The present paper is making an analogy between the common design of a large scale information retrieval software (search engine) and the anatomy of brain cortical columns. The conclusion is that they are organized very similar and the role of cortical columns may be to store, retrieve and process information, together with an "index" area.
Introduction
Human brain is accessing information with incredible speed. Old memories are brought into the present almost instantly. Scenes involving a person we are thinking of are coming into view in seconds. We recall a memory by elements involved, persons, animals, objects, etc. When we reimagine a scene, we mostly figure out entities and less low level details. Someone real face may trigger a pattern directly linked to some old memories but we can do the same without any visual input, simply by trying to remember that person.
It is obvious that some mechanism for fast information retrieval should be present in our brains.
The Index
Suppose that we have a huge number of numbered written pages with various content (page 1, 2, 3...). Some of these pages may contain the "cat" word. If we want to retrieve all pages containing the "cat" word, we need to read each page one by one. The time required to retrieve all "cat" pages is obviously huge.
But there is a solution to this problem. We can read all pages once and write down all pages containing "cat" word in a list (3, 5, 18, ... etc.). The next time we want all "cat" pages, we do not read all of them again but look into that list and go straight to those pages. The time to retrieve all “cat” pages goes down with many orders of magnitude. In reality, on a computing device, the retrieval time is several milliseconds.
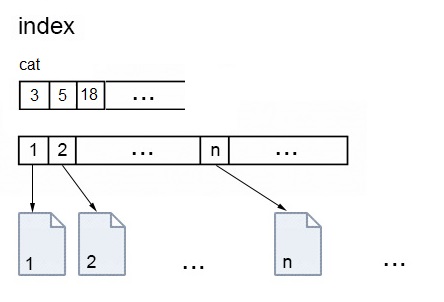
The first time we read all pages, we can also put down other words and the pages they are present in:
cat - 3, 5, 18, ....food - 4, 5, 23, ....
This will allow fast retrieval of pages with any word that can be found in those pages. We can even make an intersection (for example, page 5 contains both “cat” and “food”) which is actually how search engines work.
This list with references to data that allows much faster access is named "Index", and the operation to build it is "Indexing". Now we can imagine that instead of written pages we can have labelled images. We can index those labels and retrieve all images with cats almost instantly. Or instead of images, we can have experiences, memories, scenes, contexts / pieces of life, some of them involving cats. If the "cat" entry in our index points to those containing cats, we will retrieve all scenes with cats instantly.
We can even make index of indexes (or layered indexes) so the amount of information to access is huge.
Overview of a Search Engine
In order to retrieve information on large scale, some software systems build big indexes. First, some computers download many pages from internet websites, read all words inside them and build indexes containing not only a page number for each word but a rich metadata (retrieval date and time, URL of the page, a score inside that page etc.). For example, on a single computer, we may have an index like this:
cat:
page 1
url: www.cats.com/syamese1.htm
date: 2019-04-05 13:44:22
score: 35/100
page 2
url: www.cats.com/syamese2.htm
date: 2019-04-05 13:44:23
score: 38/100
The score may reflect how cat is relevant to the content, if it appears in titles, occurrences count, etc. When we want all “cat” pages, the search engine makes a list from index with all cat pages, then orders them by score and shows us the most relevant ones. If we search for "cat food", the system intersects "cat" pages with "food" pages and shows us an ordered list with pages containing both words.
A Search Engine Node / Cluster
Basically is a single computer, at the time Brin and Page made Google, it was quite weak after today's standards. This computer builds and holds his own index, also can retrieve data from it. Some architecture may split this in 2 computers though, one for indexing, one for data retrieval.
So, a search node contains a local index file and software that performs the following operations:
- data storage: It crawls the internet, downloads pages, parses words inside each page, puts pages references and their metadata in the local index file.
- data retrieval: On some external query (
cat), it inspects the index file and returns to the caller the pages containing those words. - data processing: It has its own software and advanced algorithms for processing pages, build and read the index file.

Because of software format constraints, this computer can hold the cache of 10-20 millions written pages. When they built Google, the creators were very concerned about optimizations and data transfer on 16 bits. The time to retrieve pages for a query is several milliseconds.
Multicluster Architecture
A single cluster / node can hold information related to 10-20 millions of pages (year 2000), which consist of about 10 Gigabytes of data (index and pages cache). What if we store more pages on different nodes and query all of them at once? If we distribute this architecture, we can basically index an infinite number of pages.
