Introduction
If you're fed up with the endless pain of micro-service systems, which database transactions, distributed locks, endless system optimization, inexplicable stuck, weird performance fluctuations, let's try the latest lock-free programming technology. The cool thing about this technology is that it can develop distributed systems without database transactions and distributed locks. It is well known that the abuse of distributed locks and database transactions leads to the problem of distributed system coupling.
In the second article in this series, I did a distributed system analysis of an open source e-commerce software. You can click on the link below to find this article:
Here, I have used AP&RP theory to transform this project into a distributed system. In the process of server software development, as the number of users increases, we will encounter bottlenecks in server performance. In order to solve the bottleneck of server performance, it is necessary to split the server to different hardware to improve the overall carrying capacity of the cluster. Without AP&RP theory, this service-side splitting was very inefficient. Usually, a large number of database transactions and distributed locks are introduced. These database transactions are intricate and eventually make people lost in system coupling. By learning AP&RP theory, you can have the ability to write lock-free distributed systems. The example used in this paper is the first lock-free distributed system developed by AP&RP theory. In order to illustrate the universality of AP&RP theory, I chose the most common online shopping mall system as an example. Because of its moderate complexity, it is suitable for beginners to learn. The source code is made public on github.com. The link is https://github.com/gantleman/shopd or you can get it by downloading the attachment to this article.
Performance Improvement
Evaluating whether a system reconfiguration is really effective can be concluded through performance comparison. This paper is based on the transformation of Manphil/shop project. The original project is a very simple and clear online shopping mall system. It consists of a server and a database. The server consists of 62 tasks.
Suppose its server and database run in two server containers respectively. Revamp 62 tasks on the previous server to share a server container. We transformed it into a distributed system. According to AP&RP theory, 62 tasks can be divided into three types. The first type is that multiple tasks must be placed in a server container. The second type is that a task can be placed in a server container. The third type is that a task can replicate multiple copies into any number of server containers.
The first type of task consists of 30 tasks divided into eight groups, which can only be put into eight server containers. Among the eight groups, there are 7 tasks at most and 2 tasks at least. Before the transformation of distributed system, the resource allocated by each task is 1/62 of a server container. The resources allocated by each task in the server container with the most tasks after the system modification are 1/7. It can be seen that after the transformation of distributed system, the server resources obtained by single task have increased by at least 8.8 times. Similarly, the resources available for the second type of task increased by 62 times. For the third type of task, because it can be copied to any number of server containers, there is no limit to the performance improvement, which increases with the increase of hardware. Because the first type of task accounts for 48% of the total number of tasks. So for 48% of the system, the performance is improved by 8.8 to 62 times. For the remaining 62% of tasks, unlimited performance improvements can be achieved.
The write limit of single Berkeley DB is 100,000 per second. Seven tasks can be assigned to about 10,000 tasks per task. Because these seven tasks include the task of order completion. So the theoretical load-carrying limit of order completion function of this website is 10,000 per second. The peak number of orders per second in promotional activities on the world's largest e-commerce website is 80,000. So this distributed transformation can theoretically make the software performance reach the top level in the world. Of course, this large-scale distributed system also needs a lot of hardware as support. We cannot rely solely on the improvement of software system performance.
Installation
Development environment: Ubuntu 16.04.4, vscode 1.25.1, mysql Ver 14.14 Distrib 5.7.26, redis 3.0.6, maven 3.6.0, java 1.8.0_201, git 2.7.4.
Software framework: SpringBoot, JE.
After installing the above environment, execute in the root directory:
>mvn install
Then import shop. sql into MySQL database.
>mysql -h localhost -u root -p test < /shop.sql --default-character-set=utf8
If you use the VSCode editor, you need to add the launch.json file:
{
"version": "0.2.0",
"configurations": [
{
"type": "java",
"name": "Debug (Launch) - Current File",
"request": "launch",
"mainClass": "${file}"
},
{
"type": "java",
"name": "Debug (Launch)-DemoApplication<shopd>",
"request": "launch",
"mainClass": "com.github.gantleman.shopd.DemoApplication",
"projectName": "shopd"
}
]
}
Edit the application. properties file to configure the database address and account password, as well as the server port number.
spring.datasource.url=jdbc:
mysql:
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driverClassName=com.mysql.jdbc.Driver
server.port=8081
Click F5 to start debugging mode.
Open the browser and enter http://localhost:8081/main to open the home page.
