This article is one man's opinion of whether or not Microservices are worth it. It looks at problems, myths, the current state of affairs, and offers a little guidance. The article states not to get caught in the hoopla of microservices (even Docker, Kubernetes, AWS, Google, and Microsoft). There's no reason you can't host a microservice in a Linux OS on DigitalOcean12 for $5 a month running C# .NET Core code.
Contents
So what really is a "microservice?" And what's all the hoopla about anyways? Wikipedia offers actually a rather good definition:
Microservices are a software development technique�a variant of the service-oriented architecture (SOA) architectural style that structures an application as a collection of loosely coupled services. In a microservices architecture, services are fine-grained and the protocols are lightweight. The benefit of decomposing an application into different smaller services is that it improves modularity. This makes the application easier to understand, develop, test, and become more resilient to architecture erosion. It parallelizes development by enabling small autonomous teams to develop, deploy and scale their respective services independently. It also allows the architecture of an individual service to emerge through continuous refactoring. Microservice-based architectures enable continuous delivery and deployment.1
If you drink the Kool-Aid, the key phrases here are:
- loosely coupled services
- fine-grained
- lightweight
- modular
- resilient
- parallelizes development
- scaleable
The irony here is that we've heard pretty much the same mantra starting with object oriented programming / architecture / design, so why are microservices now suddenly (one of) the in-vogue solution to problems that have not been already solved? Three answers:
- There's money to be made from companies like Microsoft, Google and Amazon, offering microservice "serverless" computing.
- While it's another tool, and definitely useful, the lure of "this will solve all your problems" is an ever present seductive siren-song, and managers and programmers alike love the seductive part of new technologies.
- And lastly, and sadly, programmers in general do a pretty poor job of, guess what, programming. But instead of learning how to be a better programmer, a bad programmer stays a bad programmer by reaching for sugary drink with artificial color that promises feeling better.
The reality is, you almost always don't need microservices to achieve the above "holy grail", you just need a decent architecture. So let's redefine microservices:
Microservices: Yet another concept to fix the bad architecture created by bad software developers and to make money for big businesses that feed on the bad software practices of others.
An article on Medium writes "Conceptually, Microservices extend the same principles that engineers have employed for decades."2 Wrong. These principles have existed for decades, but "employed?" Hardly ever.
Similarly, a post on New Relic states: "When using microservices, you isolate software functionality into multiple independent modules that are individually responsible for performing precisely defined, standalone tasks. These modules communicate with each other through simple, universally accessible application programming interfaces (APIs)."3 Wait, we need microservices to achieve this? Wasn't this the promise of OOP? Isn't this the promise of every newfangled framework like MVVM, Angular, and so forth?
And of course, the pain killers that you use to mask the symptoms of the disease might help for a while, but the underlying cause does not get solved and they might cause more problems. Following this bad metaphor, microservices comes with some pretty heavy weight problems of their own:
- Potential performance degradation resulting from frequent messaging and/or large messages between services
- Deployment is more complicated (more deployment scripts, more versions, incompatibility between versions)
- Testing: should be simpler, but not necessarily, especially when you suddenly have 50 microservices that need to be up and running in order to test one microservice.
- Logging: ok, how do you reconcile all the different logs and time slots each microservice generates? Use a centralized logger? Maybe a microservice logger, haha?
- Versioning: suddenly a change in one microservice results in a recursive change to dependent microservices, and you discover that your supposedly modular architecture is actually a fragmented hell of code, projects, and solutions that are still entangled.
- Asynchronous calls to microservices: Right. Nobody wants to talk about this, it seems.
- Guaranteed intercommunication: so you have server-based or "serverless" microservices, possibly executing on a mix local hardware, remote hardware, virtual machines, and cloud-based servers, and something fails in the communication chain. Oops.
- Exception handling: Right. Again, something nobody seems to wants to talk about.
- Security: Suddenly you find yourself potentially maintaining SSL certs for different servers, firewalling each "serverless" engine, making sure you've closed ports, and opened yourself up to possibly additional public TCP/IP messaging and authentication/authorization issues. And being no security expert, that is probably just the tip of the iceberg.
So instead of the traditional article of what's so great about microservices and some ways to implement them, let's deal with the problems they present and come up with real reasons you'd want to use microservices.
