Introduction
In the previous article , we discussed and implemented core accounting infrastructure design: general ledger, chart of accounts, (source) documents and financial statements structure.
This article will be dedicated to the finalization of accounting infrastructure design: company profile, person profiles, costs centres and all the other entities that are used across all of the specialized accounting documents.
Localization in Accounting Application
Localization is usually defined as customization of an application for specific cultures or regions. Localization consists primarily of translating the user interface. However, in the financial accounting domain, we handle not only numbers and codes but also some amount of textual information. Fortunately, the amount of textual information is very limited. In addition, not nearly all of the textual information requires localization. E.g., there is no point in localizing data that is only meant for internal use like descriptions of documents, fixed assets, internal comments etc. Only the information that is (potentially) visible externally needs to be localized.
Notably, there is a legal requirement for financial accounting that all of the accounting records and documents shall be kept in national language. (I believe it’s true for pretty much all of the jurisdictions) The common exceptions to the rule are the (source) documents issued by persons in other countries, e.g., you don’t need to translate an invoice issued by some German company. Which brings us to the requirement that all of the textual data should always exist in the national language of the company’s registration country. The localization of textual data in the financial accounting domain means providing extra textual data translated into the native/understandable language of the person that the data is meant for, i.e., you need to keep such data both in the national language and in the language required by the person involved.
Having in mind the scope of the application we develop, localization will be required for the following documents:
- Invoices made
- Pro forma invoice made
- Cash receipt
The document specific textual data and its regionalization will be handled by the documents themselves, i.e., within the tables that extend document table for specific document type. However, there is one common data piece for all of the documents – company’s data. Therefore, the company’s profile should be localizable, i.e., there should be:
- A common company’s profile that contains language agnostic data (company’s official name, various codes, id’s, emails, defaults, policies, etc.)
- A localized company’s profile for each language that the company uses (address, contact info, CEO title, etc.)
Another common data piece for all of the localizable documents is person (profile). However, as you will soon see, there are no textual data within person profile that could reasonable require localization. Official names cannot be translated. Hardly anybody would require translating an original address in a foreign country. The rest of the person data is about various codes, ids and defaults that are not subject to translation. Therefore, there is no need to implement localization for a person profile.
Actually, most of the companies use some billing or CRM systems to issue invoices as well as cash receipts. The data from such systems is then automatically transferred to the accounting system, typically via REST service. In such cases, localization of an accounting system is not required at all trivially because the international data is handled by other applications and an accountant only require textual data in the national language. However, we are also targeting a small business that at least to some extent uses accounting system for billing. Therefore – localization.
Versioning in Accounting Application
In theory, every time a (source) document is received (or is issued) by an accountant, he shall record it and never change or delete it. In real life, typos happen all the time and accountants are not willing to do corrections in the right way by issuing adjustment documents like a credit note. This is especially true for small and medium business. So, the UD part of CRUD is technically illegal, but is a must for the target user group. For the very same reason, there is no such thing as document version in the accounting domain. If a particular company wants to use detailed audit trail, it can use extra solutions for it as discussed in the first article in this series (SQL server binary log, custom log with serialized documents, etc.). Most of the companies that we target will not want or need such a functionality. Notably, law rarely requires detailed audit trail. As we definitely do not target banks, insurance companies and other highly specific sectors, the solution with full CRUD and no (extensive) audit trail is perfectly acceptable for the target group (small to medium companies and their accountants).
On the other hand, accounting domain does require some versioning let alone not exactly traditional. The reason is the relational model we use. Even though the documents data are self-sufficient, provides full details for a particular document. They do reference common model objects – persons’ and company’s profile. E.g., an invoice document model does not store full company’s profile data and persons (buyers) profile data, only reference the data in the common infrastructure tables. However, any document when printed or otherwise exported shall include the data that was relevant as of the date of the document. It could be achieved in two ways:
- By storing the common state in some serialized way within the document itself (snapshot) or
- By providing different common state versions for all the periods
The first method has problems with the real world use cases. E.g., an accountant issued an invoice for some company and later got to know that the company’s name was already different/changed at the invoice date. If he changes the relevant person data in the common model, the changes will not be reflected in the document of the interest as it holds old common state snapshot. Therefore, we will need to provide some method to reset the snapshot or to require an accountant to delete the document and then enter it anew. In both cases, the implementation is going to be non-intuitive or/and inconvenient, which is not good.
