Introduction
For the last 10+ years, I‘ve been developing an open source financial accounting application Apskaita5 for Lithuanian accountants. It was and still remains my hobby. It also was my first non-toy (relatively) large-scale application. No surprise I’ve made pretty much all possible mistakes while developing both the database model and the application architecture. The good thing is that I learned a lot from my mistakes. Previously, I was bound by backward compatibility requirement as the application is in active use by several hundreds, maybe thousands of Lithuanian companies. As a consequence, the current application version is far from perfection from the technological point of view, even though accountants are happy about the functionality and usability.
I intend to rewrite the same business functionality from scratch without taking backward compatibility into consideration. A great starting point is the development of a new database model that will support all the business functionality in the best technological way possible. In this series of articles, I am going to describe such structure of database model. Even though the database model will be specifically fitted for Lithuanian legal background for financial accounting, the financial accounting itself is very uniform across jurisdictions. I am quite confident that the changes required for a particular jurisdiction will be minimal.
This article series aims to prevent typical database design errors – poor planning, lack of consistency and lack of documentation. For me, it’s a method to contemplate possible design solutions, weigh their cons and pros. The articles will also serve as a good future database documentation.
I also expect community reactions and suggestions:
The development of the database model is under development :). Any discussions and proposals are more than welcome.
In this article as the first in the series, I’m going to discuss general database design concepts and define a very basic roadmap for the whole database like: defining the business domain, basic requirements to be met, primary key usage policy, naming conventions. We will also set up infrastructure for extensibility and basic lookup codes. We will not start domain entity modelling in this article, as there are plenty of decisions to take beforehand.
Database Domain – Accounting
The database model to be developed will be for a very specific purpose – financial accounting.
Financial accounting (or financial accountancy) is the field of accounting concerned with the summary, analysis and reporting of financial transactions related to a business. (Wiki) Financial accountancy is governed by both local and international accounting standards. It includes the standards, conventions and rules that accountants follow in recording and summarizing and in the preparation of financial statements.
From a programmer’s point of view, financial accounting is a set of methods to record and query company’s financial data. The part of recording of financial (transactions) data is also called bookkeeping. The part of querying the recorded financial (transactions) data is also called accounting (e.g., see The Difference Between Bookkeepers and Accountants ).
Financial accounting is by nature closely related to other two types of accounting: tax accounting and managerial accounting.
Tax accounting is defined as a structure of accounting methods focused on taxes rather than the appearance of public financial statements. From a programmer’s point of view, tax accounting means:
- Preparation of tax reports by querying data; and
- Tax specific data about financial transactions that is required to prepare a tax report.
Keeping in mind that (a) the users of the accounting application are going to be accountants and (b) the accountants are typically responsible for preparing tax reports, the application database shall also include tax accounting. Which means that some auxiliary financial transactions data will be required on top of the financial accounting standards in order to produce tax reports by querying the data. Otherwise, we wouldn’t meet the expectations of the users and we definitely don’t want that.
Obviously, taxes are jurisdiction specific by definition. On the other hand – taxes are subject to change (in Lithuania, it happens frequently and drastically). The application (database) model should be able to withstand inevitable tax changes thus the implementation of tax accounting should be as generic as it reasonably could be. As a side effect, this business requirement also makes it relatively simple to adjust the database model for other jurisdictions.
Managerial accounting is defined as the provision of financial and non-financial decision-making information to managers. The key part here is “non-financial information”. Though an accountant (accounting application) holds financial information, that is of great importance for managerial accounting, an accountant does not hold much background information nor does she/he care about it as an accounting professional (e.g., equipment idle times, capacities, risk assessments, sales details like the exact sale coordinates, etc.). Keeping in mind that the users of the accounting application are going to be accountants, the accountants will not be happy by an application requirement to provide extra data, not required from an accountant’s point of view. For that main reason, managerial accounting data and methods will not be included in the application (database) model, except for a simple cost centre association. There are also more reasons not to include managerial accounting functionality in a financial accounting application:
- Applications that target multiple different user categories are usually not comfortable for neither of the user categories (e.g., managers are uncomfortable with accounting data components, which they do not understand nor wish to, and the accountant is uncomfortable with managerial data components that “contaminates” financial data).
- There are multiple managerial accounting methods. Their choice is quite subjective. Implementing multiple methods will complicate the application to a great extent and are likely to compromise usability.
- Managerial accounting methods could be added by extensions (plugins).
Much of the data, required for managerial accounting, is stored in various specialized informational systems (POS, CRM, etc.). Therefore, some BI solution using multiple data sources will be required for effective managerial accounting anyway.
Base Requirements
For the development of the database model, I opted to use MySQL and SQLite (most extensively used, debugged, supported, open source and cross platform). However, this is not of much importance for this article series as the database model is going to be pretty generic (see simple technology requirement below).
The base requirements for the application database model shall be:
- Functionality: All common source documents and accounting operations shall be implemented within the application database model; so that the application could be effectively used for the most small and (probably) medium company’s without extra extensions.
- Simplicity: There are three aspects of simplicity requirement:
- Simple design: There could be no common database model for large companies and small to medium companies. Large companies deal with millions of operations per year which require specific solutions for processing speed due to the scale alone (big data). Such solutions are redundant for small to medium companies (thousands operations per year) and even slow the processing down. I’m not going to build another Navision and will not use big data related solutions. I assume the companies, which process more than 100.000 operations (financial transactions, source documents) per year, will not use the application.
