New: Regex Logviewer has a Codeplex page, you are welcome to join in.
Update: Version 1.4 is a complete refactoring of all the code:
- Added AutoDetect mode which automatically integrates different logs into one view
- Log processing was separated out to a detachable engine component
- Removed the use of datasets from the code
- Added search with Ctrl+F
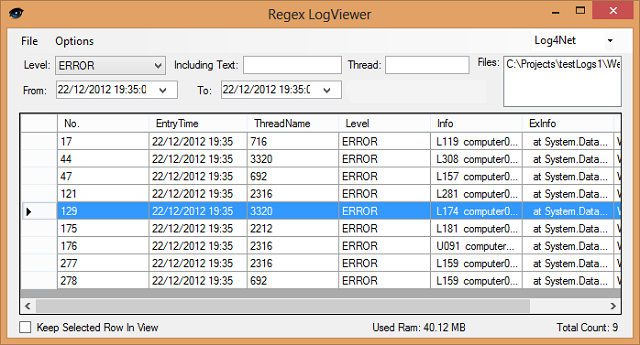
Introduction
Logs hold a huge amount of information, especially today when servers get thousands of requests every minute, but sifting through this information is hard and unrewarding, as logs are full of junk lines and wrongly stated levels, this problem is compounded when you think of multiple servers, log partitioning, and multi system architectures.
This logviewer is something that I have been writing a bit at a time for several years, in order to quickly sift and sort through logs, to get the information that I need when investigating a problem.
So here are some of the features regex logviewer has today:
- Uses regular expressions to parse your log (create your own parser, for any log)
- Performance & memory optimized
- Handles up to a million loglines (and more)
- Live listening to log changes
- Automatically detects the correct parser to use on a given file
- Supports Drag and Drop
- Can create CSV summaries from logs to show error distribution / importance
- Support multiple sorts and filters
- Able to integrate many log files into a unified interface
- Can associate with the .log FileType
- Codepage adjustable via config / AutoDetection if no config exists
- Able to collect log files from multiple machines / directories
- Tested and working on winXp, win7, win8
Background
My log viewer project started somewhere in 2007, when I needed a good logviewing tool, and couldn't find anything decent to match my requirements (simple user interface, fast parsing, and all the sorts/filters I could ask for).
After several tours online, I was very surprised that I didn't catch any great apps to do my job for me, and I decided to write my own - as many people have done before me (two other logviewers already existed in the project I worked on then, but were not in use for being too complex, heavy or obsolete).
The first version featured a hardcoded parser for my log format which was rather complex since it needed to cope with the maddening exceptions which break the traditional logline format. Nevertheless, it worked and several features such as live listening were quick to follow.
After moving around a bit, I got the idea that a hard coded parser is a waste of a good display/filter infrastructure, and in order to make it more generic, I moved the parsing code to use regular expressions which after learning about regex lookahead, handle all non XML log structures very well, (flat XML structures are ok, but tree-like XMLs don't play well with this method).
Configuring the Program
The log behavior configuration is stored in the BehaviorConfig.xml file in the same directory of the executable, and holds XML entries which look like this:
<LogBehavior>
<BehaviorName>STLog4Net</BehaviorName>
<Grade>0</Grade>
<DateFormat>yyyy-MM-dd HH:mm:ss,fff</DateFormat>
<ParserRegexPatternCData><![CDATA[</ParserRegexPatternCData>
<ParserRegexOptionsString>IgnoreCase Multiline Singleline</ParserRegexOptionsString>
</LogBehavior>
- The regex is stored in a
cdata, since some of the characters in the regex can collide with XML chars (like'<') - When indentifying log sections, use the following group names, which are known to the logviewer:
date = the date, which should be in the date format stated in the <DateFormat> tag info = the info usually represented inside the log line exinfo = the exception lines that follow, or other extended information (one or more lines) level = the log level thread = the name/number of the thread user = the user for which the log is written (useful for app servers) machine = the computer name (if this exists in the log, good for reading multi log files)
- ParserRegexOptionsString contains the regex options which are:
IgnoreCase - Specifies case-insensitive matching Multiline - Multiline mode. Changes the meaning of ^ and $ so they match at the beginning and end of line Singleline - Changes the meaning of the dot (.) so it matches every character (instead of all except '\n') IgnorePatternWhitespace - Eliminates unescaped white space from the pattern RightToLeft - Specifies that the search will be from right to left instead of from left to right
- DateFormat - contains the format with which to parse the date in the logs
- Uses the C# date format, which is described here
- About the regex shown in the example above:
- Starting with a ^ (start) sign means we expect to start the match in the very beginning of a line.
- Several known named groups (see above), which look like this: (?<date> ....)
- In the end, we have a (?=) clause which is a lookahead, which matches only if the characters viewed from this point forward match the given pattern, the pattern stated is the date portion of the next log line, or \z = end of parsed string which means we complete a match when encountering a new log line or the end of the file (much like a human would do it), this is the magic that parses the exception lines and others which break the log file pattern.
Performance Pitfalls
I have used this logviewer successfully with as much as 500K distinct loaded log lines in memory, an it handles this quite well, with good performance both in memory consumption and speed (it does get quite large but not more than expected).
To get the most out of this tool, you might accept these tips as general guidelines:
- When parsing a long batch of files you should turn on a filter (such as
level=ERROR) to avoid slow parsing due to grid display events.
- Feeling lazy?
DefaultLogLevel = ERROR in the logViewer.exe.config file will change the default filter on startup.
