Table of Contents
Introduction
This article is my entry for CodeProject's AI competition "Image Classification Challenge"[^]. My goal was to teach a neural network to play a game of tic tac toe, starting from only knowing the rules.
Tic tac toe is a solved game. A perfect strategy[^] exists so a neural network is a bit overkill and will not perform as well as existing programs and humans can. Nevertheless, with it being a simple game, it's a good one for starting to experiment with neural networks that train themselves a game.
The Playing Algorithm
Described from a high level: when the AI needs to make a move, it iterates over all possible moves, generates the board after making a given move, and uses the neural network to see how good the position is after performing that move. The neural network serves as an evaluation function: given a board, it gives its opinion on how good the position is. The move that would lead to the best position, as evaluated by the network, gets picked by the AI.
Neural network-based AIs for complexer games use a more elaborate search algorithm to decide on what the best move is. There, too, the neural network serves as an evaluation function to get a "static" measurement of how good a position is. For example, Leela Chess Zero uses a neural network as evaluation function with a Monte Carlo Tree Search as search algorithm. The search algorithm for the Tic Tac Toe AI is very shallow and looks only one move ahead.
The Network
The mathematics of neural networks is outside the scope of this article, but the basic concept is that a neural network consists of several "layers": an input layer, a couple of hidden layers, and an output layer. Every layer can be represented as a vector and consists of a specified number of units, called neurons. To transition from layer A and layer B, a matrix multiplication between layer A and a weight matrix is performed. An activation function[^] is applied on every element of the result of that multiplication (so the values of the neurons of layer B stay within certain bounds). The result of that is layer B. This process is repeated until the output layer is reached. (The activation function for this network is a bipolar sigmoid, which looks like a sigmoid[^] but with output values from -1 to 1 instead of 0 to 1.) The weight matrices are the core of the network: they decide what the output is going to look like. Based on inputs and known desired outputs, the values of the weight matrices can be adjusted. A common way to do that is with backpropagation[^] with gradient descent[^]. The "speed" of learning is decided by the learning rate[^] - you have to pick this value carefully: too high or too low and your network won't learn a lot!
The neural network has an input layer of 9 neurons (one for each square of the board), a couple of hidden layers (with 18, 9, and 3 neurons) and an output layer of one neuron, with a value between -1 ("I'm losing") and 1 ("I'm winning"). The values of the input layer consist of 0.01 (empty square), 1 ("me") and -1 ("the opponent").
Why 0.01 for an empty square, instead of just 0? I tried both, and 0.01 gave way better and more consistent results than 0 (see "Comparing network architecture and training processes" for evidence).
Why not something simpler, such as 1 for X and -1 for O as inputs, and as output 1 for "X is winning" and -1 for "O is winning"? It should be sufficient to derive whose turn it is just from that, because by convention X starts the game, so you should just count how many squares are filled and you have all information you need. This was an earlier attempt of mine and it looked like the neural network did not pick that up, despite performing well otherwise. I was playing a test game with it and this was a move by the network:
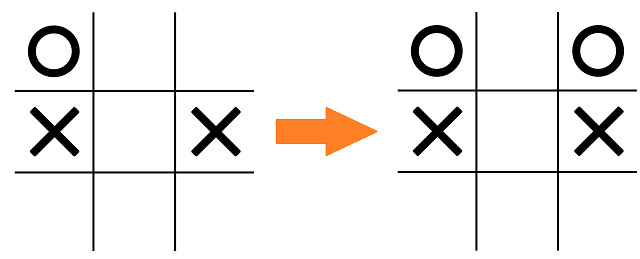
That's clearly a blunder, and in other positions where I threatened to win, it blocked my win fine. However, it does make some sense that it picked exactly this square: if O were to move, this position would be great. That makes it very likely that the network wasn't able to learn to infer who just moved.
Did the point-of-view representation really help? Yes and no. It helped in the sense that this position just didn't arise anymore (the network preferred capturing the center quickly) but when forcing that position on it, it still played it wrongly. That's not the worst issue when the position does not arise naturally anymore, but then this happened:

It neatly spotted the double attack, but completely neglected the fact that X was easily going to win next move. So this attempt didn't fix it either. Unfortunately, I didn't find a way to do better (without introducing a search algorithm) so I kept it like this (at least, it was somewhat better than the first board representation).