- Simple functionality: The base functionality shall not include (relatively) rarely used, industry specific operations (financial transactions, source documents, methods, data fields, etc.). No single company would utilize all of the specific functionality, yet every accountant would face the irrelevant functionality in the application GUI. That would compromise pretty much all of the information organization principles set out in the ISO 9241-12 standard for the organization of information (clarity, discriminability, conciseness, consistency, detectability, legibility and comprehensibility). One could argue that the standard only applies for GUI. However, GUI solution that allows hiding some of the application functionality, especially at field or method level, is complex and involves mixing business logic with view. Not a good idea. Especially when you can implement plugin pattern. If an accountant needs specific functionality, he would install appropriate plugin, which might also override base business entities (e.g., invoice made) and provide GUI for them.
- Simple technology: The application shall be able to function both as a standalone and with some SQL server application. For small companies, requirement to install an SQL server application is too complicated. An accountant with minimal IT skills should be able to install and use the application on his desktop machine. Which brings us to the file based SQL solutions of which SQLite is the most popular. The drawback of this requirement is the inability to make use of advanced SQL server functionality (e.g., using CHAR(32) instead of GUID (UUID), limited set of numeric, date and other functions, etc.). Yet this requirement cannot be dropped.
- Extensibility: The application database shall support easy extensibility, i.e., an external application extension (plugin) shall be able to add its own database tables and use the existing (base) data tables without breaking base functionality.
- Database per company (tenant): It’s not uncommon for a single accountant (or accounting firm) to provide accounting services for multiple companies. The application could also be provided using SaaS model. The application can support those use cases using two database models: database per tenant or single database (there are also mixed models, e.g., Microsoft shard model, yet they are too complicated in this case). For single database model, you would add tenant (company) identifier in each table. For database per tenant model, you would have a separate database (schema for the RDBMS that support multiple schema per database) for each tenant (company). You can read detailed discussions regarding both of the models here: Single vs multi-tenant SAAS ; One database per customer, or one database for the whole SaaS-app? ; Multi-tenancy: What benefit does one-db-per-tenant provide? ; Is that a good idea to use one database for 50.000+ shops? ; One Big Database vs. Several Smaller Ones. The reasons to choose database per tenant model for the application are:
- Company’s accounting data is isolated for the purposes of the financial accounting. Company’s accounting data (a row in some table) can never reference another company’s accounting data (a row in some table). It’s a requirement of financial accounting domain. There are two real-world exceptions: consolidated accounting for large groups of companies and scientific research (statistics, AI, etc.). The first use case is not compatible with the simplicity requirement. The second involves only statistical data that is typically extracted at ad hoc basis. Besides, if one is going to do a research that involves accounting data of multiple companies, he will likely have the databases on a single server, which typically support cross database queries (e.g. MySQL).
- Company’s accounting data is strictly confidential. Chances to accidentally (or on malign purpose) fetch data of an unintended company should be reduced to a minimum.
- Single company’s accounting data (potentially) is of high volume. Some tables for a single company might contain million rows or more. Adding multiple companies to a single database would require handling multimillion rows, which brings us to the realm of big data. That would contradict the simplicity requirement as described above. Furthermore, in this case, database per tenant model allows both horizontal and vertical scaling while the single database model would only allow vertical scaling.
- There is a legal (and practical as well) requirement to be able to move company’s accounting data between accounting systems to maximum extent possible (including transferring of the data to the target system and deleting the data from the source system). E.g., a company decides to change its accounting firm but the new firm will continue to use the same application.
- The database schemas for different companies could be different if they use different extensions. You wouldn’t want to use insurance extension for a company that has nothing to do with insurance. Therefore, extension per application instance is not an acceptable solution.
- Optimistic concurrency control (see wiki): The application will run in low concurrency environment determined by typical use cases. Even large companies have few employees that work with financial accounting applications. There will likely be no more than 10 direct application users per company. The application can also have programmatic/virtual users: CRM, billing system or e-shop that interact with the application via REST service. Even there is only one (programmatic/virtual) user per external system; the concurrency in this case is higher due to the asynchronous functioning of REST service. However, higher concurrency due to integration through REST service is mitigated by the typical nature of such integrations. Such integration extremely rarely does something else than providing the data of invoices made to the accounting application, i.e., we are talking mostly about inserts that do not create any concurrency issues.
- External authentication and authorization system: One of the reasons for using database per company model was the possibility to easily move company’s data between application instances, e.g., from one accounting service provider service (server) to other. Obviously, in such use cases, user access policy is defined not by the company but by the service provider. Hence, security (authentication and authorization) policy and user data shall not be contained within a company’s accounting database. Such approach does not create tight coupling between the business data and security solution and does not put any restrains on the security solutions to use for access control.