The second method perfectly meets the expectations of an accountant. If some data for some period is changed, an accountant can be sure that all the documents for the relevant period will catch up. Therefore, we’re going to use it. (For further discussion, see Best way to design a database and table to keep records of changes).
The versioning method required is non-traditional in a way that any of the versions can be modified by an accountant whenever required (when an accountant gets to know about some changes). Conceptual winforms GUI could look something like that (for visualization only, fields are not actually well distributed as explained further!!!):
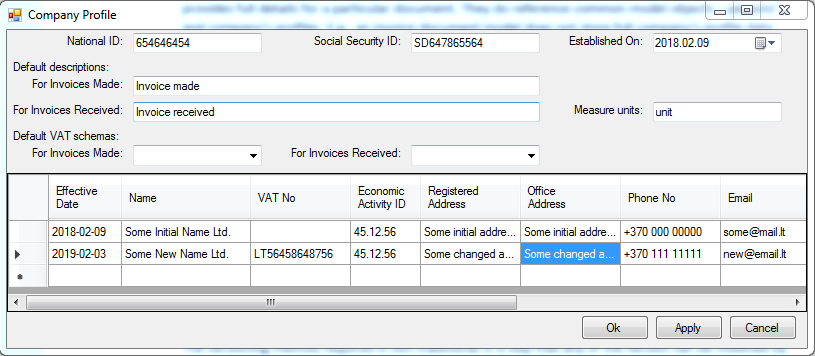
Actual version data will only be needed when a document is either printed or otherwise exported. So the business object implementing a document that requires versioning will require a method PrepareForPrint or similar to fetch (update) the versioned data. The SQL queries for that purpose will be as trivial as:
SELECT * FROM company_profile_versions v WHERE v. effective_date <= [document date]
ORDER BY v.effective_date DESC LIMIT 1.
Company profile version data could be cached, as the data amount will be small. Person profile version data is more problematic. Expected amount of persons could be as large as several dozen thousands. If you add three versions on average per person that could add up to quite a large memory footprint. Though, those implementation details are not particularly relevant at this development stage. For now, it’s enough to define that each company or person profile shall have a list of versioned data with effective dates specified.
Addresses
There are two issues about addresses that should be discussed:
How Do We Structure Address Fields?
You can find various address structurizations on web. Most of them are country specific, e.g., US postal office defines those address fields: Street Number, Predirectional, Street Name, Street Suffix, Postdirectional, Secondary Unit Indicator, Secondary Number, PO Box Number, City, State, ZIP Code, ZIP+4 Code. Using a country specific address structurization for an accounting application is not a particularly good idea, as a significant part of the companies have vendors and clients in foreign countries, which have their own addressing schema. There are no international standards for address structure. In such cases, it’s not a bad idea to rely on the guys who have the largest dataset to test the ideas on, i.e., Google. Google for Android uses those address fields: label, street, PO Box, neighbourhood, city, region, postcode and country. Definitely, it looks better than trying to fit US address schema for Lithuania.
However, our data hunger shall not outshine the expectations of our users – accountants. An accountant will be unable and unwilling to structure addresses in foreign countries (try for yourself to structure address like this: “ 65 moo.7 T. Ao-nang, Muang, Krabi (Phi Phi Don), 81210 Phi Phi Don, Thailand ”). Therefore, we cannot impose a burden of address structuring on an accountant. It could only exist as an option for addresses within the application home country. To sum it all up, we shall provide only optional address structurization and only specific to the home country of the application. In my case – Lithuania. Which brings us to the requirement to have a field for unstructured address, a country and a few optional country specific fields (in my case – for Lithuania): municipality, city, street and house number. One more thing, that could enchase analytics these days, is geo coordinates. It’s easy to plug into gmaps and let an accountant validate unstructured address as well as pick the address from a map. Therefore, why not add two decimal fields for longitude and latitude.
Keep in mind that we are doing the address structurization not out of having nothing else to do. The value of structured addresses is analytics. We definitely won’t do any analytics with the company’s self-addresses. Therefore, fields for unstructured addresses will be sufficient for the company’s profile.
How Many Addresses per Person Are Required?
There are two types of addresses of an accountant’s interest – billing address and shipping address. Actually, the latter is often handled by CRM, warehouse or billing applications and not so often of interest for an accounting.