Let's start with a somewhat idealized (but not ideal) concept of a monolithic web-based application that appears all too common:
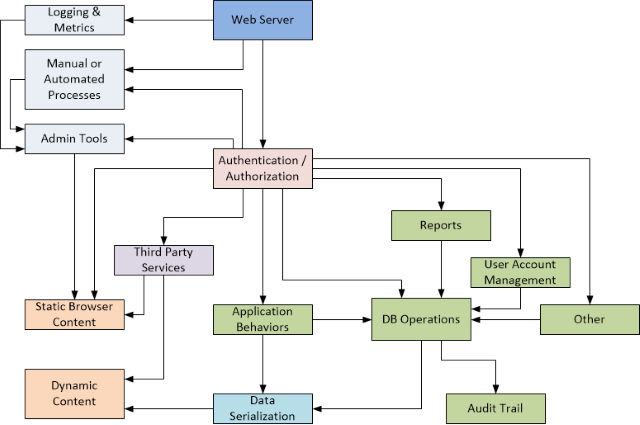
Granted, that actually looks pretty decent as high level blocks and arrows. Here, the web server is responsible for:
- Realtime logging and metrics
- Authentication and authorization
- Static content
- User account management
- Client reports (built in as well as custom)
- Interfacing with third party services such as GIS, social media, news/weather/stock services, and even communicating with client-local hardware (payment terminals, fingerprint readers, barcode scanners, etc.)
- Automated processes such as recurring usage reports, data cleanup, offsite backups (though usually handled by a completely separate process)
- Other services: payment processing, short term stateful data management like shopping carts, and so forth
- Application / business behaviors and logic
- Search / query and long term stateful data management, potentially including client-defined scripts for custom queries
- Audit trails tracking data changes over time
Events, as in endpoint calls from the client, trigger the majority of these pathways and processes.
Unless the web application is very small, I have personally never seen a large scale web application developed with a clean architecture. They probably exist, but the large scale web-apps I've had to work with are a nightmare of copy & paste code (both on the front-end and back-end), lack defined and documented APIs and lack clearly defined service boundaries, even if those services are logical services implemented directly in the main application or in supporting assemblies. This is regardless of:
- the programming language (C#, Python, Ruby, etc.)
- the back-end supporting framework (MVC, MVVM, Django, Rails, etc.)
- the front-end language and supporting framework (pure Javascript, TypeScript, ASP.NET, Angular, etc.)
It truly and sadly seems that very few developers and development teams have the skill to create well designed and well written applications. What's more is that conclusion is independent of whether the team is working with Agile, Waterfall, or ad hoc development practices. Also, the database architecture is not immune to this problem either as non-normalized databases and columns repurposed for other values than their original field name would imply seem to be the norm.
At best, the typical endpoint implementation often looks something like this:
[VariousAttributes]
public object SomeEndpoint(SomeObject thatWasDeserialized,
string decodedParam1,
int decodedParam2,
double etc)
{
MaybeDoSomeValidation();
MaybeThereAreMapReduceFilterOperations();
MaybeThereIsSomeBusinessLogic();
DoSomeDatabaseOperation();
var result = SerializeTheResult();
return result;
}
The above doesn't look that bad, as there are method calls for each step in the workflow. This is not reality. Instead, each of those nice method calls ends up being coded line, resulting in endpoint methods that are hundreds of lines of code, possibly hardcoded SQL, business logic that is custom to that endpoint call, and custom serialization of the result, often returning the entire object rather than the specific data the client-side needs, resulting in wasted bandwidth and excessive server-side CPU utilization. But I'm not writing about good architecture, I'm writing about microservices.
Your web-app has no architecture, has no well documented and well defined internal API, and you're on a Death March4 when it comes to adding more features, users, and fixing existing problems, created not by management but by our developer brethren or even ourselves. You can't refactor the code because there's no way to test it and it's too entangled with the rest of the code. But you can extract the usable pieces of the code and at a high enough level, redirect the endpoint calls into new microservices.
So here's the brutal truth to why you should consider using microservices: it provides the opportunity to start from a clean slate by extracting small pieces at a time and hopefully rewriting them with the experience of what you did wrong the first (or second or third) time. Yes, this can be achieved without reaching for microservices but the discipline to create true computational islands probably doesn't exist unless you use a paradigm like microservices that forces it down your collective developer team throat.
You may have the opportunity to utilize more current technologies -- how much of your code base is locked into a framework version two or ten years old because upgrading the framework would break everything? Though ideally, any dependence in a third party framework should be abstracted. You may have the opportunity to apply better OOP principles (abstraction, code re-use, etc.) Given that you're extracting a single noodle from the bowl of spaghetti, you probably will have the opportunity to write some API documentation.