- Simple audit trail: Various audit trail methods provide different record change audit details. A nice summary can be found here: Database design for audit logging . Audit trail has three purposes: data debugging, rollback functionality, negligent accounting and fraud investigation. Audit trail should not be confused with data versioning. The latter is a specific solution based on business requirements. We will implement versioning of some tables. However, it is the subject for the next article in this series. Extensive discussions about different audit trail solutions could be found here: Database Design for Revisions , Best design for a changelog / auditing database table , Ideas on database design for capturing audit trails, History tables pros, cons and gotchas - using triggers, sproc or at application level, Maintaining a Log of Database Changes. In our case, there are four theoretically possible solutions:
- Column change log (rejected) – Changes are logged per column in a single table with columns (plus minus):
table_name, field, user, new_value, deleted (Boolean), timestamp. It’s a most detailed audit trail solution available and for the very same reason, absolutely redundant one. If one requires to record all the SQL transaction details, she/he would simply turn on SQL server logging, e.g., binary log for MySQL. Therefore, we definitely won’t implement this solution. - History tables (rejected) – Mirror tables are created for all of the business tables and all of the rows to be modified are moved to an appropriate history mirror table. The only difference between this solution and SQL server native logging is a more flexible ability to query the historic data. The price for this solution is double table amount and high complexity due to foreign key relations. The examples of this solution include only simple case with some table (as a rule – common employee data) without any foreign key relationships. In order to manage real world cases with extensive foreign key relationships (e.g., invoice and supplier) one would either need to use highly denormalized history tables or to implement highly complex logic for foreign index transforms, so that historic row foreign index points not to the original referenced row but to the historic version of that row. For this reason, the complexity of this solution in real world scenarios is very high. Yet the benefits of this solution are not very high to compare to native SQL server logging. Therefore, if there is no hard business (or legal) requirement to implement this particular solution – don’t do that.
- Document change log (under consideration as an optional functionality) – application (not database) before inserting, updating or deleting a document (again – application defined document, parent business object, not a database entity) adds a log entry: document type (probably – full name of the business object type, e.g.,
Apskaita5.BusinessObjects.InvoiceMade), document id, action type, serialized document (JSON or XML), timestamp and user. The rationale behind this solution is that database transactions typically happens in graphs that are defined by the application (outside of the database), therefore, it makes sense to log namely the graphs changes. Additional benefit of this solution is that historic versions are written in the application’s native format, which makes it trivial to view the historic documents in the application by simple deserialization and consequentially undelete a deleted document by inserting new one with the identic business fields. The drawback of this solution is that it makes it impossible to query historical document fields. On the other hand – why would one need that? Within the database, the implementation of this model only requires creating one table for log entries as described above (maybe two tables in order to move relatively large serialized string to other table for performance reasons). Within the application, the implementation of this model requires common functionality of all the business objects (types) to serialize and deserialize themselves and to add a log entry on save, which could be done by using some superclass for all the business objects. Actually, it doesn’t require much effort to implement, as the serialization functionality is required for other reasons anyway. For now, I will skip this functionality but I will leave it for further consideration. - Simple audit trail (accepted) – Just add standard fields to every table that stores parent entities:
inserted_at, inserted_by, updated_at, updated_by. We don’t need to add those fields to child entities because they are always an integral part of the parent entity (of course, if one needs more details, child entities could be tracked too the same way). It’s a simple, widely used solution, that neither requires much work, nor has any considerable impact on performance. Besides, (a) we need updated_at field anyway for optimistic concurrency control and (b) in multiuser environments, accountants love to see who inserted and updated some document, and when. Therefore, we will implement this model in the application database.
Business Logic
There is an eternal question of religious nature: “How much business logic should the database implement?” (For discussion see: Business logic: Database vs code, How much business logic should the database implement?) As any religious question, it does not have a definite answer. Sure, it’s tempting to have a database to reject invalid data as a measure of last resort. “Last resort” – because it’s next to impossible to implement intelligible and regionalizable exception messages. Yet it inevitably leads to business logic duplication at database and application levels.
My approach to the problem is simple – application is exclusively responsible for business rules, while database is exclusively responsible for data consistency (referential integrity). If an application (business entities) are able to fetch their data consistently (i.e. without null reference exceptions and data loss), they are able to fix any business errors as well. It could (and should) be implemented as an audit method or a cron job and shall notify an accountant about any (potentially) invalid data. On the other hand, the database is exclusively responsible for data consistency (referential integrity). Therefore, it should safeguard that entity graph is never broken and an entire graph can always be loaded into the application business layer, i.e. no orphaned records, no incomplete entity graphs. It could be done using foreign keys and appropriate ON DELETE constraints.
We have already ruled out triggers and stored procedures due to the simplicity requirement. Therefore, we will not have to deal with these business logic “vessels”. Yet, we also need to be careful with field types as well. Field types shall not be restrictive as long as the business logic behind restrictions are sound as continents. E.g., one would normally expect a tax rate without decimal part, yet the tax legislation authors have quite an extensive imagination. Therefore, always prefer broader types; only use UNSIGNED constraints if it has been so for centuries.
Take for example currencies. Most of the countries have two decimal digits, yet some have zero decimal places (e.g. Japan yen) and some three decimal digits (e.g. Algeria, Bahrain, Iraq, Jordan, Kuwait, Libya and Tunisia dinar). Unless you target your application to Arabian countries, it’s a normal design decision to use two decimal digits for amounts in base currency. As far as I’m concerned, all applications do. However, the application fields that handle amounts in different currencies should use three decimal digits. The moral of a fable – always doubt about field type constraints. It’s better to spend some time on google, than have an incident when some company gets an invoice from a Bahrain company.
