 In the highly complex and interconnected contemporary world, computers and humans interact continuously. We need a modelling approach which can shed light on the similarities between different players of this interaction rather than sub-divide this interconnected world into artificially specialist domains.
In the highly complex and interconnected contemporary world, computers and humans interact continuously. We need a modelling approach which can shed light on the similarities between different players of this interaction rather than sub-divide this interconnected world into artificially specialist domains.
Cybernetics: The science of communication and automatic control systems in both machines and living things.
New Oxford Dictionary Of English
If I were to lose my legs, my work would be much less impacted than if I lost my computer (ignoring the relative ease of replacing either). The complex interactions we all (in the rich world) now have with computers leads me to state that the study of most computer systems is now in the realm of cybernetics.
This observation leads to another, more startling one: even the very simplest of computer programs must be modeled in the context of a complex system. That system not only being the program but the use to which the program is put and the way in which other programs and humans interact with it.
This complexity can seem overwhelming when handled with the classical analytic tools of mathematics and computer science. We are still deeply embedded in an approach based on state equilibrium with an eye to that which is deterministically provable. In contrast, once computers start to interact with the 'outside world', the a-priory nature of their programs is contaminated by the messy, unpredictability of every day life. As a consequence, one might feel that modelling such systems is futile.
All is not lost! We can take a step back and ask ourselves what we really want to illuminate with our models and what the end result of our modelling should be. By so doing it might be (and I believe it is) possible to find a totally different approach which behaves more unmanageably when faced with this complexity. I shall now indulge in some simple linguistics to try and dig out what we as humans generally want from our model:
- "When I press this key, I want the computer to just do the right thing."
- "Pressing the break pedal should cause the breaks to engage."
- "The wheel lock sensor detecting a potential skid should activate the ABS system."
- "It should let me know when it has finished."
- "The spinning hour glass tells us that it is still working."
What we can see in each of these are events. We want the cybernetic system to respond to an event and we detect what has been done through our own sensory experience of events. We can even see this in terms of the last "hour glass" example: the glass turns to inform us that a different event (the program crashing) has not occurred. We are supremely uninterested that the program is working; we are only interested in events which mark it as having finishing or having crashed.
Let us consider these ideas in a different way. We are often taught, and the concept permeates our conversational culture, that the physical world tends to equilibrium. This notion is embodied in the natural sciences with such core teaching as Le Chatelier's Principle. In general, we are urged to seek to understand the equilibrium state to which a system "wants" to move. Indeed, we imbue systems with a teleos of stability seeking. However, we see no equilibria in natural systems. Only by extreme artificial methods can we impose equilibrium for the briefest of time. Organisms are created, age and die. Coast lines grow in one area whilst eroding in another. Even the orbit of our planet shifts on a minute by minute bases whilst its rotation gradually diminishes. We humans are not actually interested in basins of temporally delimited pseudo-equilibria; we are interested in points of measurable change; we seek the point of boundary crossing; We view the physical world as the consequence of events which change it not the other way around.
Given all of these observations, we can now start to view all of cybernetics with light of events. Where once we might have used many disparate concepts to illuminate the field, we can now use one and by so doing, unify our view.
Before I go much further discussing the details of this approach, I must define what I call the 'irreducible anatomy' of the event model I am proposing. This being the structure of the model expressed in such a way that any attempt to further reduce its complexity simply rearranges its complements or alter their names. In other words, more complexity would be excessive and less would be insufficient whilst any alternative anatomy might be equally valid but ultimately will prove to be topologically equivalent (as, for example, a tea cup is to a torus).
The Irreducible Anatomy of an Event Based Model
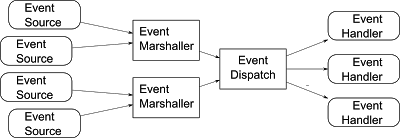
A diagrammatic representation of the irreducible anatomy of an event based model.
-
Event sources are entities which instigate the marshalling of Event Objects.
An event source could be a hardware related activity (e.g. a key press) or some purely software related thing like a memory state change.
-
Marshalling is the gathering together of a full description of what the event was and conversion of this description into a usable form. The abstract notion of this usable form we can call an Event Object; note that this does not imply the used an Object Oriented language; I am simply using the word object to represent a transferable contained amalgamation of function, data and information.
Also note that gathering and conversion can actually occur in either order or simultaneously or any intermediate of these possibilities.
