Contents
- Introduction
- Neural network variables
- Running a neural network
- Initializing a neural network
- Initialization variables
- The network mask
- Selecting the A matrix
- Setting up the equations
- Solving w[k] when c >= r
- Solving w[k] when c < r
- Training a neural network
- Learning algorithms
- Over-saturated inputs
- Under-saturated inputs
- Conclusion
- Points of contention
- Points of interest
- Future directions
- References
- Bibliography
Introduction
There has been a lot of work done on neural networks, most of which will give you a set of probabilities with the highest probability being the selected choice. However, this article will deal with neural networks where neurons can only be activated or not activated, with no in-between. The inspiration for this comes from neurology, and hopefully will be as useful as other types of neural networks.
Most neural networks consist of three layers: an input layer, a hidden layer and an output layer, the neural networks in this article are similar, however, the neurons in the hidden layer are able to be connected with each other and don’t need to be connected to either the input layer or the output layer.
Because of the mathematical content of this article, counting will begin with the number one (1), while counting in the code will begin with zero (0). This way of doing things was chosen for clarity, and hopefully it’s not too confusing.
Neural network variables
These are the variables used for neural networks:
n - The neural network has n neurons.
i - The length of the input vectors.
o - The length of the output vectors.
W - An n*n matrix, where W[k][j] is the synapse weight from the jth neuron to the kth neuron.
t - A vector of length n, where t[k] is the threshold (bias) of the kth neuron. t[k] must be greater than zero when k > i, so that neurons can’t activate themselves. t[k] where k <= i, can be set to anything because they correspond to the thresholds of the input neurons and are not used.
- a - A vector of length n, a[k] is 0 if the kth neuron is not activated and is 1 if it is.
Running a neural network
Running a neural network is the process where a binary input vector (I) of length i is inputted into the network and a binary output vector (O) of length o is outputted from the network. This is a three step process:
for (k = 1 to i) a[k] = I[k]
for (k = i+1 to n) if (DotProduct(W[k], a) >= t[k]) a[k] = 1
for (k = n-o+1 to n) O[k + o - n] = a[k]
Example: The XOR problem
According to my book (Enchanted Looms, Consciousness networks in brains and computers; By Rodney Cotterill; 1998) in 1957 a man called Andrei Kolmogorov devised a theorem which was used to show that a neural network could act as an XOR logic operator, so long as the network contained a hidden neuron. The XOR network in the book looks like this (Although the weights and biases are slightly different):
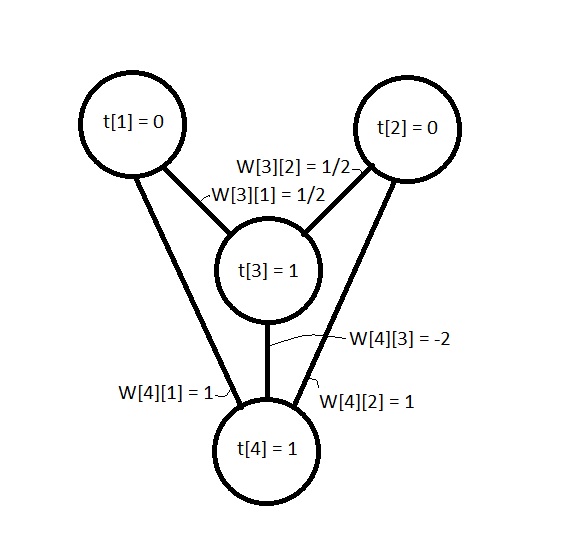
Figure 1. The XOR network and its weights and thresholds biases).The weight matrix for the XOR network is:

And its threshold vector is:
If we follow the three steps for running a neural network and let the input vector (I) be [0, 1] or [1, 0] then:
- a = [0, 1, 0, 0] or [1, 0, 0, 0]
- W[3] (dot) a = ½ which is less than t[3] so a[3] remains zero. W[4] (dot) a = 1 which is greater than or equal to t[4] so set a[4] to 1.
- Therefore O = [1] for both inputs, which is consistent with the XOR logic operator.