The billing address is the one that is displayed on an invoice next to the client’s name. It can change, but it happens rarely. As we discussed in the section about versioning, it can be conveniently handled by the versions of a person profile. If the billing address changes at some moment, it shall and will affect the invoices, which dates are later than the change. E.g., if an accountant issued an invoice and then noticed that the billing address has changed, he can update person’s profile version and that will also update the invoice billing address, which is exactly what an accountant expects. The billing address is a legal field and might have some tax related implications. However, nothing really happens at the billing address. Therefore, its change in case of a mistake will still be reconcilable with the real world facts.
The shipping address is the one where some goods or equipment are actually shipped. It only has meaning if something is physically shipped. It also describes a real world fact, i.e., it’s not just a legal field like the billing address. Therefore, it is always a part of an invoice factual description and consequently is stored within the invoice schema (for further discussion, see Storing a Shipping Address Best Practice ). Of course, it is convenient for an accountant to be able to pick a shipping address from a lookup instead of entering it manually for each invoice. However, the lookup values (addresses) in this case are only defaults. Once an invoice is saved, the value is copied to the invoice because it becomes a real world fact (while you cannot change real world facts by changing a profile). Therefore, shipping addresses do not require versioning.
A company by itself (as a legal entity) always has only one billing address. As changing fact that is required to be presented in multiple languages, it belongs to a version of company’s regional profile.
A company by itself could have multiple shipping addresses, i.e., it can ship goods from various locations. However, this concept is closely related to the warehouse concept for inventory operations. Therefore, we will deal with it in some later article about inventory operations.
Company Profile
To summarize the requirements for localization and versioning, we will need a total of four tables (entities) for company and person profiles:
company_regional_profiles – to store localized company data that does not require versioning, e.g., default values that are only used to prefill document fields with default values. The table will contain one row per language (at least one row for the base language).company_regional_profile_versions – to store localized company data that does require versioning, e.g. company addresscompany_profile – to store company data that does not require either localization or versioning, e.g., default values that are only used to prefill document fields with default values. The table will always contain only one row. (P.S. national ID as non-versioned field was a bad example, it can change although very rarely)company_profile_versions – to store company data that does not require localization but does require versioning, e.g., company name, email, phone no, CEO name, etc.
We will also need two more helper entities (tables) that logically belong to the company profile:
default_accounts – As discussed in the previous article, some business functionality, e.g., balance sheet presentation requires knowledge about some (default) company accounts that the company uses for specific purposes, e.g., retained revenues account. The list of such default accounts depends heavily on the business layer implementation and is likely to change. Therefore, it’s not a good idea to provide a separate field for each default account type. Besides, we also have to support the application extensions, which are likely to require their own default accounts. For these reasons, the default account types are defined as an enumeration with an extension point like we previously did for (source) document types. As I didn’t foresee the requirement for default account type extensibility in the first article in the series, we will implement it now.company_regional_templates – one of the localization objects is a template that the company uses for its “external” documents, e.g., an invoice template. Specific template format depends on the reporting engine the application uses. However, it is not of importance from the database point of view, as a template is always a file, i.e., BLOB. The extra table requirement is due to the data type and for extensibility. The BLOB fields for templates could be added to the company_regional_profile_versions table, but such approach would complicate the database. First of all, templates do not change as frequently as other localizable data. Whenever we add a new version of localizable data, we duplicate the fields that do not actually change. It’s ok for small fields taking into account that there won’t be many entries in company_regional_profile_versions table. But the templates can be as large as 100 – 500 kB each. We definitely do not want to duplicate that much data when the company’s address got changed. Another reason to use a separate table is extensibility. It’s likely that some application extension could have its own documents that are meant for external users, e.g., a specific kind of invoice, and therefore require localization. As I didn’t foresee the requirement for template type extensibility in the first article in the series, we will also implement it now.