The design decision to use as little business logic as possible by no means suggest that you should ignore likely data errors. On the contrary, such cases should be documented along with the database schema to allow a business layer developer to implement an audit routine (method, cron job, etc.) that would notify an accountant about potential discrepancies.
Calculated Values
Sometimes you might be tempted to get rid of the values (fields) that can be calculated using other fields, e.g., total amount that can be calculated by multiplying unit value and amount. Don’t do it. Database rounding algorithms are not guaranteed to be the same as in the application. Due to the rounding uncertainty, you can get different values when calculating on the database and on the application side. Which is bad, as accountants are very pedantic persons and care for every penny. If an accountant finds out that an invoice total amount in the invoice itself is different from the same amount in the invoice registry, he will be very unhappy. Actually, it’s a rule of thumb – never use (rely on) calculated fractional values (decimal or float) if the calculations involve multiplication or division and are potentially performed outside of a single application boundaries.
Primary Keys
A primary key is a special database table column (or combination of columns) designated to uniquely identify all table records. A primary key's main features are: (a) It must contain a unique value for each row of data; (b) It cannot contain null values. (Technopedia.com definition) The primary functional purpose of the primary key is to relate rows from different tables by foreign index (and do it fast). Without primary keys, database ceases to be relational (at least to some extent). To keep our database tables related (e.g., to relate an invoice and its lines) we need to add a primary key to every table in the database.
There are two types of primary indexes – natural and surrogate. A natural key is a column or set of columns that already exists in the table (e.g., they are attributes of the entity within the data model) and uniquely identify a row in the table. Since these columns are attributes of the entity, they obviously have business meaning. E.g., social security number might be a natural primary key for an employee. A surrogate key is a system generated (could be GUID, sequence, etc.) value with no business meaning that is used to uniquely identify a record in a table. E.g.,
user_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
If you polled any number of SQL professionals and asked the question, “Which is better when defining a primary key, having surrogate or natural key column(s)?”, I’d bet the answer would be very close to a 50/50 split. Here is a list of more or less constructive discussions for deeper understanding of the subject matter:
For the good part debates natural vs. surrogate key are of religious nature. Despite that, we still need to define a general policy for choosing primary keys in our database model and the discussions allow identifying some guidelines for that. The key factor is the absolute requirement for the primary key value to be unique. In 10+ years of development and support of a financial accounting application, one thing I learned for sure – there is little or nothing unique in rows (at best, it’s complicated and ambiguous), for example:
- It is perfectly ok to have two absolutely identical rows for invoice items (lines): same invoice, same goods/services, same amount, same price, etc. Invoices are made by managers that we have no control on. An accountant (application) have no option but to register the invoice as it was created by a manager.
- There are no ways to identify a person in non-ambiguous way not to mention the complexity of business rules for possible duplicates: Not all of the countries have unique identifiers for their residents (companies and natural persons). E.g., in UK only some types of the companies have registration number assigned. Not all the persons are VAT payers. Same name does not mean it is the same person and vice versa even for companies in the same countries. The best thing an accountant (application) can do is an educated guess.
If a natural key for an entity does not exist in nature, we have no choice but to introduce surrogate key. Which will be true for almost all of the tables in our database model. Still a few cases exist where there are natural keys:
- Lookup tables: Natural keys are various codes used in accounting: country, currency, tax. They are great candidates for primary key because they are unique, small (2-5 characters) and only used to prevent entry errors / typos (see below for the full lookup tables’ explanation). Accountants (main users of the applications) are familiar with those codes therefore for the most reports, no details except for the codes themselves will be required. The same is true for business objects, e.g., it’s enough for an invoice to hold the currency code, human readable currency name can be provided by lookup control in the GUI. Using such codes as the primary keys won’t compromise performance and will avoid unnecessary joins. Therefore, I will use such codes as primary keys.
- Financial account ID: For the last thousand years, each financial account in the company’s chart of accounts requires a numeric unique code. That makes the account id a great candidate for primary key because they are unique, small and of native type (
BIGINT). Accountants (main users of the applications) are very familiar with the account ids therefore for most reports, no details except for the ids themselves will be required. The same is true for business objects, e.g., it’s enough for an invoice to hold the accounts payable id, account name can be provided by lookup control in the GUI. Using such ids as the primary keys won’t compromise performance and will avoid unnecessary joins. Actually, in this case, it prevents many joins as business objects can reference multiple accounts, e.g., each invoice line reference some costs account and some VAT account. Therefore, I will use account ids as primary keys. - Application’s extension ID: Application extensions are created by the third parties (at least some of them). Yet the application should be able to resolve its extensions. Therefore, all the extensions and operation types implemented by the extensions shall have unique identifiers. The standard unique identifier that could be safely generated by third parties is GUID. In our case, those extensions GUIDs are natural keys. Each operations (source documents and others) table shall have extended type identifier. When the application user requests to retrieve some operation, the application shall be able to resolve the business entity type that the operation represents, i.e., both operation base type and extended type identifiers will be required for every business entity retrieval. Which brings us to the same conclusion as in previous cases – to use the extended operation type identifiers as primary keys. Though they are bigger than lookup or account ID values (32 characters instead of 2-5 characters), they will rarely be used for joins and frequently required by themselves. This specific use case effectively mitigates negative performance impact by large key.