If we let I = [1, 1] then:
- a = [1, 1, 0 , 0]
- W[3] (dot) a = ½ + ½ = 1 which is greater than or equal to t[3] so set a[3] to 1, now a = [1, 1, 1, 0]. W[4] (dot) a = 1 + 1 – 2 = 0 which is less than t[4] so a[4] remains zero.
- Therefore O = [0] for the inputs [1, 1] which is also consistent with the XOR logic operator.
Initializing a neural network
The reason for initializing a neural network is to provide a framework which allows the network to learn. The initialization process involves using basic data inputs and outputs. For example, if you wanted it to learn what different letters look like, you’d use some basic looking ‘a’, ‘b’, etcetera, as the basic data inputs, and the ‘concepts’, for lack of a better word, of ‘a’, ‘b’, etcetera, for the basic data outputs. After the network has been initialized the training phase can begin, where the network is trained with all the variations of what ‘a’, ‘b’, etcetera, can look like.
The run process involves multiplying the rows of a weight matrix with an activation vector, however, with the initialization process we would like to find what the entries of the weight matrix are, as well as the thresholds. To do this an activation matrix (A) is created where its columns are activation vectors for the basic data inputs and outputs, this matrix can then be used to create a set of linear equations whose solutions are the entries of the weight matrix.
Initialization Variables
The variables used to initialize a neural network are:
r - The number of input/output pairs.
c - The number of non-NULL entries in the kth row of the network mask.
A - An n*r matrix, where each column represents an activation vector (a).
T - An n*r matrix, where T[k][j] = DotProduct(W[k], A[j]). T[k][j] >= t[k] if A[k][j] = 1 and T[k][j] < t[k] if A[k][j] = 0.
The network mask
The network mask is the weight matrix (W) before the initial weights have been found. It is used to know which weights or synapses are allowed to exist. An entry in the network mask is zero (0) if the synapse is allowed to exist or is NULL (N) if it is not. The regions of the weight matrix are:
Figure 2. The regions of the network mask.
Example: The XOR problem
The network mask for initializing the XOR problem would look like:
Here N is used to represent NULL, i.e. the synapse cannot exist.
Selecting the A matrix
The A matrix represents the pathways through the neural network and is used as the matrix for a set of linear equations where the solutions are the weights of the weight matrix, in order to have the highest number of solutions the rows of the A matrix should be linearly independent. The regions of the A matrix are.
Figure 3. The A matrix and its regions.
While I was trying to figure out how this stuff works I came to the conclusion that the rows of A are binary code words and need to be linearly independent in binary, or for mathematicians, the field F2(q). This is where 1 + 1 = 0 without carrying the 1, so 101 + 110, for example, would be 011. However, I’m not sure about this.
Since the elements of A can only ever be 0 or 1 linear independence of the rows can be achieved by having the amount of 1’s in each row be an odd number. This should work for the weights in the hidden layer but may cause problems for the weights connecting the input layer to the hidden layer if the rows representing the inputs are not linearly independent.
Example: The XOR problem
There are multiple choices for the A matrix. After putting in the input vectors and output vectors the A matrix looks like:
Since there are 4 rows and only 3 columns we can’t make all the rows of A be linearly independent, however, we only need the first 3 rows to be linearly independent. This is due to the selection of the network mask which has all the entries in the last column set to NULL.
There are 4 options for the 3rd row, they are: [1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 1, 1]. These will make the first 3 rows linearly independent. We can use any of these vectors, although the resulting networks will be slightly different, each with different weights, they will all be isomorphic networks. Using one of the unlisted options for the 3rd row will result in a solution where t[3] or t[4] will not be greater than zero.
For this example the vector [0, 0, 1] will be chosen to be consistent with the XOR example given in the run section. The A matrix is:
Setting up the equations
We know whether a neuron is activated depending on the other neurons in a network from the activation matrix (A). We also know which connections (synapses) can exist and which ones can’t from the network mask. This means that we know that DotProduct(A[j], W[k]) is greater than or equal to t[k] if A[k][j] = 1, or less than t[k] if A[k][j] = 0.
