Introduction
Apriori is an algorithm to learn frequent item set and association rule. Apriori is a bottom-up method, which extends an object to frequent item set at each iteration. When there is no object to be extended, algorithm terminates.
Apriori Model
Frequent itemset
Frequent itemset is the set of objects which usually occur simultaneously.
The traditional method will be traversing the dataset several times. To reduce the computation, researchers identified something called the Apriori principle. The Apriori principle helps us reduce the number of possible interesting itemsets. The Apriori principle says that if an itemset is frequent, then all of its subsets are frequent. It does not seem useful at first sight. However, if we turn it inside out, it says if a itemset is not frequent, all of its supersets are not frequent. It means that in the bottom-up process, if the bottom itemset is not frequent, we don't need to process the set at top. For example, there exists a set A= {1, 2, 3, 4}. All possible itemsets generated by A are shown below:
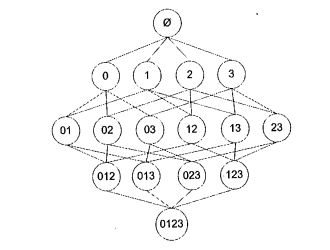
If itemset {0, 1} is not frequent, all the itemsets which contain {0, 1} are not frequent, which means that we can skip these itemset as marked with blue circle.

The generation of frequent itemset includes the following steps:
- First, calculate the singleton set. All the elements are regarded as the candidate set.
def createSingletonSet(self, data):
singleton_set = []
for record in data:
for item in record:
if [item] not in singleton_set:
singleton_set.append([item])
singleton_set.sort()
singleton_set = list(map(frozenset, singleton_set))
return singleton_set
- Merge singleton set to generate more candidate set.
def createCandidateSet(self, frequent_items, k):
candidate_set = []
items_num = len(frequent_items)
for i in range(items_num):
for j in range(i+1, items_num):
L1 = list(frequent_items[i])[: k-2]
L2 = list(frequent_items[j])[: k-2]
if L1 == L2:
candidate_set.append(frequent_items[i] | frequent_items[j])
return candidate_set
- Calculate the support degree of all the candidate sets and select candidate sets whose support degrees are larger than the minimum support degree as the frequent itemsets.
def calculateSupportDegree(self, data, candidate_set):
sample_sum = len(data)
data = map(set, data)
frequency = {}
for record in data:
for element in candidate_set:
if element.issubset(record):
frequency[element] = frequency.get(element, 0) + 1
support_degree = {}
frequent_items = []
for key in frequency:
support = frequency[key]/sample_sum
if support >= self.min_support:
frequent_items.insert(0, key)
support_degree[key] = support
return frequent_items, support_degree
- Combination of the above functions:
def findFrequentItem(self, data):
singleton_set = self.createSingletonSet(data)
sub_frequent_items, sub_support_degree =
self.calculateSupportDegree(data, singleton_set)
frequent_items = [sub_frequent_items]
support_degree = sub_support_degree
k = 2
while len(frequent_items[k-2]) > 0:
candidate_set = self.createCandidateSet(frequent_items[k-2], k)
sub_frequent_items, sub_support_degree =
self.calculateSupportDegree(data, candidate_set)
support_degree.update(sub_support_degree)
if len(sub_frequent_items) == 0:
break
frequent_items.append(sub_frequent_items)
k = k + 1
return frequent_items, support_degree
Association Rule
Association rule is that something takes place leading to other things happening. For example, there is a frequent itemset {beer, diaper}. There may be a association rule diaper->beer, which means that someone buy diaper may also by beer. Note that the rule is unidirectional, which means rule beer->diaper may be not correct.
The generation of association rule includes the following steps:
- Calculate the confidence degree of each frequent itemset, and choose the itemsets whose confidence degree are larger than the mimimum confidence degree.
def calculateConfidence(self, frequent_item, support_degree, candidate_set, rule_list):
rule = []
confidence = []
for item in candidate_set:
temp = support_degree[frequent_item]/support_degree[frequent_item - item]
confidence.append(temp)
if temp >= self.min_confidence:
rule_list.append((frequent_item - item, item, temp))
rule.append(item)
return rule
- Merge frequent itemsets to generate more association rules:
def mergeFrequentItem(self, frequent_item, support_degree, candidate_set, rule_list):
item_num = len(candidate_set[0])
if len(frequent_item) > item_num + 1:
candidate_set = self.createCandidateSet(candidate_set, item_num+1)
rule = self.calculateConfidence
(frequent_item, support_degree, candidate_set, rule_list)
if len(rule) > 1:
self.mergeFrequentItem(frequent_item, support_degree, rule, rule_list)
- Combination of the above functions:
def generateRules(self, frequent_set, support_degree):
rules = []
for i in range(1, len(frequent_set)):
for frequent_item in frequent_set[i]:
candidate_set = [frozenset([item]) for item in frequent_item]
if i > 1:
self.mergeFrequentItem
(frequent_item, support_degree, candidate_set, rules)
else:
self.calculateConfidence
(frequent_item, support_degree, candidate_set, rules)
return rules
Conclusion and Analysis
Apriori is a simple algorithm to generate frequent itemsets and association rules. But it is more suitable sprase dataset. Now, we have a dataset as follows. Let's see the result of Apriori. The result is a tuple as (X, Y, confidence degree).
The related code and dataset in this article can be found in MachineLearning.