If we choose to use surrogate keys due to absence of natural keys, we still need to choose the type of the key, which could be either integer or GUID (UUID). Here, we face another religious dispute:
What I learned from the discussions read – GUID as primary key does degrade performance (both inserts and joins). It is debatable how much and whether it could be mitigated to some extent by a specific server configuration, but it does. Therefore, GUID as a primary key should only be used if it has at least some benefits for the application use cases. The application we design is not distributed and does not reasonably require data replication (low concurrency, database per company plus small to medium companies). Those are the only good reasons why would one choose to use GUI as primary key. Therefore, I’m not going to use GUID as primary key in any table (except for the extended operation types table as discussed previously).
On the other hand, there is one scenario when it is useful to have an additional GUI column: when there are (could be) external systems that import the application data. In such a case, the external system can only resolve entities already imported (documents, transactions, etc.) by the id provided by the application. If an entity id is an auto incremented integer, there could be some cases when the application requires changing them, which in turn breaks the external systems. Fortunately, the cases are extremely rare:
- The first case would be merging of the companies databases. E.g., if we were to build a CRM application, it would be a likely scenario as a merger means that the proceeding company will manage all of the clients of the companies merged. However, it is not applicable for financial accounting, because merger by no means makes the proceeding company an owner of the previous transactions. The proceeding company will only inherit the balance of the companies merged. Therefore, database merging will never occur due to the company mergers.
- The second case would be a major upgrade of the applications itself. E.g., it will happen to my application Apskaita5, because the current version does not have one common table for source document data (many tables depending on the document type) and the application we design there will be. Unlikely though it may seem, it might happen again. On the other hand, in 10+ years, I haven’t encountered a use case that would require integration where the accounting application data is transferred to some external system (except for the services/goods catalogues that are not affected by the problem due to the integration codes). For now, I will not add GUID columns to tables, but I will leave it for further consideration.
CHAR vs. VARCHAR
Type of data to use for text fields actually depends on a specific RDBMS used. For SQLite there is no distinction at all as CHAR and VARCHAR both have TEXT affinity. For MySQL there are subtle differences that have some effect on performance. However, the performance impact is based on trade-offs and appears to be not very significant (for discussion see Performance implications of MySQL VARCHAR sizes, MySQL Performance - CHAR(64) vs VARCHAR(64), What are the use cases for selecting CHAR over VARCHAR in SQL?, Optimizing Schema and Data Types). Therefore, it is reasonable to use the type that best describes the data itself:
- Use
CHAR when dealing with strings that are of fixed length by nature, e.g. language, country codes, GUIDs etc. - Use
VARCHAR when dealing with strings that can be of variable/arbitrary length, e.g., names, descriptions, comments etc.
When dealing with CHAR type strings and MySQL server it is also important to set appropriate character set. E.g., language, country codes and GUIDs only use ASCII characters; therefore using UTF8 character set would be largely redundant and would decrease JOIN performance. Again, the collation is also important. While you can use ci (case insensitive) collation for country/currency/language codes, you should use bin (binary) collation for GUIDs.
It's also worth mentioning, that MySQL collation is also applicable for ENUM fields. Don't use binary collation for them, because you will run into casing problems, use ci (case insensitive) instead.
When dealing with VARCHAR type strings their max length should be set in a balanced way. On one hand, the max length of some text field should be sufficient for an accountant. On the other hand, too long fields do increase memory usage even if the actual strings are much shorter than max allowed. I have checked average lengths of most common textual fields in a real accounting database and found out the following values:
- Average document number length is 6,22 characters, max document number length is 27 characters;
- Average document description length is 37,54 characters, max document description length is 231 characters;
- Average person name length is 21,19 characters, max person name length is 82 characters;
- Average unstructured address length is 37,35 characters, max unstructured address length is 196 characters.
It is also notable that an average text page contains around 4.000 characters (including blank spaces).
Actually, I received a few requests for field lengths in 10+ years of supporting an accounting application. And I used 255 max length for everything but one specific field.
I believe, the actual statistics would depend on the region/culture. However, the following max lengths should suffice without significant performance impact:
- Document number – 50 characters;
- Document description – 500 characters;
- Document comments – 4.000 characters;
- Person name – 255 characters;
- Unstructured address – 500 characters;
- Various names that are meant to be displayed in lookups – 100 characters.
Percentages
Percentage in math is represented as a fraction. The same is true for common numeric formatting (e.g. .NET decimal to string format “P”). Storing percentage as a fraction also simplifies calculations – you do not need divide a value by 100. Therefore, the preferred database type for a percentage with a given precision is DECIMAL(precision +3, precision +2), e.g., if the required precision is zero decimal digits (not recommended), the database type definition is DECIMAL(3, 2); if the required precision is two decimal digits (not recommended), the database type definition is DECIMAL(5, 4).
Naming Conventions
Database models require objects to be named. There are various standards for naming conventions and eternal debates, which one is better. (See: Naming Conventions in Database Modelling , Database, Table and Column Naming Conventions?, The 9 Most Common Database Design Errors). However in the end, it’s all about clarity (any person with adequate business domain knowledge should understand table and field names) and consistency (same concepts should be named the same way). The rest is only a matter of personal preference.
