Kafka
Kafka is a distributed publish-subscribe messaging system. Kafka is fast, scalable, and durable. It keeps feeds of messages in topics. Producers write data to topics and consumers read from topics.
Kafka ecosystem needs to be covered by Zookeeper, so there is a necessity to download it, change its properties and finally set the environment. After running Zookeeper, Kafka should be downloaded, then a developer will be able to create broker, cluster, and topic with the aid of some instructions.
What Is the Messaging System?
One of the most challenging parts of data engineering is how to collect and transmit the high volume of data from different points to the distributed systems for processing and analyzing. The enormous data needs to be decoupled properly via message queuing because if one part of data fails to be conveyed, the other data can be transmitted and analyzed when the system is recovered. There are two kinds of message queuing which are both reliable and asynchronous for the mentioned purpose. Point to point and publisher-subscriber.
Point to Point
In the point to point or one to one, there is one sender and multiple consumers who are listening to the sender. When one consumer receives a message from the queue, that specific message will disappear from the queue and other consumers cannot get it.
Publish and Subscribe System
While in the publisher-subscriber, the publisher sends a message to multiple consumers or subscribers who are listening to the publisher at the same time, and each subscriber can get the same message. Data should be transmitted through the data pipeline which is responsible to consolidate data from the sources.
What Is Kafka Architecture?
Kafka is distributed publisher-subscriber with the high throughput which can handle a high volume of data. Kafka is real-time data streaming and can process 2 million writes per second.
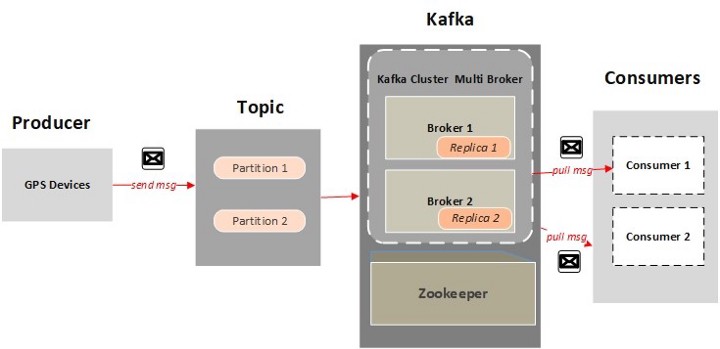
Kafka Architecture is as follows:
Topics and Publisher
There is a publisher which sends the message. Messages are categorized according to topics, there are one or more partitions for each topic with its own offset address. For example, if we assign the replication factor = 2 for one topic, so Kafka will create two identical replicas for each partition and locate it in the cluster.
Clusters and Brokers
Kafka cluster includes brokers — servers or nodes and each broker can be located in a different machine and allows subscribers to pick messages. Therefore, replications are such as back up for partition and it means that Kafka is persistent which helps to be fault tolerant.
Zookeeper
Kafka cluster does not keep metadata for its own ecosystem because it is stateless. Hence, Kafka has a dependency on the Zookeeper which keeps track of the metadata. Zookeeper should be started at first. Indeed, Zookeeper is an interface between brokers and consumers and its existence is necessary for fault tolerance. Kafka brokers are responsible for load balancing, assume there is one topic and multiple partitions for this topic, each partition has a leader which periodically confirms its offset from Zookeeper. Therefore, if one node or broker fails, Kafka can continue its operation from the last offset address that has been asked from Zookeeper, so Zookeeper has the vital role in Kafka recovery in the case of crashing scenario.
Kafka Triggering
- Download Kafka from this link: https://kafka.apache.org/downloads
- Kafka Configuration, go to the path:
- C:\kafka_2.11–0.10.2.0\config
server.properties- log.dirs=C:\kafka_2.11–0.10.2.0\kafka-logs
- listeners=PLAINTEXT://127.0.0.1:9092
zookeeper.properties- dataDir=C:\kafka_2.11–0.10.2.0\zookeeper
consumer.properties- zookeeper.connect=127.0.0.1:2181
- Download Zookeeper from this link: “zookeeper-3.4.13.tar.gz” https://archive.apache.org/dist/zookeeper/zookeeper-3.4.13/
- Start Zookeeper:
- cmd prompt
- cd C:\zookeeper-3.4.13\bin
- zkserver
- Start Kafka:
- cmd prompt
- cd C:\kafka_2.11–0.10.2.0
- Command: “.\bin\windows\kafka-server-start.bat .\config\server.properties”
- Create a Topic on Kafka:
- cmd prompt
- cd C:\kafka_2.11–0.10.2.0\bin\windows
- Command: “kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Topic-IoT”
- Delete Topic on Kafka:
- cmd prompt
- cd C:\kafka_2.11–0.10.2.0\bin\windows
- Command: “./bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic <TopicName>”
- Create a Producer on Kafka:
- cmd prompt
- cd C:\kafka_2.11–0.10.2.0\bin\windows
- Command: “kafka-console-producer.bat --broker-list localhost:9092 --topic Topic-IoT”
- Create Consumer on Kafka:
- cmd prompt
- cd C:\kafka_2.11–0.10.2.0\bin\windows
- Command: “kafka-console-consumer.bat --zookeeper localhost:2181 --topic Topic-IoT”
- Now whatever you write on “Producer” will be appeared on “Consumer”.

One Producer - Publisher and two Consumers or Subscribers
Kafka Management, Create Cluster and Topic
You can also use this link https://github.com/yahoo/kafka-manager in order to use visual configuration. You just need to configure hosts in windows:
C:\Windows\System32\drivers\etc\hosts
Append this line:
127.0.0.1 kafkaserver
Kafka vs Akka
History
- 20th June, 2019: Initial version