Now we can summarize all of the requirements and my personal experience about the commonly used profile fields with the following company profile schemas (relevant portions per profile type):

Table company_profile Details
| Fields
| Description
|
base_country | An ISO 3166 code of the country that the company is a resident for. Should not be changed after the company is created because companies cannot move to another jurisdiction by themselves. It’s a foreign key for the country_codes table and restricts updates and deletes of this country code. Actually, the restriction is the main purpose of this field, as it’s not very feasible that an accounting application could support many jurisdictions without major impact on usability. If a particular RDBMS does not support tables without primary keys, the field could also be used as a primary key. |
base_currency | An ISO 4217 code of the base currency that is used for accounting. Should not be changed after the company is created because this kind of change brings us to the situation when there are two base currencies within a single database. Which is extremely difficult to calculate and support. The recommended method on such a rare occasions (e.g., introducing EUR) is to create a new company database and only move converted balances. While the old database is left for historic reference. It’s a foreign key for the currency_codes table and restricts updates and deletes of this currency code. |
base_language | An ISO 639-2 code for the base language that is used in the accounting. Should not be changed after the company is created because that wouldn’t translate the old textual data by itself. The recommended method on such a rare occasions (I cannot even imagine such) is to create a new company database and only move balances. While the old database is left for historic reference. |
establishment_date | A date that the company was established on. Obviously, cannot change (unless a typo). |
default_description_invoice_made, default_description_invoice_received | A default descriptions of an invoice. The descriptions are only used to autofill the description field (as defaults), which is only for internal use. Therefore, its change has no impact for any old invoices. The reason why they are used instead of a separate table with default descriptions per document type is that in real life use cases, they are the only ones that do not require customized description (at least in my experience supporting an accounting application). |
default_measure_unit_invoice_received | A default measure unit in an invoice received. It is only used to autofill the measure unit field (as a default), which is only for internal use. Therefore, its change has no impact for any old invoices. |
default_sales_vat_schema_id, default_purchases_vat_schema_id | Default VAT schemas applied for new invoices. They are only applied as defaults. Therefore, their change has no impact for any old invoices. The VAT schemas will be discussed in the future articles in the series. For now, those are just reference fields for future use. |
inserted_at, inserted_by, updated_at, updated_by | Standard audit trail fields as described in the first article in this series . Obviously, the company profile is a root entity. |
Table company_profile_versions Details
| Fields
| Description
|
id | A synthetic key. I prefer to use it for consistency. Though, in this case, field effective_date is also a great candidate as primary key. |
effective_date | A date that the profile data is effective from. |
national_id_no, social_security_no, vat_no | Codes that identify the company within state registries. Could be jurisdiction specific, but in most jurisdiction should be pretty much the same. If you think that they cannot change, think again. National registry reforms happen. Not to mention that a company could be (de)registered as VAT payer multiple times. Obviously, the codes are not localizable. |
company_name | An official name of the company. Obviously, can change. Not localizable. |
ceo_name, accountants_name | Names of the CEO and accountant. Obviously, can change. Not localizable. |
vat_deduction_percentage | Applicable VAT deduction percent. Will be discussed in detail in the future articles. For now, just a field reserved for future use. |
ceo_signature_facsimile, accountants_signature_facsimile | In some jurisdictions, invoices could be “signed” with a CEO’s signature facsimile (scanned signature). Not applicable for Lithuania anymore and, as far as I’m concerned, the rest of the EU. If it’s applicable for your jurisdiction, it’s a good place for the fields. Even though they are of BLOB type, their size is small by definition (1-5 kB). Therefore, no significant impact for duplication. |
Table extended_default_account_types is implemented using the same method as the other type extensions (see the first article of the series for details). The only substantial difference is the absence of fallback type. In this case, the extended default account type has no meaning without the extension itself. Therefore, if the extension is uninstalled, the default account types owned by the extension can be safely dropped. Table fields:
| Fields
| Description
|
id | A GUID of the extended type that is assigned (generated) by the extension developer. |
extension_id | An ID of the extension that the extended operation type belongs to (foreign key to table extensions) |
type_name | A name (short description) of the extended default account type – for the (obvious) data debugging purposes. |
Table default_accounts Details
| Fields
| Description
|
id | A standard synthetic key. A combination of default_account_type and extended_default_account_type_id could also be used as a clustered primary key. However, the extended_default_account_type_id field could be null (if it’s not defined by an extension). Which might cause problems in some RDBMS. Therefore, I opt for standard synthetic key. |
default_account_type | An application defined enumeration of the default account types that a handled by the base application functionality. It might change. Therefore, ENUM type cannot be used. For the data integrity purpose (to prevent illegal/non-existent types), a technical lookup table might be used. But I am undecided about it yet. |
extended_default_account_type_id | A default account type defined by an extension of the application (if the default account type belongs to an application extension). It’s a foreign key for the extended_default_account_types table with ON DELETE CASCADE option. So that the entry is automatically deleted if the extension is uninstalled. |