Description of Distributed Systems
In the past, designing a software system was like building a stone bridge. Once the construction is completed, it will be very difficult to make major changes. And the application scenario of software is like a changeable river. We should not only ensure the normal use of stone bridges, but also help stone bridges to make changes because of changing needs by building ancillary facilities. When the stone bridge is really unusable, it is being demolished and rebuilt. What software distributed engineering needs to change is to make an umbrella that can be dynamically changed, that is, it can be conveniently collected, and it can also support the needs of different weather. So you can see that the system architecture diagram can shrink like an umbrella. Support systems are rapidly expanding from one point to another.
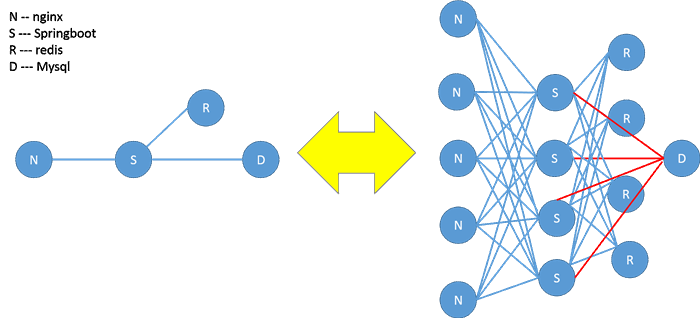
This distributed system is composed of five parts: nginx reverse proxy, spring boot server, reids memory database, MySQL database, and distributed manager which has not been developed yet. There is also a JE database that runs independently. Distributed Manager does not have a separate entity in the current version. It is responsible for managing the data release of the routeconfig field in redis database. So we need to run the test routine T7 () function to achieve data publishing in the routeconfig field.
Mysql servers are not needed if microservicing is split according to pure AP& RP theory. The first version follows the original AP&RP theory. First, we need to analyze the data according to the function of reading and writing. This part of the work is done in ITDSD2 and stored in the shop.xlsx document, which you can find in the download area. The analyzed data are stored in each JE database in advance according to the function of reading and writing. Users call Springboot servers with corresponding functions through nginx. Springboot service publishes the data to redis memory database.
In the latest version, a caching mechanism is introduced to effectively manage distributed systems. The cache mechanism can read part of the Mysql database to the JE database. Without using these cached data, you can write the data back to the Mysql database. Different from the caching mechanism in other distributed systems, this caching mechanism uses a page caching architecture. Avoid using non-existent data to trigger read caches repeatedly. It also improves the random hit rate of the cache. Its effect is better than exchanging data one by one in distributed system.
Here, we have successfully created a single debugging environment. How to deploy the distributed system? Just create an nginx reverse proxy server. According to the analysis results shown in shop.xlsx file, create a springboot server for distributed tasks and modify the corresponding routeconfig field. Suppose we put the /admin/activity/show task on a separate server. The shop.xlsx file shows that the /admin/activity/show task belongs to multiple types that can be copied at will. So just create a springboot server and set the port to 8082 and modify the routeconfig field in redis. And modify the nginx of the reverse proxy so that the call to /admin/activity/show port to 8082. The admin/activity/show task is separated.

In the cluster state, the server requests from the nginx reverse proxy server to the spring boot server. The Springboot server checks whether the page cache is hit. Input data from the MySQL server if there is no hit. The current Springboot server calls in the data and publishes the data to the redis server for reading by other Springboot servers. Other Springboot servers read data from redis servers if it does not exist. Triggers the Springboot server responsible for managing the specified data to update the cache. Note that the Springboot server, which is not responsible for managing the specified data, does not have the right to read the specified data directly from the MySQL database. Only the Springboot server responsible for managing the specified data can be notified to operate.
Indexing and caching
Perhaps you've noticed that all the data in the architecture diagram eventually points to the database. In order to enable distributed systems to have the ability to quickly expand and retrieve. First, you need to store the data set at one point. Then the data is expanded to the spring boot server by caching. Each spring boot has jurisdiction over a small portion of the overall data. This small amount of data exists as a data cache on spring boot. We can call a database the source of data. Because each spring boot has its own JE database management part of the data when the distributed system runs. In the distributed quantitative analysis, we get "Theorem 1, the network composed of single-threaded servers sharing data must be asynchronous network". Theorem 1 defines distributed systems from a network perspective. Then we can get Theorem 2 from the perspective of data usage.
Theorem 2: In a narrow sense, distributed system is a system that supports two or more tasks running simultaneously. Each task can only use part of all data sets at run time.