And ideally, if done right, you'll end up with a true service that:
- can be re-used across many applications
- can be maintained and upgraded without affecting the rest of the application
- can be easily mocked for system-level tests
- is well documented
- is well tested
Refactoring ("the process of restructuring existing computer code�changing the factoring�without changing its external behavior"5) by itself does not achieve this goal because quite frankly, what microservices achieves is often changing the external behavior:
- The client-side may call the microservice directly (change to the endpoint).
- You'll probably end up changing the data interface, making it leaner.
- You may have additional endpoint calls to extend/improve/simplify the microservice behavior.
- Error handling might be changed or improved.
Because only a very small piece of the monolithic application is being extract, changing the front-end (or back-end call-throughs) is easier because of the limited scope of the changes. But this process is not refactoring -- your extracting code, ideally removing it from the original code base and putting it into its own computation island, or "box" where it stands alone and hopefully happy.
So let's refine the definition of microservices: Microservices are a viable path to reducing the monolithic architecture of the current application by extracting logical services into concrete and discrete implementations.
You already have an "always on" server to serve the web pages. Why would you create a separate instance for things like infrequently called endpoints? In a cloud-based architecture, the only way to reduce the cost of your current server "system" is if you can reduce the memory, processor architecture, bandwidth requirements, CPU performance and CPU utilization of the virtual server in such a way that the cost savings (what you are billed) are greater than the cost of servicing endpoint calls in a "serverless" microservice. Easier said than done, and determining if you're saving money can only can be determined over time and having a history of "before" and "after" the switch to a microservice.
The debate here is well stated in a post on The New Stack:
"It just depends hugely on what you are doing," he [Christ Priest] said. "The ongoing costs for microservices are far less than it would be for a monolith-based system. I think your costs could go down easily by up to 90 percent less. It depends on how bad it was in the first place." But the savings don�t just come by using container systems such as Kubernetes, said Priest. The savings also come through changes in the culture involving developers. With a monolithic infrastructure, a company can have 100 developers working on the same code, which can be a nightmare because their changes don�t jibe with those of others, adding to complexity and problems, he said. But under a microservices approach, developers can be independently working on different parts of the code, which allows more to be completed with less overlap and complication, he said. "Switching the team to a microservices way of work, you can get much more productive," said Priest, but again, it is hard to estimate the savings of such a beneficial move.6
I'm not sure I would buy into the "90%" figure, but this is an interesting point -- as I mentioned earlier, by forcing a paradigm down the collective developer team's throat, you can force a culture change that actually saves money. Not in the hosting of the services, but in the cost of development and maintenance. Unfortunately, the new problems that microservices create will definitely add cost back in, particularly when:
- Developers don't have experience with microservices and probably need to learn new technologies like container systems.
- Lack of developers requires bringing in so-called experts to educate them on how to deal with the issues mentioned at the beginning of this article.
- Retraining developers to use "the new way."
- Your IT department needs to learn how to support and secure containers, serverless compute engines, etc.
- Your support teams need to understand how to inspect logs in probably a different way.
- Your deployment team needs to write and support new deployment scripts.
- Your code base may need to go through recertification processes as new endpoints are exposed publicly and/or internally.
- Your security team needs to vet and monitor the microservice for security holes.
So yes, "it's hard to estimate the savings...", which makes the second half the sentence in the quote above: "...of such a beneficial move", questionable. Funny the way people phrase things when you really read what they say.
CIO writes:
"A variant of service-oriented architecture (SOA), microservices is an architectural style in which applications are decomposed into loosely coupled services. With fine-grained services and lightweight protocols, microservices offers increased modularity, making applications easier to develop, test, deploy, and, more importantly, change and maintain."7
Key points are that it makes applications easier to:
- develop
- test
- deploy
- change and maintain
Not really. Development is not necessarily easier, as microservices requires (as already discussed) a rethink / rework of how the application is segmented into separate services and how those services communicate with each other. Testing is not easier either -- the same issues with testing a monolithic application exist with microservices: do you have an architecture in which classes / methods can be mocked? Is your code written in sufficiently small units such that you can actually write unit tests? And by definition, a microservice limits the "system" testing because your only exercising one small portion of the "system." Deployment is not easier either. Each microservice requires some kind of deployment script or process, complete with its own and hopefully unique credentials for performing the deployment. You know have many scripts/processes rather than a single script/process. And as mentioned earlier, a change in one microservice may require updating dependent microservices which complicates coordinating the update. Let the buyer beware!