Since we know that MatrixProduct(W, A) = T, we know from matrix algebra that MatrixProduct(AT, WT) = TT. This lets us set up linear equations for each row of W which take the form:
Essentially what’s happening is that for each neuron in the network we find the weights of the synapses into the neuron based on which neurons are activated and when. Given that we know when the neuron is activated and when it’s not we can create a set of linear equations.
Solving W[k] when c >= r
The columns of AT are linearly independent since they correspond to the rows of A, and the number of rows (r) of AT are less than the number of columns (c). This means that the number of solutions to the set of linear equations MatrixProduct(AT, WT[k]) = TT[k] spans the entire vector space. This allows us to set t[k] to whatever we like and the elements of TT[k] to any vector which satisfies its constraints.
Example: The XOR problem
To find the 4th row of the weight matrix we need to solve the linear equations:
After removing the columns of AT which correspond to the NULL entries of the network mask the set of equations looks like:
Since we can set TT[k] to whatever we like within its constraints, we may as well let TT[4] = AT[4] and t[4] = 1. And so we have:
Which gives W[4][1] = 1, W[4][2] = 1 and W[4][3] = 0 – W[4][1] – W[4][2] = 0 – 1 – 1 = -2. Therefore W[4] = [1, 1, -2, N].
Solving W[k] when c < r
In this case finding the weights of the synapses is a bit trickier. The process involves three steps:
Find a c-dimensional linear subspace in r-dimensions formed by the columns of AT.
Find a vector TT[k] which exists in the c-dimensional linear subspace and satisfies its constraints.
Solve the linear equations MatrixProduct(AT, WT[k]) = TT[k] to get the weights.
Example: The XOR problem
To find the 3rd row of the weight matrix we need to solve the linear equations:
After removing the columns of AT which correspond to the NULL entries of the network mask the set of equations looks like:
Since c=2 and r=3 the c-dimensional linear subspace in r-dimensions is just a 2D plane in 3D. The cross product for the columns of AT is CrossProduct(AT[1], AT [2]) = [1, 1, -1], Therefore the 2D plane is x + y – z = 0.
A suitable vector for TT[3] is [½, ½, 1], where t[3] = 1. Since DotProduct([1, 1, -1], [½, ½, 1]) = 0, TT[3] lies on the plane formed by the columns of AT. However, the entire set of solutions can be described by 0 < W[3][1] <= W[3][2] < t[3] <= W[3][1] + W[3][2].
The upper part of AT is already in echelon form so we can just read off W[3] = [½, ½, N, N].
Training a neural network
There are many different learning algorithms that people have developed over time, the most popular being the backward propagation algorithm for neural networks. The problem I feel is not with the algorithms themselves but with the initializing of the network, which to my knowledge consists of creating random weights and thresholds (biases).
Ideally, once a network has been initialized with a basic data set, it would then be able to learn a more extensive training set of data. This would allow the network to develop a more complex set of associations between its inputs and outputs, giving it the ability to give more accurate outputs to ‘noisier’ inputs.
A good article called Neural Networks on C# by Andrew Kirillov lists some of the learning algorithms and is available at http://www.codeproject.com/Articles/16447/Neural-Networks-on-C
A learning algorithm
A fairly basic learning algorithm involves three steps:
Run the network with the desired input vector (I)
Regardless of the outputs given, change the output neurons to the desired output vector (O)
For (k = n to k = i + 1) {For (j = 1 to n) if (a[k] && a[j] && W[k][j] != NULL) W[k][j] += learningRate*(t[k] - DotProduct(W[k], a))else if (!a[k] && a[j] && W[k][j] != NULL) W[k][j] -= learningRate*(t[k] - DotProduct(W[k], a))}
If the desired input vector resembles one of the input vectors from when the network was initialized, then the desired input vector (I) which was inputted into the network should have activated some of the pathways created during the initialization, allowing a learning algorithm like this to have at least some success.
The pathways which were used in associating the inputs to the outputs should be stronger, while the pathways which weren’t used would weaken. This allows for a kind of natural selection in the pathways, where the ones which are used remain, and the ones that aren’t die out.