Naming Conventions for Table Names
- Max 28 chars – because MySQL does not support more (also see table and index name length limitations)
- A table should be named after the entity it represents
- Where applicable, use financial or tax accounting terms – they are short and their meaning is well defined in the domain of the application, e.g.,
accounts, bank_operations, etc. - Where financial and tax terms are not applicable, use terms common in general applications, e.g.,
company_profile, person_versions, etc. - Do not use spaces in table names
- Do not use abbreviations
- Use plural form of the business entity stored in the table, e.g.,
accounts, documents, etc. - Use all lowercase table names, where words are separated by an undescore "_" – It’s quite convenient for an eye, does not require too many extra symbols and avoids case sensitivity bugs, e.g.,
bank_accounts - Do not use any prefixes or postfixes – the application will not have any distinct modules with similar tables where prefixes could be beneficial (for now – trust me on that :) )
Naming Conventions for Field Names
- Max length = 64 chars – [table name length] - 5 chars (see index name length limitations)
- Where applicable, use financial or tax accounting terms – they are short and their meaning is well defined in the domain of the application, e.g.,
social_security_no, etc. - Where financial and tax terms are not applicable, use terms common in general applications, e.g.,
person_name, description, etc. - Do not use spaces in field names.
- Do not use abbreviations.
- Use all lowercase field names, where words are separated by an undescore "_" – It’s quite convenient for an eye, does not require too many extra symbols and avoids case sensitivity bugs, e.g.,
official_code. - Do not use table name as prefix unless the natural field name is a reserved word, e.g.,
document_date instead of date. - Use name
id for standard surrogate primary key (id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY). - For foreign keys, use referenced table name singular form with a postfix id, e.g.,
person_id for table persons; where there are multiple fields referencing the same table, (also for clarity sake) foreign key field name is (could be) prefixed by some business name, e.g., bank_fee_account_id. In some case, natural names do not follow this convention, but include the referenced table name (or the meaning is obvious in the accounting domain), e.g., accounts_payable_id. - For boolean fields, use prefix
is, e.g., is_client. - For fields that store default value for quick fill functionality, use prefix
default, e.g., default_accounts_payable_id. - For fields that store entity id assigned by some external system (REST client, etc.), use name
external_id. - For fields that are used to mark an entity data as archived (obsolete, no longer in active use), use field name
is_archived. - For application defined enumerations, use postfix
type, e.g., document_type, Also use type SMALLINT instead of ENUM, unless the enumeration subject is stable as continents (e.g., debit and credit in accounting) or the enumeration defines data storage metadata, i.e., only used as technical field to support storage method (e.g., for hierarchical data storage). The use of technical lookup tables for such enumerations is under consideration: on the one hand, it contributes to the data integrity, on the other hand, it means extra table per type (application defined enumeration), which is of no use. - For audit trail, use the following field names:
inserted_at, inserted_by, updated_at, updated_by.
Naming Conventions for Index Names
- Max 64 chars – because MySQL does not support more
- Name structure for foreign key indexes:
[table_name]_[field_name]_fk - Name structure for other indexes:
[table_name]_[field_name]_idx - Do not use spaces in index names.
Extensibility Infrastructure
One of the key requirements for the application database is the ability to extend it by any third party developers. When combined with the database per tenant (company) requirement, it means that the company database should hold (meta-) data about the extensions used (installed). Technically, some outside database (solution) could also do it. However, it would mean that after moving company database to another application instance, the installed extension data would not be moved to the target application instance. Therefore, we have to keep extension data exactly within the company database.
In order to understand extensibility data requirements, we need to understand extensibility extent, methods and use cases. The main functional extension principle is the good old SOLID as it is applicable to the database world:
- Each base fact shall be added to a base table. The single responsibility principle holds that every class should have a single responsibility, which it should entirely encapsulate. In the database world, it pretty much means data normalization – every relation must contain a superkey and values functionally and directly dependent on that superkey, i.e., if an extension holds some base fact fields in its own tables, it breaks normalization of the base fact table. Closely related to this requirement is Liskov substitution principle. Liskov substitution principle holds that if S is a subtype of T, then objects of type T may be replaced with objects of type S (i.e. an object of type T may be substituted with any object of a subtype S) without altering any of the desirable properties of the program (correctness, task performed, etc.). I.e., if an extension subtypes some base fact but does not provide full base fact description, it breaks the application ability to have a common view of the base facts. In simple worlds, a base bank operations table contains all the values that make up a base bank operation and allows viewing all of them in a single view even if particular operations are created by different source documents. If an extension deals with some specific types of bank operations but fails to persist their base properties in the base bank operations table, it (a) violates 3rd normal form; (b) violates Liskov substitution principle and creates data anomalies – bank operations that are missing from the base view (trivially not included in the bank account balance). Due to the simple technology requirement, we are not going to use table inheritance, therefore, no specific problems when an extension inherits tables. (see Building SOLID Databases: Single Responsibility and Normalization, Building SOLID Databases: Liskov Substitution Weirdness )
- No base tables modifications allowed. Open–closed principle holds that entities (in this case – database tables) should be open for extension, but closed for modification. In a strict view, it means that an extension cannot modify any base table (add or remove any columns). In this case, we are dealing with third party extensions that are developed by multiple independent developers at different times, which definitely means overlapping deployment cycles. Therefore – strict view (see Building SOLID Databases: Open/Closed Principle ). Practical example of what will happen otherwise: extension A adds some column to a base table, extension B also adds some column to the same base table; both extensions naturally need values within the columns they owe, but a row inserted by the A extension will not have values for the B extension column and vice versa; ergo – extensions break each other.