As the The New Stack article states:
Also smart is to avoid creating services that are too micro, he [Christ Priest] added. "There is overhead for each new service and that should be taken into account and balanced against the benefits in terms of velocity of decoupling the architecture. Tools like Kubernetes can help reduce that overhead and complements a microservices approach." Meanwhile, using a container platform rather than just raw virtual machines can also increase efficiency and reduce costs, he said. "This isn�t microservices, per se, but is often paired with that type of architecture. It isn�t unusual to see utilization go from less than 10 percent to less than 50 percent. This can drive huge savings from reduced hardware, data center or cloud usage, as well as reduced administrative costs."6
Some of the "serverless" solutions I've encountered are built around the idea of one microservice per endpoint. If you want to support multiple endpoints with different subpaths (foo/bar and foo/foo) dynamically (as opposed to manually mapping the function on the API gateway) you end up having to write a little micro-router to support that. I might be mistaken, but Amazon's AWS Lambda is like this, requiring you to parse the input string or stream and creating your own router to handle subpaths. Not sure about Azure compute functions.
Regardless, "serverless" solutions are often not the ideal platform for microservices because a serverless solution is really more a "nano" solution -- typically implementing one function that is exposed an internal or public URL. One of the challenges with microservices is to not make them too small, and yet at the same time, avoid becoming a monolithic arm that is merely an extension of the monolithic body.
Some microservices are good candidates for serverless computing: "Serverless computing (or serverless for short), is an execution model where the cloud provider (AWS, Azure, or Google Cloud) is responsible for executing a piece of code by dynamically allocating the resources. And only charging for the amount of resources used to run the code."9 A good case for a serverless platform is when your microservice is called infrequently and/or the computation time of the microservice outweighs the performance penalty of cold-starting10 the container. That in itself is a double-edged sword, as most cloud providers will time out the serverless function call within seconds (and for some, like AWS, this timeout is configurable.) So it becomes a decision point, guided by what the microservice is doing and how often it is called, to determine whether a serverless or server platform is best suited for the microservice.
I can't call this section "problems and solutions" because there aren't necessarily true solutions. Instead, there's more a set of guidelines one should follow when implementing a microservice-based architecture. So let's look at each problem. Keep in mind that this is going to be a fairly high level look at the problems and suggested guidance. A good article on the problems with microservices can be found on Medium: "Microservices Architecture - problems you will have to solve"8 by Justin Miller. Also take a look at Microsoft's "Designing a microservice-oriented application."11
It should be obvious that any time one process needs to talk to another process that doesn't share the same physical memory space, some sort of serialization / deserialization of that data has to take place. This takes time. The usual way for a microservice to communicate is over HTTPS with REST calls, typically with JSON as the serialization format. And, of course, the data being returned needs to be serialized by the microservice and deserialized by the destination.
- Transmit only the data the microservice endpoints actually need to perform their task. Don't serialize the whole object structure, which also creates entanglement between the sender and receiver.
- Consider using a custom serializer. JSON and XML are very verbose. Do you really need the keys and tags as human readable text, or can you send the data in a binary format that only the machine understands?
- Disable compression. Compression of small data packets is a waste of CPU time and achieves little, if any, compression.
Deployment should not be complicated, but can be made as complex as you want. Avoid complexity!
- Come up with a consistent strategy for deployment for all microservices. Don't have one script written in different scripting languages. Don't use the development tool (like Visual Studio) to do the deployment.
- Consider a simple front-end that lets you check off what you want to deploy. Tooling should make life easier by reducing typing, mouse clicks, and hide complexity.
- Write microservices such that you don't have a nested calls of microservice calls. Instead, have a master endpoint entry that sequentially (or asynchronously) calls each microservice.
Regarding the last point:
Wrong:

Better:
This implementation is better because:
- It reduces the complexity of error handling.
- Allows for asynchronous calls to each microservice.
- You're only testing one microservice, not the entire nest.
- Decouples dependencies between each microservice, which makes deployment easier.
Testing a microservice shouldn't be any more difficult than testing in a monolithic application. In fact, testing should be easier because the microservice should be implementing, as much as possible, a limited set of endpoints and small set of behaviors. The issues with testing are very much the same with any piece of code:
- The microservice endpoint should only be responsible for deserialization, calling smaller "unit" methods, and serializing the result. Do not implement the endpoint with all the deserialization, business logic, database calls, third party calls, and serialization.
Wrong:
Stream Endpoint(Stream input)
{
var deserializedData = Deserialize(input);
... inline code that makes DB calls ...