Over-saturated inputs
Here I use the term ‘over-saturated’ to describe when the input vector (I) has too many activated neurons. Here is an example of over-saturated inputs for the letter ‘A’.
Figure 4. An example of an over-saturated ‘A’.
This, however, shouldn’t be a problem over a large set of data, where the strength the associations of the desired outputs to the noise in the inputs would not be as strong as the associations to the desired inputs.
Under-saturated inputs
An under-saturated input describes when the input vector (I) doesn’t have enough activated neurons. This may present a problem when it comes to learning, as the pathways from the inputs to the outputs may not have been activated. Here is an example of under-saturated inputs for the letter ‘A’.
Figure 5. An example of an under-saturated ‘A’.
The solution here may be in the selection of the network mask used for initializing the network. If a network is designed to have many pathways from the desired inputs to outputs which don’t interact with each other it might be possible to get the desired outputs from pieces of the inputs. This may be possible by creating a network where the neurons are clustered into groups where the neurons aren’t connected to each other, although this is speculation. The network mask for this might look like:
Figure 6. What the network mask might look like.
conclusion
In conclusion, neural networks of the type where neurons can only be activated or not activated can be represented by a matrix for the synapse weights and a vector for the thresholds (biases). The state of the neurons in a neural network, i.e. whether or not they’re activated, can also be represented by a vector. These properties can be used to create a set of linear equations whose solutions can be used to initialize a neural network, and once initialized the network can (hopefully) learn from associated inputs and outputs.
Following are some points of contention, points of interest, and future directions which have not been covered in this article, but which I feel I should mention:
Points of contention
- Incomplete code – The NNInitializer class is incomplete, there is no code for the c < r case. This is because I don’t have the knowledge or skills required to be able to figure it out, and try as I might, couldn’t find it already done for me anywhere.
- Testing – I haven’t tested the code outside of the XOR problem, but like anyone who hasn’t tested their code, I’m sure it works.
- When c > the total number of columns in the full A – There may be an error if the number of non-NULL entries in any row of the network mask is greater than the number of columns in the activation matrix, this may be corrected by reducing the maximum number of non-NULL entries in any row of the weight matrix that can exist or by adding more columns to A.
Points of interest
- Associations – People who study the brain like to say that the brain learns through associations, with neural networks the inputs are associated with the outputs. It would be interesting to see if it’s possible to have a ‘string’ of associations. I.e. A is associated with B is associated with C and so forth.
- Coding theory – The branch of mathematics that allows the internet and cell phones to communicate clearly may be closely related to neural networks. A parity check matrix for a binary linear code may be used as the part of the activation matrix that represents the hidden layer of neurons.
Also a parity check input neuron may be added to the basic input vectors used for initializing a neural network. This neuron would give each basic input vector an odd weight, which may make the rows of the activation matrix which represent the input neurons linearly independent.
And finally, parity check neurons could be added to the output layer of neurons, which could then be passed through a syndrome decoder to detect or correct any errors in the outputs.
Future directions
- Cognitive mechanics – I figured I had better ‘coin a term’ while the getting’s good. Cognitive mechanics is the field of study between neural networks and artificial intelligence. It deals with defining the set of inputs and outputs, as well as what the network mask should be for any given application.
- Node reduction – I think it would be interesting if it were possible to find the smallest number of neurons for a network that doesn’t affect its operation, and then reduce the number of neurons in an existing network to that size.
- Hidden layer inputs – being able to manually activate and deactivate neurons in the hidden layer in order to have a ‘string’ of associations.
- Neurotransmitters – The brain has a whole bunch of neurotransmitters, and each neuron has different receptors for each one. Modelling these using neural networks could be done by using different weight matrices for each neurotransmitter while keeping only one threshold vector and one activation vector.
Each matrix would give the weights for only one neurotransmitter and running the network would involve adding the weights of each matrix for a single neuron before doing the same for the next neuron. However, I’m not sure how initialization and learning would be accomplished with these types of neural networks.
References
Bibliograpgy
- A first course in coding theory; By Raymond Hill; 1986
- Biological Psychology; By James W. Kalat; 2009