Assume that the data used by any task in a distributed system is the entire data set. Then other tasks must wait while the task is running. That is to say, the whole system will not accept requests from other tasks when the task is running. To wait for the current task to run. This contradicts our assumption that this is a distributed system.
The deployment process of a distributed system can also be regarded as the process of partitioning and caching the whole system data set. In addition to completing the normal function of "add, delete, modify and check", the database should also provide complete index data. In order to determine whether the cached data meets the needs of current use. Corresponding to the "add, delete, modify and check" function of some data sets, the operation is based on the whole data set. For example, the total number of users in the statistical database, the average price of goods. The operation of these complete data sets and part of the data sets constitute two distinct directions of the database. For example, the use of high data will inevitably lead to other tasks in the database can not run. Two tasks using only 2 and 4 data can be parallel.
Index and "add, delete, modify and check" constitute the basic operation of database. These basic operations combined with data caching constitute the basic model of using data in distributed systems. We can't expect a database to be a universal database. Although this trend is very obvious now. One is a distributed, computational, arbitrary partitioning and large data query database, which can no longer be called a database. It is against scientific common sense to create a universal system that can handle endless product functions. But we can create a system with limited functionality. This system handles the limited functional requirements and satisfies all potential situations under this requirement.
Code Analysis of Index and Cache
Using AP&RP theory to split micro-services is very simple. There are also very few changes to user-oriented product logic. The biggest problem in the reconstruction process is to build index and cache page scheduling. Redis does not support index building, so it needs to build by itself using map and set structures. JE database originated from Berkeley DB and supports indexing, but the index structure is completely different from Myslq. When reading data from Mysql database into JE database, it is necessary to recreate the index. Mysql database does not provide indexed data to users as separate data. Index data can only be used indirectly through instructions. This is related to the fact that index data is heavily dependent on data structure. Indexed data can change as data sets change. So in engineering, you can see a lot of code that builds indexes and loads caches.
Take the getAllAddressByUser function as an example. See code notes.
@Override
public List<Address> getAllAddressByUser(Integer userID, String url) {
List<Address> re = new ArrayList<Address>();
if(redisu.hHasKey(classname_extra+"pageid", cacheService.PageID(userID).toString())) {
Set<Object> ro = redisu.sGet("address_u"+userID.toString());
if(ro != null){
for (Object id : ro) {
Address r = getAddressByKey((Integer)id, url);
if (r != null)
re.add(r);
}
redisu.hincr(classname_extra+"pageid",
cacheService.PageID(userID).toString(), 1);
}
}else {
if(!cacheService.IsLocal(url)){
cacheService.RemoteRefresh("/addressuserpage", userID);
}else{
RefreshUserDBD(userID, true, true);
}
if(redisu.hHasKey(classname_extra+"pageid",
cacheService.PageID(userID).toString())) {
Set<Object> ro = redisu.sGet("address_u"+userID.toString());
if(ro != null){
for (Object id : ro) {
Address r = getAddressByKey((Integer)id, url);
if (r != null)
re.add(r);
}
redisu.hincr(classname_extra+"pageid",
cacheService.PageID(userID).toString(), 1);
}
}
}
return re;
}
Cache loading and index creation are usually mixed together. If the index does not hit the cache, that needs to load the relevant index data. Because of the distributed architecture, only part of the data is stored in each server. Therefore, global data retrieval should be strictly prohibited. For example, dynamically check all addresses under the user name. So I created the address_user table in the database to store the ID of all addresses under the user name. If there is no address_user, a global query of the database address table is required every time the user address is queried. Because the index data of address_user exists, I only need to get the index data of the corresponding user to know his full address ID.
Cache management is implemented through cacheService. I used the ID of the table as the partitioning token of the cache. This allows you to easily calculate the current page by ID. Of course, such a simplified way of writing will lead to the search function of pure text categories such as name, category, commodity search can not achieve page caching. After commodity search, it will be realized by means of big data. Named data can be used in the form of bit matrices. These may be achieved in subsequent improvements.
Conclusion
This is the first example of lock-free programming in distributed architecture, and I'm sorry that he's not a framework yet. For programmers who want to implement lock-free programming in distributed engineering, this example can be a good start. Distributed systems using similar designs will no longer be affected by the coupling between distributed locks and database transactions. Because the system designed according to AP&RP theory does not have distributed locks and database objects, the software development of super-large multi-person interaction system will step down the altar. Ordinary programmers can also get started easily. I think this will promote the popularization of server-side software very well.
History
- 24th July, 2019: Initial version