... inline code that makes third party calls ...
... inline business rules ...
... inline further map/reduce/filter ...
return SerializedResult(whatever);
}
Better:
Stream Endpoint(Stream input)
{
try
{
var deserializedData = Deserialize(input);
var result = DoSomeWork(deserializedData);
return SerializedResult(result);
}
catch(Exception ex)
{
return SomeUsefulInfoAboutTheException(ex);
}
}
ResultObject DoSomeWork(InputObject obj)
{
dbService.DoNecessaryDBStuff(obj);
thirdPartyService.CallIt(obj);
businessRules.RuleA(obj);
businessRules.RuleB(obj);
additionalFiltering();
}
The important thing to notice here is that even a microservice as internal services, which makes the internal service mockable, and that is a big step toward making unit and system testable code.
Once you go down the microservice route (for better or worse) you can quickly end up with enough microservices that logging becomes a new complexity, particularly if you have nested calls to other microservices, which as mentioned above, you should avoid like the plague if possible! Even serial calls to different microservices, and particularly asynchronous calls, can become a logging headache with regards to synchronizing and disentangling the logs.
- Use a third party logger like PapertrailApp (now Solarwinds) or similar, like LogEntries. More options here.
- Include tags that identify:
- The microservice name and version
- The entry function
- Possibly parameters -- if you include parameters, consider security issues and encrypting / redacting certain parameters)
- Don't pollute your log with one-time debugging stuff that you used when developing / debugging the microservice
- If you don't have a good answer as to why you're logging something, then don't.
- Implement different logging levels.
- Always log exceptions, but with useful information. Stack traces are usually useless since there's no debug information (line numbers, code modules, etc.) Exceptions need to be fine-grained so that you really know what threw the exception.
As with logging, you may find yourself looking at charts and graphs from several different cloud providers or separate URLs that you have to manually inspect within the same cloud provider. It becomes a time consuming and ineffective to monitor each service this way.
- Create alerts so that you only need to look at something if it exceeds your expected parameters of operations.
- Look at what APIs the cloud platform provides so you can create a tool for unifying the monitoring into a single consolidated realtime application.
In a monolithic application, change a method signature immediately identifies all the places you need to fix it (at least with a sane strongly typed language.) With a microservice architecture, you lose that because, like with the front end, the communication mode is typically an HTTPS REST call. This means that you're serializing an agreed upon data structure but without necessarily a way of determining at compile-time whether that structure has changed. Thus...
- If possible, use a common class (defined in a DLL) that both the caller and the microservice use for sending information and returning information. That way, if you change the structure in one place or the other, you can be notified of breaking changes at compile time.
- Data goes into the body of the message. Don't use URL parameters. URL parameters are too unstructured and subject to breaking changes.
- Have a single call point (method or function) that calls the microservice. That way, if you have to change the data structure, you can fix it in one place and work the dependencies backwards from there.
- If absolutely necessary, create a completely new endpoint so that (at least temporarily) you can maintain the legacy call and the new call simultaneously. Remove the legacy call as soon as possible.
At some point, you'll probably have to deal with a service that kicks off a long running process that the client will want some notification back when it completes. This is an obvious candidate for an asynchronous call. Not so obvious is the potential benefit of calling several short running services asynchronously. Either of these is somewhat of an edge case -- ideally, your service calls should return within seconds and certainly before the REST call gives up on the response. The long running process (one that exceeds the REST call timeout) really has no other solution than to notify the caller when the process is done. If being called from a server and assuming the client doesn't care about when the call actually completes, you can simply call POST the result back:
The problem arises when the client does care. Here, we have two scenarios:
- Short running microservice processes that where we don't have to worry about the REST call timeout.
- Long running microservice processes that exceed the REST call timeout from the client.
In the first scenario, we can do something like this:
Stream EntryPoint()
{
var tasks = StartAllAsyncTasks();
Task.WaitAll(tasks);
return someResult;
}
This of course fails completely when the service takes so long that the REST call times out. Now what? Given that this article has as its backdrop the idea that you're hosting a web app, the "client" is of course the browser. If the client is another server, the solution is easier -- the server can provide its own callback URL for when the process completes, which can look something like this:
The real problem is the browser client. Other than polling (yuck), we have to resort to Websockets to notify the client of completion. This is can lead to a complicated "return of results" path depending on where the client call is received. If the websocket connection is opened to the server, it is the server that must respond on that connection:
If the client opens the websocket directly with the microservice, the process is simpler:
- Short running microservices are ideal, enabling you to implement asynchronous calls without needing a separate "callback" communication channel for when the service completes.