account_id | An account that is set as the default of the particular type. It’s a foreign key for the accounts table with ON DELETE CASCADE option. So that the entry is automatically deleted if the account is deleted. |
Now we can summarize all of the requirements and my personal experience about the commonly used localizable profile fields with the following company regional profile schemas (relevant portion):
Table company_regional_profiles Details
| Fields
| Description
|
id | An ISO 639-2 code for the language that the regional profile is for. There should be at least one regional profile for the base language of the company. |
default_extra_info_in_invoice | A default region specific text that is added to invoices. The text is only used to autofill a localized document/invoice comments field (as a default value). Therefore, its change has no impact for any old invoices. |
default_invoice_measure_units | A default measure unit in an invoice made. It is only used to autofill the localized measure unit field as a default value. Therefore, its change has no impact for any old invoices. |
inserted_at, inserted_by, updated_at, updated_by | Standard audit trail fields as described in the first article in this series. Obviously, the company regional profile for a particular language is a root entity. |
Table company_regional_profile_versions Details
| Fields
| Description
|
id | A standard synthetic key. I prefer to use it for consistency. Though, in this case, fields effective_date and regional_profile_id could also be used as a clustered primary key. |
regional_profile_id | An id of the regional profile that the version entry belongs to. |
effective_date | A date that the profile data is effective from. |
registered_address, office_address | A registered and actual address of the company. The registered address is an official address within the relevant companies’ registry. It is common that actual address is different from the official. |
phone_no, email, contact_details | Contact details that are used in the documents for a specific language. Even though phone number and email are not localizable by nature (cannot be translated), it’s common to display different contact details for different languages. There are employees behind those contacts and not every employee may speak the relevant language. |
ceo_title | A title of the CEO, e.g., director, president, chairman, CEO, etc. |
Table extended_regional_template_types is implemented using the same method as the other type extensions (see the first article of the series for details). The only substantial difference is the absence of fallback type. In this case, the extended template type has no meaning without the extension itself. Therefore, if the extension is uninstalled, its templates can be safely dropped. Table fields:
| Fields
| Description
|
id | A GUID of the extended type that is assigned (generated) by the extension developer. |
extension_id | An ID of the extension that the extended template type belongs to (foreign key to table extensions) |
type_name | A name (short description) of the extended template type – for the (obvious) data debugging purposes. |
Table company_regional_templates Details
| Fields
| Description
|
id | A standard synthetic key. A combination of regional_profile_id, effective_date, regional_template_type and extended_regional_template_type_id could also be used as a clustered primary key. However, such a large clustered index doesn’t look very appealing. Therefore, I opt for standard synthetic key. |
regional_profile_id | An id of the regional profile that the template version entry belongs to. |
effective_date | A date that the template is effective from. |
regional_template_type | An application defined enumeration of the template types that a handled by the base application functionality. It might change. Therefore, ENUM type cannot be used. For the data integrity purpose (to prevent illegal/non-existent types), a technical lookup table might be used. But I am undecided about it yet. |
extended_regional_template_type_id | A template type defined by an extension of the application. (if the template type belongs to an application extension) It’s a foreign key for the extended_regional_template_types table with ON DELETE CASCADE option. So that the entry is automatically deleted if the extension is uninstalled. |
template_body | A template file. |
Now that we have full company profile schema in place, we can define a sequence of actions required to initialize a new database for a company:
- Add entries for the relevant extensions as described in the first article in the series
- Add entry to the table
country_codes for the base state of the company - Add entry to the table
currency_codes for the base currency of the company - Add entry to the table
company_profile for the non-localized company profile - Add entry to the table
company_profile_versions for the non-localized company profile initial data version - Add entry to the table
company_regional_profiles for the localized company profile in base language - Add entry to the table
company_regional_profile_versions for the localized company profile in base language initial data version
That’s a minimal required initialization. Of course, you should also consider using extra wizard for some typical financial statements and chart of accounts setup.
Person Profiles
To summarize the requirements for localization, versioning and addresses we will need a total of three tables (entities) for person profiles:
person_profiles – to store person data that does not require versioning, e.g., default values that are only used to prefill document fieldsperson_profile_versions – to store person data that does require versioning, e.g., person name, address, etc.shipping_addresses - to store shipping addreses for a person
We will also need two more helper entities (tables) that logically belongs to the person profile: person_groups and person_group_assignments. The requirement is determined by typical use cases – sometimes accountants need to group persons by some common business specific criteria. Person groups are trivial entities – just a name (to display in a lookup controls) and a description. One person could be assigned to multiple groups and vice versa. Hence, we also need a standard many-to-many relationship table – person_group_assignments. As those tables are trivial, no further details are needed.