- User defined functions are not allowed. Simply due to the simple technology requirement, e.g., SQLite does not support user-defined functions. Therefore, no problems with the interface segregation principle and the dependency inversion principle. (see Building SOLID Databases: Interface Segregation, or Keep Stored Procedures Simple , Building SOLID Databases: Dependency Inversion and Robust DB Interfaces )
Having in mind the functional extension principles described, there are the following distinct methods of the application extension:
- Extension by subclassing data. An extension creates a custom business entity type using a base type but with more extension specific data. E.g., a custom bank operation data will still contain all the base bank operation data but will also contain some additional custom data (fields). For that purpose, the extension will require a custom table that will contain custom bank operation fields and will reference a base bank operation table row (that it extends).
- Extension by subclassing methods. An extension creates a custom business entity type using only the base type data (fields) but applying different methods to the fields. E.g., a custom goods operation that changes base goods (balance) state in a particular way that is not implemented by the base application. For that purpose, the (methodologically) extendable base operation tables will contain a column for the extended operation type (GUID) that will be used by the custom operation type to indicate the requirement of the custom methods to edit the operation.
- Extension by composition. An extension contains a custom business entity type that contains few base types arranged and managed systematically. E.g., a (fictional) cash operation that (internally) contains a bank operation and a cash fund operation to designate some cash withdrawal from a bank account to a cash fund. For that purpose, the extension either uses base document infrastructure, i.e., subclass a base source document (extension by subclassing) that is composable by design (see next articles for description), or add (implement) custom container tables (probably with associative tables) that will manage references of the related base table rows. As we will see in the future articles, the first method is going to be a common way of extension while the second will have many limitations related to particular tables (entities).
- Independent extension. An extension contains a custom business entity type that contains no data handled by the base functionality tables. E.g., custom lookup value, which is only used by some other extension entity. For that purpose, the extension will require a custom table that will contain custom entity data.
The extension methods that do not involve extension by subclassing methods, pose no danger to the integrity of the base data: one can drop extension tables (or not use them) and will only lose the extra data; the base data will remain intact. Extension by subclassing methods (including its usage in extension by composition), however, pose danger to the integrity of the base data: if one loses access to the extension, he will no longer has access to the specific methods required to edit the extended operation effectively making it read-only. To mitigate (at least to some extent) the problem, a custom operation shall have an ability to fall back to some base operation type. Which (at this development stage) means that we should also:
- have data about fallback base type for each custom operation type; and
- keep the data of the uninstalled extensions to know the (possible) source of (possible) data artefacts
To sum it up, first we need the following basic information about the extensions installed:
- A GUID of the extension, that is assigned (generated) by the extension developer
- A name (short description) of the extension – for the (obvious) data debugging purposes
- A version of the extension – so as not to downgrade the extension without intention
- A timestamp for the install of the extension
- A user who installed the extension
- A timestamp for the last upgrade of the extension
- A user who upgraded the extension last
- A timestamp for the uninstall of the extension (nullable)
- A user who uninstalled the extension (nullable)
One of the possible use cases is that an extension could be uninstalled and later reinstalled. The information of the previous install will still be of value for data debugging and for audit logging. Therefore, we cannot reuse (overwrite) the existing entry about the extension and keep the GUID unique across the table. To allow for such a use case, a surrogate key shall be added.
The information about the extension install, upgrade and uninstall timestamps and corresponding users will only be used for the data debugging purposes and also for consistent implementation of the simple audit logging requirement (except for the uninstall data that is specific for the extension functionality).
Next, we need the following basic information about the each extended operation type:
- A GUID of the extended type, that is assigned (generated) by the extension developer
- An ID of the extension that the extended operation type belongs to (foreign key)
- A name (short description) of the extended operation type – for the (obvious) data debugging purposes
- A fallback base type for the operation
Though all the tables for each extendable operation will be the same, it would be very unwise to give in to temptation, use one table with an additional column “operation type”. The GUIDs of extended operations types will be used as a foreign key in the operation tables. If one used single table with row types approach, a bug could cause assignment of inadequate operation type. Which in turn will render data inconsistent and could be very troublesome to fix manually.