Another way I tried to fix the problem, instead of the point-of-view representation, was to add a tenth field to the input indicating whose turn it is. This did not perform nearly as well as the point-of-view representation, and did in fact even way worse than not having any indicator at all. Changing layer sizes or the learning rate of the network did not change much, the results stayed bad. I'm not entirely sure why.
The Training Process
To train the network, a high number of training games are played, between the AI and itself and between the AI and a randomly moving opponent. The training game cycle looks like this:
- AI vs AI
- AI vs Random
- Random vs AI
- AI vs AI
- Random vs AI
- AI vs Random
This cycle ensures game results of all types: ties, wins by X, and wins by O. Scratching the AI vs AI games diminishes the performance a bit, and the games between the AI and Random are essential: if the AI only plays itself, it didn't appear to be learning a lot. Trying this out with the final network configuration and learning rate, it seemed that the AI just found a way to tie against itself and then just reinforced that on the later training games. Playing a few games against it proved that it didn't learn anything.
To train the network, we use the AForge.NET[^] library, specifically its AForge.Neuro namespace. This library can be downloaded as a NuGet package:
Install-Package AForge.Neuro -Version 2.2.5
Comparing Network Architecture and Training Processes
Earlier, I said a few times that the network performed better or worse for certain changes in the training process or board representation. How can that be quantified? Just playing some games against it already gives a pretty good idea but does not always say a lot and gives you no idea about how the training process went, you can only evaluate the end result.
The results of the played training games are very telling for how the training progresses. When the training is going well, the network should tie when playing against itself and win when playing the random mover (in exceptional cases, the random mover may have played well enough to achieve a tie but we can consider this to be negligible). For every training game, we store a bit: 1 if the game result was "good" as described, 0 if the game result was "bad" (non-tie when playing itself, tie or loss when playing random). For each chunk of 100 games, the bits are summed and then that can be plotted:
That is a plot from a training process of the final network and training configuration (point-of-view board representation, learning rate of 0.025). It starts with low numbers (as expected, because it doesn't know the game yet) but quickly rises to 90-100 games, which is good. Plots with learning rates ranging from 0.0125 (AForge's default learning rate) and 0.075 look similar. When the learning rate gets increased to 0.1, it goes wrong:
For comparison, below is a plot that shows a training process (with a learning rate of 0.025) that does not have any games where the AI played itself (so it only played against the random mover):
The first plot shows that the final performance values come closer to 100 when the AI plays itself too, compared to when it only plays against Random. However, the comparison of these two plots is not very fair because the first plot also has the self-play games in it, which may or may not work in favor of the perceived performance. To know that for sure, we need to make a plot of a training process with both games against Random and against itself, yet only show the games against Random on the plot, and see how that differs from the above plot. The result looks like this:
The average performance values (after the big jump) are higher on this plot than the previous. So, letting the AI play against itself appears to be beneficial.
Using only AI-vs-AI games, however, gives a bad result. The plot looks like this:
That may look good because we're hitting 100 every time after a certain number of games. However, when playing the AI, it's clear that it hasn't learned anything: the performance of 100 comes from 100 drawn games. The AI just found a draw against itself and reinforced that every training game.
When using 0 instead of 0.01 for an empty square, this was the best result I achieved (with a learning rate of 0.05):
The training is clearly less stable in the beginning, but then seemed to reach a point where it became as stable as when 0.01 was used for an empty square. However, this was one of the best performances, some others looked like this:
Whether the huge drop in the first plot was caused by using 0 instead of 0.01, I can't tell. But the plots do show that the average performance with 0 is much lower than when using 0.01.
Another network configuration that didn't work well, was using a tenth neuron to indicate who is to move, instead of the point-of-view representation. The plots for these training processes (at different learning rates) show that this didn't work well either:
The Code
Board and Game Representation
A game gets represented by the TicTacToeGame class, that keeps what the board looks like in an int array and whose turn it is:
public class TicTacToeGame
{
int[] board;
public bool IsXTurn
{
get;
private set;
}
public TicTacToeGame()
{
board = new int[9];
IsXTurn = true;
}
board will contain 0's for empty squares, 1's for X's and -1's for O's (this is not the neural network input representation). By convention, X starts the game. TicTacToeGame has a sub-enum Result and a related GetResult() method that returns the appropriate game result (unknown, X wins, O wins, tie) for the current board state.