- When handling huge amount of information, use batch collection to collect multiple server logs and use a line filter, this will filter the lines prior to importing, in contrast with regular filters which only change the grid view.
- Also, when entering many directories/server shares for batch processing, the *.lgs files (presets) are text files, so editing them is very easy, not requiring the GUI.
- When writing regex parsers, you should test them first with a regex program (like expresso or regex buddy), a regex will mostly be lightning fast, but a small change in code can make it a performance nightmare.
- Try to avoid .* and .+ as much as possible, use char classes,
- If you know how many chars use {1,5} to quantify the field length
- Fix the start position of your match to the start and end of the
string using boundaries
- When using logviewer to index a large number of active logs, you should turn off live listening, so not to get swamped by updates. you can use "
LiveListeningOnByDefault = False" in the LogViewer.exe.config to turn it off by default.
About the Code
Though mostly non-complex, the code has some interesting points:
- The live listening procedure saves the position in each log line, and polls periodically for changes.
- If log is smaller than remembered position, parsing starts from the beginning, since this usually indicates a log was wiped and recreated or cycled (the old log moved to log.1 and the log file was recreated to avoid huge log files).
- Below you can see the timer tick code which does the polling:
private void timer1_Tick(object sender, EventArgs e)
{
List<string> list = new List<string>();
list.AddRange(m_colWatchedFiles.Keys);
foreach (string file in list)
{
long lngPrevLength = m_colWatchedFiles[file];
if (File.Exists(file))
{
long lngFileLength = (long)new FileInfo(file).Length;
if (lngPrevLength > lngFileLength)
{
m_colWatchedFiles[file] = 0;
lngPrevLength = 0;
}
if (lngPrevLength < lngFileLength)
{
long lngNewLength = ParseLogFileRegExp(file, lngPrevLength);
m_colWatchedFiles[file] = lngNewLength;
if (!chkPinTrack.Checked && dataGridView1.Rows.Count > 0)
dataGridView1.FirstDisplayedCell = dataGridView1.Rows[0].Cells[0];
}
}
}
lblCount.Text = "Total Count: " + m_dvMainView.Count;
lblMemory.Text = "Used Ram: " + ((double)Process.GetCurrentProcess().WorkingSet64 /
1000000d).ToString(".00") + " MB";
}
- Core parsing is done into a
DataTable which eases the filtering and binding to a datagrid. I toyed around with converting it into Linq+WPF, and I still might do this, but that will take time and then I would have to work on its performance again. - About performance, a few tweaks were made:
- Since data row is created before filtering, and since I found a
DataRow creation attaches it to the table it's created from - I use a dummy table to create the rows, and then import them into the real table only if they match the filter (sort of like using an intermediary struct), the dummy table is later disposed, preventing memory overconsumption. - Memory consumption is monitored and reported in the bottom of the main form.
- A further boost in performance might come from multi threading the parsing, but since
DataTables are absolutely not thread safe, a simpler (poco entities) data structure should be called for, which means much more work. - All of this said, it works pretty smooth, it isn't broken so why fix it?
ProgressBarManger is a static class that maintains an instance of a Form with a progressBar in a different GUI thread, which makes it responsive even when the program is under heavy load.
- An invocation to the correct thread is made for each progress update, and updates are kept to a minimum by limiting the amount of steps and checking that the step was changed. (so if you have 100 steps, only 100 incremental changes can be made).
See the progressBarManager code below:
public static void CreateInThread()
{
m_frm = new FrmProgressBar();
m_frm.SetLableText(m_labelText);
m_frm.SetTotalProgressSteps(m_intProgressSteps);
Thread t = new Thread((ThreadStart)delegate
{
Application.Run(m_frm);
});
t.SetApartmentState(ApartmentState.STA);
t.IsBackground = true;
t.Start();
while (m_frm.Visible == false)
Thread.Sleep(50);
}
public static void ShowProgressBar(long intFullProgressBarValue)
{
if (m_frm ==null)
CreateInThread();
m_intFullProgressBarValue = intFullProgressBarValue;
m_frm.Invoke((ThreadStart)delegate
{
if (!m_frm.Visible)
m_frm.Show();
m_frm.ProgressBarControl.Value = 0;
});
}
static string m_labelText = "Adding Files";
public static void SetLableText(string text)
{
m_labelText = text;
if (m_frm != null)
{
if (m_frm.InvokeRequired)
{
m_frm.Invoke((ThreadStart)delegate
{
m_frm.SetLableText(text);
});
}
else
{
m_frm.SetLableText(text);
}
}
}
public static void SetProgress(long intermediateValue)
{
int newValue = (int)(((double)intermediateValue /
(double)m_intFullProgressBarValue) * (double)m_intProgressSteps);
if (newValue > m_intProgressSteps)
newValue = m_intProgressSteps;
m_intIntermediateValue = intermediateValue;
if (newValue > m_intPrevValue && m_frm!=null)
{
if (m_frm.InvokeRequired)
{
m_frm.Invoke((ThreadStart)delegate
{
m_frm.ProgressBarControl.Value = newValue;
m_intPrevValue = m_frm.ProgressBarControl.Value;
m_frm.SetLableText(m_labelText);
m_frm.Invalidate();
m_frm.Refresh();
});
}
else
{
m_frm.ProgressBarControl.Value = newValue;
m_frm.SetLableText(m_labelText);
}
m_intPrevValue = newValue;
Application.DoEvents();
}
}

