN Table3 t3 ON t1.key3 = t3.key3;
As we are running only INNER JOINs, we will have only records
that match the combination of the 3 tables. See the output below.
<>div cl
| key1
| Name
| key2
| City
| key3
| Profession
|
| 3
| Erik
| 1
| New York
| 6
| Actor
|
| 4
| John
| 4
| Paris
| 4
| Lawyer
|
| 6
| Harry
| 9
| Madrid
| 2
| Surgeon
|
Beyond the SELECT statements
The use of JOIN operators is not restricted to SELECT
statements. In T-SQL, you can use joins in INSERT, DELETE, and UPDATE statements
as well. But keep in mind that in most RDBMSs we have nowadays, joins are not
supported on DELETE and UPDATE statements. So I would advise you to restrict
the use of joins to SELECT and INSERT statements only, even in SQL Server code.
This is important if you want to keep your scripts more easily portable to
different platforms.