Now we can summarize all of the requirements and my personal experience about the commonly used localizable profile fields with the following company regional profile schemas (relevant portion):
Table person_profiles Details
| Fields
| Description
|
id | A standard synthetic primary key. A person doesn’t have any field or even a combination of fields that could be used as a natural key. |
default_currency_id | An ISO 4217 code of the currency to use as a default when invoicing the person. As a default value, it could be changed without any effect for old invoices. It’s a nullable foreign key for table currency_codes with option ON DELETE SET NULL, because the null value can be safely treated as company’s base currency while there is no reason to block currency delete only because it’s assigned as a default for a person. (as long as the currency was not used in a document) |
default_regional_profile_id | An id of the company’s regional profile (language) to use as a default when creating some localizable documents for person (e.g., invoice). As a default value, it could be changed without any effect for the old documents. It’s a nullable foreign key for table company_regional_profiles with option ON DELETE SET NULL, because the null value can be safely treated as company’s base language profile while there is no reason to block regional profile delete only because it’s assigned as a default for a person (as long as the regional profile was not used in a document). |
default_accounts_receivable_id, default_accounts_payable_id | Default accounts to use in documents for the person. As a default value, it could be changed without any effect for the old documents. It’s a nullable foreign key for table accounts with option ON DELETE SET NULL, because the values are optional while there are no reasons to block account delete only because it’s assigned as a default for a person (as long as the account was not used in a document). |
date_of_birth | A date of birth of a natural person (if the person is a natural person and chose to use date of birth instead of other ids). Obviously, cannot change (unless a typo). |
contact_details, comments | The fields are only for internal use by an accountant. No benefits in keeping their versions. |
is_client, is_natural_person, is_employee, is_supplier | Most common person categories. Typically used to filter lookup lists. |
is_archived | A standard field for marking a person as no longer in active use as described in the first article in this series . |
inserted_at, inserted_by, updated_at, updated_by | Standard audit trail fields as described in the first article in this series. Obviously, the person profile is a root entity. |
Table person_profile_versions Details
| Fields
| Description
|
id | A synthetic key. I prefer to use it for consistency. Though, in this case, fields effective_date and person_id could also be used as a clustered primary key. |
person_id | An id of the person (profile) that the data version is for |
effective_date | A date that the profile data is effective from |
person_name | A name of the person. Obviously, can change. |
address, municipality, city, street, house_number, longitude, latitude | An address of the person (unstructured and, optionally, structured). Obviously, can change. |
country_id | A state of the person residence. Not so obvious, but still can change. E.g., if a company becomes a state resident for tax purposes it is considered a state resident even if it has no subsidiaries in that country. |
national_id_no, vat_no, social_security_no, business_certificate_no, individual_activity_certificate_no | Codes that identify the person (company) within state registries. Could be jurisdiction specific, but in most jurisdiction should be pretty much the same. If you think that they cannot change, think again. National registry reforms happen. Not to mention that a company could be (de)registered as VAT payer multiple times. Obviously, the codes are not localizable. |
internal_id | An id of the person that the company uses internally, e.g., some customer id. It is typically displayed on invoices. Therefore, subject to versioning. |
bank_account_no, bank_name | A bank account of the person. Obviously, can change. Could also be implemented as a separate table for person’s bank accounts to support multiple bank accounts per person. However, never been asked for such a functionality by any accountant and prefer to keep it as simple as possible. |
email | An email of the person. It could be displayed on invoices. Therefore, subject to versioning (though, in this case it’s questionable). |
The last table within person profile infrastructure shipping_addressesis trivial – just an unstructured and, optionally, structured address plus standard bit flag is_archived. The latter might seem redundant, as the shipping address shall be cloned to the invoice. I only leave it as a means for an accountant to temporary hide it in lookup controls.