- If you have a long running microservice, consider the options for whether the client needs to be notified of completion, and if this is required, what is the best approach. While I'm not enamored with polling, there are situations where it may be the best and most appropriate solution.
- Have the client call the microservice directly as opposed to going through a middle layer server.
- Have a fallback / recovery implementation (like polling) for when the websocket connection fails while waiting for a result.
- Asynchronous implementations are best used in "read" operations. See the next section for "write" operations.
Something of a continuation of the section above, there are times you want a guaranteed message delivery, either as a fire-and-forget or fire-and-acknowledge implementation. Messaging queues such as RabbitMQ13 and MSMQ14 are two of many options between "servers." Look at options like STOMP15 for a Javascript (not Node.js) web application client-side option.
- The purpose of a guaranteed message is so that when the client calls the server, especially when updating data that involves one or more microservices, you want to ensure that at some point (particularly in an asynchronous operation) the message is actually handled by the microservice. The client may not be able to be notified of an "internal" failure on the server side.
- The question that you should be asking is, why should I use an asynchronous and possibly multi-layer server-microservice architecture for persisting data? And the answer is, you probably shouldn't be unless you have a very good reason to do so. But if you have to, look at message queues for guaranteeing the write / update / delete operation.
- Really, nothing prevents the user from closing the browser while the data is in-flight. That makes life quite an adventure and while it's the user's fault, you'll take the blame for lost data. So data writes should really go directly to the "server" that is either writing the data or can guarantee that at some point, the data is written.
Exceptions in microservices can be difficult to diagnose and debug because any useful information either has to be percolated up to the top level call where it can be inspected, or logged, again with enough useful information to understand the problem.
- Have a consistent strategy for handling exceptions. This should include:
- A separate log just for exceptions
- A consistent means of gathering the information relevant to the exception such input parameters and the exception message itself
- Since debug information is not typically available:
- A
try-catch block that wraps the entire API method is not that useful. Use try-catch-throw around every "logical" section in the API method.
- Read my article on logging exceptions.
I am no security expert, or even novice. The guidance here I've cobbled together from other sources.
- Use HTTPS! Make sure HTTP is disabled!
- Use authentication / authorization for the non-public API entry points. This is your last line of defense, but an important one.
- Someone needs to thoroughly understand:
- How to set up security policies
- How to test that those policies are set up correctly
- How to keep up to date with policy updates from the provider.
- Audit your policies at regular intervals.
- Use the most restrictive permissions you can get away with when creating policies.
- If you're self-hosting, set up your firewall correctly.
Don't get caught in the hoopla of microservices. This includes the promises of lower cost and improved productivity. Don't buy into the ancillary technology. This includes Docker, Kubernetes, AWS, Google, and Microsoft. There's no reason you can't host a microservice in a Linux OS on DigitalOcean12 for $5 a month running C# .NET Core code. Look before you leap, and have a good reason for why you're leaping. Using microservices as a way to start teasing apart a monolithic application is a good reason.
1 - https://en.wikipedia.org/wiki/Microservices
2 - https://medium.com/@justinamiller_1857/microservices-architecture-problems-you-will-have-to-solve-4153cfbde713
3 - https://blog.newrelic.com/technology/microservices-what-they-are-why-to-use-them/
4 - https://en.wikipedia.org/wiki/Death_march_(project_management)
5 - https://en.wikipedia.org/wiki/Code_refactoring
6 - https://thenewstack.io/microservices-pricing-whats-it-all-going-to-cost/
7 - https://www.cio.com/article/3201193/7-reasons-to-switch-to-microservices-and-5-reasons-you-might-not-succeed.html
8 - https://medium.com/@justinamiller_1857/microservices-architecture-problems-you-will-have-to-solve-4153cfbde713
9 - https://serverless-stack.com/chapters/what-is-serverless.html
10 - https://medium.com/@kevins8/benchmarking-lambdas-idle-timeout-before-a-cold-start-cbfd7ef97c18
11 - https://docs.microsoft.com/en-us/dotnet/standard/microservices-architecture/multi-container-microservice-net-applications/microservice-application-design
12 - https://www.digitalocean.com/
13 - https://www.rabbitmq.com
14 - https://en.wikipedia.org/wiki/Microsoft_Message_Queuing
15 - https://www.rabbitmq.com/web-stomp.html
- 15th July, 2019: Initial version