So if we have a central unit that receives a query "cat" and distributes it to one million clusters, they all can start together and inspect their own index for pages containing "cat". The time is basically the same as for a single cluster, as they all work in parallel. Top results from each cluster are put together, re-ranked and presented to the user. The data inspected is enormous, as we have one million clusters each containing 10-20 gigabytes of data. The time to distribute the query to all clusters is negligible as it is transfer only, no data processing. This way, Google shows the results for "cat" in several milliseconds, checking billions of pages. To index the whole internet, Google has server farms with millions of nodes.
Cortical Columns as Clusters
There are a number of assumptions about the purpose of the cortical columns. My theory is that the role of a single cortical column is the same as a node in a search engine. A cortical column retrieves its own data, processes it and presents it to a caller just like a search cluster. In the same time, it may build or helps at building an index stored in upper levels. Based on multiple similarities, the current paper assumes that brain works like this:
- Let's consider a cat experience (scene), a toddler sees a
cat for the first time, he tries to touch it, the cat maybe meowing, the mom says "Andrew don't touch the cat". - The experience is recorded through senses (eyes, ears) and the full scene is stored straight into a new cortical column (or more) in specific sensory areas.
- While storing it, the scene is decomposed in elements (concepts, entities):
mom, cat, sounds. - As the toddler has already dealt with some of these concepts before, they already exist in the central memory (limbic area). If it's a new concept, it will be added to concepts list.
- The new cortical column which stores the full scene is then linked to the concept stored in limbic system, the same way the index points to a new page. So "
mom" now points to this new column too. - Each concept in the limbic system stores a full list of cortical columns they are related to, just like an index file (or could be some intermediary levels doing local indexes).
The biggest assumption here is there is an Index (possible into limbic system) containing existing concepts (there are about 1 million words in English dictionary, the total number of possible concepts cannot be far). This Concepts Index structure links each concept to the related cortical columns (scenes where they occur). Architecture with local indexes for each sense / zone is also possible in levels superior to columns. The neural plasticity helps to create new neural connections for new scenes that move the current column to the next, as in electronics.
The main argument that the brain and cortical columns are working this way is that there is no other known method better today to look up in million of scenes recorded in a lifetime in milliseconds than an Index, and the brain does this. We do not know where this Index is but we have columns and barrels similar to search clusters. So the secret of cortical columns reside not in their structure but in what they are connected to. And from there, we may figure out what exactly they are good for and how they actually work.
More Arguments
- Neurologists cannot figure out what cortical columns are storing by looking at spiking neurons (assuming they do this on living creatures). It's practically impossible to observe that the whole brain is a large scale information engine, as it requires not only math and computers knowledge but also the luck to ever design such a system.
- It is also extremely difficult to follow axons wiring. But if we know what to look for, it may help. The axons involved in passing information to columns are also less than 16, the number of bits used in the original Google design.
- The stored information also contains metadata related to time and location of the event at the recording time (just like indexing).
- A cortical column is directly linked to senses just like a node retrieves its own pages and processes them.
- The information is modular as losing part of the brain can lead to memory loss but the processing still remains and it can be redistributed. In case of some clusters failure, the search engine still provides relevant information from remaining clusters.
- The similarity is astonishing, even the amount of information stored by a node has somehow the same order of magnitude, 20GB vs. 150GB (a cortical column with 100-200 neurons is believed to hold equivalent of about 150GB of information).
Remaining Questions
The answers to the following questions may confirm or complete this theory:
- Where is the Concepts Index in the limbic system?
- Are there more Concepts Indexes in each brain zone, per senses?
- How the Concepts Index adds new concepts and wires them to new columns?
- How the answer from cortical columns is wired back to the Concepts Index?
- Once Concepts Index has been discovered, how concepts are combined to perform logic?
- What horizontal connections between columns serve at?
Conclusion
The main role of cortical columns is related to information retrieval and some "Concepts Index" structure may be present in the limbic system or in upper levels of cortical columns. There are a number of open questions that can complete this theory and reveal more understandings about brain.
As seen in the present paper, if the theory proves valid, to cover all required knowledge to properly reverse engineering the brain, a new discipline may be needed and it should include the following directions: mathematics, neurology, anatomy, computer science, electronics.
References
History
- 23rd July, 2019 - First submission