Once we have the person profile schema in place, we can fetch the effectual profile fields with a query:
SELECT p.id, p.default_currency_id, p.default_regional_profile_id, _
p.default_accounts_receivable_id,
p.default_accounts_payable_id, p.date_of_birth, p.contact_details, p.comments, p.is_client,
p.is_supplier, p.is_natural_person, p.is_employee, p.is_archived,
v.person_name, v.address, v.state_of_residence_id, v.national_id_no, v.vat_no, _
v.social_security_no,
v.business_certificate_no, v.individual_activity_certificate_no, v.internal_id,
v.bank_account_no, v.bank_name, v.email
FROM person_profiles p
LEFT JOIN person_profile_versions v ON v.person_profile_id = p.id AND v.effective_date =
(SELECT MAX(q.effective_date) FROM person_profile_versions q WHERE q.person_profile_id=p.id)
Cost Centres
A cost centre is typically defined as a department within a business to which costs can be allocated. It’s a part of management accounting. (See wiki) We will implement cost centre in a bit more generic and simple way – as an extra dimension for analytics that is not strictly related namely to costs. Simply define a loose set of simple cost centre entities with an option of grouping that could be assigned to documents and ledger entries and consequently enables filtering of reports. Such a straightforward implementation will allow an accountant to use it not only as a classical cost centre but also as a project tracker or budgeting line.
The schema for cost centres is trivial and hardly requires any further comments:
Binding Persons and Cost Centres to Documents
As it was already discussed in the second article in the series, the first point to add the persons and costs centres at is the general ledger. We have already left two fields for that purpose. So now, the full schema looks like that (the relevant portion):
However, that’s not the only point where the foreign keys to the person and cost centre should be added. Again, as discussed in the second article, not every document has a general ledger transaction (e.g., time sheet or a labour contract do not). Moreover, some documents might have both persons related an unrelated through a general ledger entry (e.g., an invoice with a guarantee). Therefore, we shall also add a foreign key reference at the document level. Even though the related persons might overlap (and in most case will overlap), it doesn’t break normalization as the reference has a different context. The link to a document is definitely a broader concept than a link to a ledger entry. On the other hand, we cannot streamline relation to a document to a relation to a particular ledger entry. Which brings us to conclusion that both references are required by the business logic of the domain.
Obviously, a (source) document might have both multiple persons and cost centres related. Which brings us to requirement of standard many-to-many tables. Therefore, the final schema for document to persons and costs centres relations looks like that (a relevant portion):
It should also be noted that the application that will make use of the schema shall not ignore the persons and costs centres that has already been assigned to ledger entries. Those shall also fall into the document relations. Otherwise, a trivial select filtered by a person (or a costs centre) would also hit the “heavy” ledger entries table. This is only the most pragmatic reason. There are also a theoretic one. As described above, the relation document-person is different from the relation ledger entry – person as per domain business logic. Therefore, the relation to a person by a ledger entry and a document have a different business meaning per domain and both of them shall be kept in order to correctly describe both aspects. The convention (as you cannot guarantee it at the database level) also has benefits for the extensions. As every extended document shall use the document infrastructure, all of the documents (both for base functionality and extended) will be available by a single “interface”, i.e., we can have a single filterable registry for all of the documents.
Common Document Numeration Schema
The last but not the least handy thing to implement in the common documents interface is the numeration schema. The documents that an accountant receives have numbers that they have. Meaning, the accountant just records a fact. However, the company itself issues some documents. And, at least for small companies, those are issued using the accounting software, i.e. our application. Therefore, the application should be able to handle the numeration of such documents. It might be culture specific, but as far as I’m concerned, the ways the document numbers are generated are:
- There is some document serial, that consists mostly of some letters, sometimes other characters and numbers; might also be an empty string;
- There is a base (running) number (integer) that is reset subject to the company policy: never, once a year, once a month or every day.
- There is a formatted full document number that consists of: a serial (as a prefix), a date of the document (or part of the date, e.g., year only, or the date might be disregarded at all) and the base number.
To sum it all up, the document number template using .NET format string (only for demonstration, any other could be used instead) could be described by the fields:
- Serial – pretty much any string provided by the user; for sanity check, presumably max 20 characters;
- A numbering policy enumeration, i.e., reset running number: never, once a year, once a month or every day;
- A full number format string, e.g. “{0:yyyyMMdd}-{1:D6}” which for a document at 2019-12-31 with running number 1 would produce “20191231-000001”, or “{1}”, which for the same document would produce “1” (serial always goes as prefix, no need to include in the format string).
- A bit flag indicating that the full number is provided by an external system, i.e. whether the full number shall be “calculated” using running number and format string or a user (e.g., a CRM) should be allowed to enter the full number manually.
If you know of a real life use case that wouldn’t fit the template, please let me know.