public enum Result
{
Unknown,
XWins,
OWins,
Tie
}
public Result GetResult()
{
int diagonal1 = board[0] + board[4] + board[8];
int diagonal2 = board[2] + board[4] + board[6];
int row1 = board[0] + board[1] + board[2];
int row2 = board[3] + board[4] + board[5];
int row3 = board[6] + board[7] + board[8];
int col1 = board[0] + board[3] + board[6];
int col2 = board[1] + board[4] + board[7];
int col3 = board[2] + board[5] + board[8];
if (diagonal1 == 3 || diagonal2 == 3 || row1 == 3 || row2 == 3 ||
row3 == 3 || col1 == 3 || col2 == 3 || col3 == 3)
{
return Result.XWins;
}
else if (diagonal1 == -3 || diagonal2 == -3 || row1 == -3 ||
row2 == -3 || row3 == -3 || col1 == -3 || col2 == -3 || col3 == -3)
{
return Result.OWins;
}
if (board.Contains(0))
{
return Result.Unknown;
}
else
{
return Result.Tie;
}
}
GetResult checks if any diagonal, horizontal, or vertical line is filled by all O's or X's. If that's not the case, it's a tie if there's no empty position anymore. Otherwise, the result is unknown because the game isn't finished yet.
The GetBoardAsDouble method returns a double array that is the neural network input representation: 1 for the current player, -1 for the opponent, 0.01 for an empty square:
public double[] GetBoardAsDouble(bool xPointOfView)
{
double[] bd = new double[board.Length];
int view = xPointOfView ? 1 : -1;
for (int i = 0; i < board.Length; i++)
{
if (board[i] == -1)
{
bd[i] = -view;
}
else if (board[i] == 1)
{
bd[i] = view;
}
else
{
bd[i] = 0.01;
}
}
return bd;
}
A couple more helper methods: Move to play a move on the board (without any kind of move validation), ValidSquares to get an IEnumerable<int> of all valid (i.e. empty) squares to move on, and PrintBoard to print the board on the console.
public void Move(int square)
{
board[square] = IsXTurn ? 1 : -1;
IsXTurn = !IsXTurn;
}
public IEnumerable<int> ValidSquares()
{
for (int i = 0; i < board.Length; i++)
{
if (board[i] == 0)
{
yield return i;
}
}
}
public void PrintBoard()
{
Console.WriteLine(@"-------------
| {0} | {1} | {2} |
-------------
| {3} | {4} | {5} |
-------------
| {6} | {7} | {8} |
-------------", board.Select(x => x == 1 ? "X" : (x == 0 ? " " : "O")).ToArray<object>());
}
The Trained Model
The Model class wraps a trained ActivationNetwork (a class of AForge.NET) and provides a BestSquare method, returning the index of the next best square as evaluated by the network. This method loops over all valid squares and uses the network to evaluate how good the position is for the current player after hypothetically choosing the current square. The square resulting in the best score gets returned.
public class Model
{
ActivationNetwork net;
internal Model(ActivationNetwork network)
{
net = network;
}
public int BestSquare(TicTacToeGame game)
{
int bestSquare = 0;
double bestScore = double.NegativeInfinity;
foreach (int square in game.ValidSquares())
{
double[] boardAfter = game.GetBoardAsDouble(game.IsXTurn);
boardAfter[square] = 1;
double score = net.Compute(boardAfter)[0];
if (score > bestScore)
{
bestScore = score;
bestSquare = square;
}
}
return bestSquare;
}
}
The Trainer
The training of the neural network happens in the Trainer class. After training, this class exposes the training progress and the trained model as the Progress and Model properties:
public class Trainer
{
public List<bool> Progress { get; private set; }
public Model Model { get; private set; }
Random rand = new Random();
public Trainer()
{
Progress = new List<bool>();
Model = null;
}
rand is used for the training games of the partially trained network against a random mover. The booleans in Progress are true or false as per the way explained in "Comparing network architecture and training processes".