The resulting database schema using previously defined naming conventions (name – reserved word; GUID – not currently reserved for MySQL, but is a good candidate to become one):
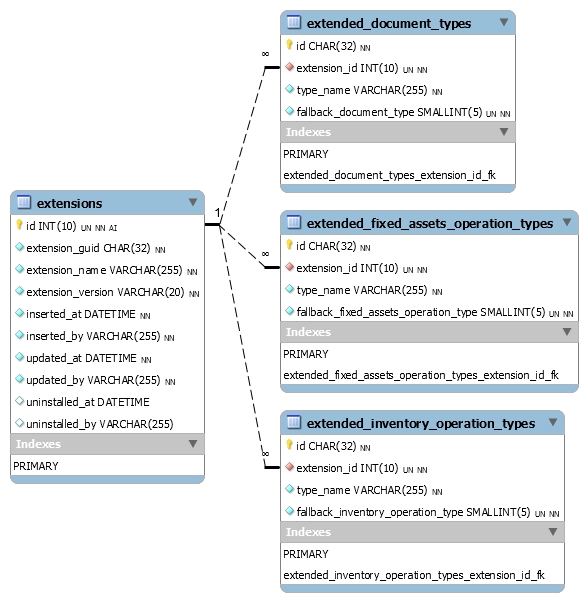
With the schema in place:
Though we have to delete extended operation types for the extension uninstalled (otherwise they could be assigned to an extendable operation row), one could consider leaving some historic trace of the original operation types and use them for recovery (“undo fallback”) if the extension is reinstalled. E.g., add two GUID fields to an extendable operations table instead of one. I believe this is a controversial idea. There is a considerable risk that the operations in question could be edited as operations of base type they become after fallback. That is not to mention the fact that the same operations could have been extended by data also (impossible to undo because extension tables were dropped). After such edits happened, the type recovery (“undo fallback”) on reinstall will break the extension. Therefore, while trying to do good, the outcomes could be much worse. On the other hand, before trying to undo fallback, we could check operations’ updated_at field against the uninstall date of the extension and leave it for the extension to take the final decision whether the fallback undo is possible. For now, I’ll leave this possibility for further consideration.
- Installation of an extension will done by:
- Adding required tables to the aggregate database schema (if applicable)
- Inserting the extension base data
- Inserting extended operation data (if applicable)
- Database integrity check will done by:
- Fetching a list of all the extensions installed in the database
- Creating an aggregate database schema required (base tables plus tables, required for the extensions installed)
- Checking the actual database structure against required aggregate schema
- Checking for outdated extensions
- Upgrade of an extension will be done by:
- Updating extension base data
- Updating extended operation data with the following restrictions:
- id of a type cannot be changed, only name and fallback type
- operations cannot be removed, i.e., extensions cannot abandon their own operation types
- Updating extension database tables
- Uninstallation of an extension will be done by:
- Updating all the extendable operations created by the extension by:
- modifying their base type from ‘custom’ to the fallback type specified by the extension
- setting extended type id to
null
- Deleting all the extended operation types for the extension (because they should not be used in extendable operations tables anymore)
- Marking the base extension data as deletes, i.e., setting
uninstalled_at and uninstalled_by values - Dropping the tables created by the extension
Lookup Lists
The final thing to consider before moving on to modelling domain (accounting) entities is lookup. There are international standards for country and currency codes:
- ISO 3166 standard that defines country codes (e.g., GB for United Kingdom); and
- ISO 4217 standard that defines currency codes (e.g., EUR for euro).
For sure, the codes are required in the accounting data. It might be tempting not to have lookup tables for those codes and allow their direct entry. However, we must resist the temptation. Manual entry is prone to errors – either typos or (more likely) lookup control selection. In our case, such entry errors can have very unsavoury consequences. Once an accountant made a “mouse error” and selected suppliers country code AG (Antigua and Barbuda) instead of AR (Argentina). The error went unnoticed to a tax report. Tax authority’s tax evasion monitoring software threw a red-flag because Antigua and Barbuda is an offshore territory. It led to the inspection of the company by the tax authority, which was unsavoury. The lesson learned – do not ever offer an accountant a possibility to select a country that the company has no relations to. The same is true for currency codes.
The solution is trivial – just add lookup tables for those codes, which will provide both data integrity constraint and handy (short) lookup list for an accountant to choose from. A “mouse error” is still possible, but the consequences of mischoosing a country, that the company deals with anyway, is far less severe than mischoosing one, that the company has nothing to do with.
We will add separate tables for each code type, because they will be used as foreign keys and we do not want currency code appearing instead of a country code.
As discussed above (section Primary Keys), we will use the country and currency codes as primary keys. We will not specify country or currency names as they are subject to the application regionalization. We will add (standard) field is_archived to further reduce error risk by hiding archived codes from the lookup list. The codes are good candidates to be a top level (parent) entity. Therefore, we will also add standard audit trail fields. If we decide to make them children of the company’s profile in the future, it won’t be much trouble to remove them.
The resulting database schema using previously defined naming conventions:

Conclusions
In this article, I defined a basic policy for the future database design. Some points are left for future consideration. I will update the article once I make up my mind (hopefully with your help). Having taken the cornerstone decisions, now we are ready to proceed to modelling of the accounting domain entities.
The next article will be dedicated to the accounting infrastructure design: general ledger, chart of accounts, documents and financial statements.
History
- 2nd July, 2019: Initial version
- 21st July, 2019: Changed naming conventions to more developer friendly
- 28th July, 2019: Added naming convention for foreign key indexes to distinguish them from other indexes
- 9th August, 2019: Switched to
VARCHAR where approprate, added new paragraph regarding the choise between CHAR and VARCHAR - 16th September, 2019: Added charpters on business logic, calculated values and percentage storage