Obviously, a change in template (company’s numbering policy for some type of document) cannot affect numbers of the documents that has already been issued. Which brings us to the following options:
- Make the template read-only if it has been used by a document
- Copy template fields to the (complex) document number fields
- Anything in between the previous solutions
Actually, I don’t see any serious cons for all of the options. My choice is based on the way most accountants see/understand the document-numbering concept. And they tend to associate the numbering schema with the serial part, i.e., when they choose a serial from a lookup accountants (most of them) expect a valid (next) number to be assigned to the document. And otherwise, accountants are not used to a field “numbering policy” as well as seeing multiple “numbering policies” with the same serial, which makes it non-intuitive. To make the numbering function as intuitive as I can, I chose the following mixed solution:
- The serial part of a template is unique per document type and identifies the template (at least from the accountant’s point of view).
- The serial part of a template is made read-only the moment a document uses the template.
- The rest of the template fields remain editable but their values are copied to the document, i.e., change does not affect previous documents.
There are two ways to implement this solution: plainly copy numbering policy, external system flag and format string to the document or keep a separate “numbering policy versions” table that holds the same fields and gets a new row whenever a policy changes. The first option will cost extra ~60 MB for one million document database. The second option will save the space and (maybe?) will be more normalized but somehow more complex. As the disk space costs are quite negligible, I opt for the more simple solution – three field copy. The resulting schema will be the following (the relevant portion):
Details for the table complex_numbers
| Fields
| Description
|
document_id | An id of the document that the number is of. As we have 0..1 relation here, it’s both a primary key and a foreign key. |
template_id | An id of the template that defines the numbering rules. |
reset_policy | A numbering policy, i.e., periods when the running number shall be reset. Copied from template. |
format_string | A format string used to produce a full number by the document date and running number. Copied from template. |
has_external_provider | A bit flag indicating that the full number is created and formatted by a third party (e.g. a CRM), i.e., format_string and running_no shall not be used. Copied from template. |
running_no | A running (sequence) number of the document within the reset period. |
full_no | A full (formatted) number of the document. |
Details for the table complex_number_templates
| Fields
| Description
|
id | An id of the complex number template. A standard surrogate primary key |
document_type | A base (source) document type that the template is meant for. |
extended_document_type_id | An extended (source) document type that the template is meant for. |
serial | A serial of a document, i.e. an arbitrary string (including an empty one) to prefix the full number of a document. Should be unique per document_type and extended_document_type_id. Shall not be changes after the template is used for a document. |
reset_policy | A numbering policy, i.e., periods when the running number shall be reset. |
format_string | A format string used to produce a full number by the document date and running number. |
has_external_provider | A bit flag indicating that the full number is created and formatted by a third party (e.g., a CRM), i.e. format_string shall not be used. |
is_archived | A standard bit flag indicating that the template is no longer in use and is kept only as a historical record. (as the template used in a document cannot be deleted) |
comments | Accountant’s comments regarding the template. For internal use only. |
inserted_at, inserted_by, updated_at, updated_by | Standard audit trail fields as described in the first article in this series . Obviously, the complex number template is a root entity. |
Having the schema in place, we can now fetch a next number for an arbitrary complex number schema with an id=123 and a document dated 2019-05-26 in a generic way:
SELECT MAX(c.running_no) + 1 AS NextRunningNo
FROM documents d
LEFT JOIN complex_numbers c ON c.document_id = d.id
WHERE c.template_id = 123 AND (c.reset_policy = 'never' OR
(c.reset_policy = 'day' AND d.document_date = '2019-05-26')
OR
(c.reset_policy = 'month' AND YEAR(d.document_date) = YEAR('2019-05-26')
AND MONTH(d.document_date) = MONTH('2019-05-26'))
OR
(c.reset_policy = 'quarter' AND YEAR(d.document_date) = YEAR('2019-05-26')
AND QUARTER(d.document_date) = QUARTER('2019-05-26'))
OR
(c.reset_policy = 'halfyear' AND YEAR(d.document_date) = YEAR('2019-05-26')
AND ((MONTH(d.document_date) < 7 AND MONTH('2019-05-26') < 7) OR
(MONTH(d.document_date) > 6 AND MONTH('2019-05-26') > 6)))
OR
(c.reset_policy = 'year' AND YEAR(d.document_date) = YEAR('2019-05-26')));
Conclusion
In this article, we have finished developing database schema for the core accounting infrastructure: company profile, person profiles, generic document numbering policy.
Future articles will be dedicated to concrete types of (source) documents and accounting operations. At the moment, I haven’t made up my mind where to start from.
History
- 18th August, 2019: Initial version