To train the network, we use AForge.NET's ActivationNetwork as network and BackPropagationLearning class to teach the network. AForge's teaching process is straightforward: you can just keep feeding it double arrays of inputs with the double arrays of desired outputs for as long as you want to. Each training game results in a collection of double arrays (for both input and output) - one for every board state during the game. Each of these input arrays has 9 elements and each output array has one element. The PlayTrainingGame method obtains those arrays by playing a game. This game is either played between two instances of the partially trained network, or between the partially trained network and a random mover. The method accepts three arguments: ActivationNetwork net (the network as it currently is), bool aiX (specifies if the AI plays X, but only really relevant if the opponent is the random mover), and bool fullAi (true if the game is played between two networks). The method plays out a whole game using a loop that continues until the game is over, and the moves played are either decided by the network or the Random instance. Every position gets added to List<double[]> inputs when it occurs, the correct outputs can only be decided after the game ends. If X wins, the collection of output arrays will look like { { 1 }, { -1 }, { 1 }, ... } because just like the board is in point-of-view representation, the output array has to be. 1 means "this position is good for 'me' if 'I' just moved in this position". So if X wins, all positions where X just moved should count as "good for 'me' (X)" and all positions where O just moved should count as "bad for 'me' (O)". For positions very early in the game, it isn't strictly true that a position is better or worse for one player. But for balanced positions, both players will be winning during the course of the training, so it will balance out eventually. If O wins, the collection of output arrays will look like { { -1 }, { 1 }, { -1 }, ... } and if it's a tie, it will be all zeros. And after the game, a new boolean gets added to Progress to indicate if the network performed well or not.
Tuple<double[][], double[][]> PlayTrainingGame(ActivationNetwork net, bool aiX, bool fullAi)
{
TicTacToeGame game = new TicTacToeGame();
List<double[]> inputs = new List<double[]>();
List<double[]> outputs = new List<double[]>);
Model current = new Model(net);
while (game.GetResult() == TicTacToeGame.Result.Unknown)
{
int playSquare;
if (aiX == game.IsXTurn || fullAi)
{
playSquare = current.BestSquare(game);
}
else
{
int[] validSquares = game.ValidSquares().ToArray();
playSquare = validSquares[rand.Next(validSquares.Length)];
}
game.Move(playSquare);
inputs.Add(game.GetBoardAsDouble(!game.IsXTurn));
}
double output;
TicTacToeGame.Result result = game.GetResult();
if (result == TicTacToeGame.Result.XWins)
{
output = 1;
}
else if (result == TicTacToeGame.Result.OWins)
{
output = -1;
}
else
{
output = 0;
}
for (int i = 0; i < inputs.Count; i++)
{
outputs.Add(new double[] { output * (i % 2 == 0 ? 1 : -1) });
}
Progress.Add(fullAi ? result == TicTacToeGame.Result.Tie :
(aiX ? result == TicTacToeGame.Result.XWins : result == TicTacToeGame.Result.OWins));
return new Tuple<double[][], double[][]>(inputs.ToArray(), outputs.ToArray());
}
This method is used by Train, which plays a given amount of training games and then assigns the trained model to the Model property. A third of the games is network-vs-network, the other games are network-vs-random (where it's balanced who gets to play X and O).
public void Train(int games)
{
ActivationNetwork net =
new ActivationNetwork(new BipolarSigmoidFunction(), 9, 18, 9, 3, 1);
BackPropagationLearning teacher = new BackPropagationLearning(net);
net.Randomize();
teacher.LearningRate = 0.025;
for (int i = 0; i < games; i++)
{
var trainingGame = PlayTrainingGame(net, i % 2 == 0, i % 3 == 0);
double[][] inputs = trainingGame.Item1;
double[][] outputs = trainingGame.Item2;
for (int j = 0; j < inputs.Length; j++)
{
teacher.Run(inputs[j], outputs[j]);
}
}
Model = new Model(net);
}
The BipolarSigmoidFunction is an activation function which looks like a sigmoid but goes from -1 to 1, which is suitable for our network.
With all this, you can easily create a program that trains a network and lets you play games with it through the console window:
var trainer = new Trainer();
Stopwatch sw = new Stopwatch();
sw.Start();
trainer.Train(500000);
sw.Stop();
Console.WriteLine("Training completed in {0} seconds.",
sw.Elapsed.TotalSeconds.ToString("0.0"));
var model = trainer.Model;
bool playerIsX = true;
while (true)
{
Console.WriteLine("Let's play a game.");
TicTacToeGame game = new TicTacToeGame();
while (game.GetResult() == TicTacToeGame.Result.Unknown)
{
game.PrintBoard();
if (game.IsXTurn == playerIsX)
{
Console.Write("Type a square (0-8): ");
int square = int.Parse(Console.ReadLine().Trim());
if (game.ValidSquares().Contains(square))
{
game.Move(square);
}
else
{
Console.WriteLine("Invalid square");
}
}
else
{
game.Move(model.BestSquare(game));
}
}
game.PrintBoard();
Console.WriteLine("Result: {0}", game.GetResult().ToString());
playerIsX = !playerIsX;
}