-
Event dispatch is a system which forwards event objects to event handlers based on some rule set.
In theory, all event handlers could handle all events (no routing on the part of dispatch); however, this would simply result in the role of event dispatch being distributed across all the handlers because in such an architecture, the handlers would need to ignore some events based on rules. Distribution of the 'ignore' functionality over multiple handlers would then make the system less functionally normalized (see later) and so is not desirable.
-
Event handlers are entities which respond to events.
Event handlers should be in a functionally normal form, i.e., one should not have the same functionality represented in more than one event handler and the events of a given, unique type should only be dispatched to a single handler. If a publish/subscribe mechanism is to be used, it should be applied by the handlers publishing to some further architecture not at the level of event dispatch and handler. These normalization provisions are to avoid contamination of the event model with implementation detail and, in general, to reduce the complexity of the model to its irreducible form thus making it maximally tractable.
What is An Event?
The discussion so far describes the overall structure of the model whilst being very brief about what an event actually is. To go further with defining events, we must first understand the context in which we will define them. This context must be finite or else our model will explode with complexity, to this end, I will introduce the concept of Domain. The model domain contains all the aspects of a system which we wish to model but nothing else. Such an idea is flawed at its inception because nothing in the physical reality (as opposed to the a-priory, tautological realities) is completely separable from anything else. Nevertheless, the event modelling effort is motivated by a need for tractable models; creating artificial domain boundaries is a key tool for helping to achieve this tractability.
Given the enclosing notion of a modelling domain, we can now go about defining what events should be. The following list is sufficient but not item unique; in other words, the different requirements of the event do have overlapping meanings, but when taken together, are sufficient to fully describe what an event should be:
-
Information Domain Sufficient: They should contain sufficient information to fully describe their roles in the domain being modelled. No other data or information should be required. Specifically, if the notion of a 'context' for an event or a modelling of an event's raising entity's state is required, then the event handler has been contaminated with the event raiser/marshaller. Such contamination leads to a destruction of the pure event model and loss of its benefits.
-
Domain Atomic: Events should not rely on information from other events to be information sufficient. This can be seen as the corollary of being information domain sufficient.
-
Domain Unique: Within a given model domain, any event must be of a type which is totally unambiguous to all other possible events in that domain. If the meaning of an event can be confused with the meaning of an event of a different type due to ambiguous type resolution, then the events are not unique. As we cannot rely on context or state analysis to provide event disambiguation, all events must be self unique.
-
Data Domain Normal: The data contained in an event object must be sufficient to circumscribe the sufficient domain information and nothing else. Excessive information leads to excessive complexity. Similarly, data replication leads to excessing complexity for the same information content.
Also of interest, event handlers should be in functionally normal form, i.e., one should not have the same functionality represented in more than one event handler and the events should only be dispatched to a single handler. If a publish/subscribe mechanism is to be used, it should be applied by the handlers publishing; it should not be done at the level of the event dispatch and handlers. These normalisation provisions are to avoid contamination of the event model with implementational detail to reduce complexity in the model to and irreducible form thus makes it maximally tractable.
Model Transformation: Coping with the Real World
So far, we have considered event based modelling solely from the view point of a perfect world. Conceptually, computer science can occupy a perfect world. A Turing machine of infinite speed and limitless tape can be programmed to perform any formally computable operation. Once we make the step into cybernetics, we must live with finites and inaccuracies. We move from a-priory mathematical tautology to a-posteriori hardware. By way of concrete example: we cannot realistically redesign the human heart to allow it to raise events; we must monitor it and then raise events based on changes in detected state. Equally, we are unlikely to have the resource or even the legal right to reconstruct the Windows kernel such that it will raise events for all status changes in which a sophisticated monitor may be interested; again we must fall back to monitoring via polling and additionally merging in of some raised events which are available to us. Other systems may raise events contain inappropriate information or are in a different domain to our model.
From this, we can see that to create a pure event model in real world cybernetics we must employ transformation from the observable space to the pure event space (by analogy to the transformation from time to phase space which is so vital to the analysis of chaos).
Event Transformation: Merging And Splitting
Whilst we can now realise the need for transformation, we should not lose sight of the benefits of event based modelling. Thus I propose here an event based view of how we may perform the required transformation and from that, some (hopefully) useful hints as to how we can implement such transformations in software. To ground this work, I shall use analysis of real world situations (or their semi-fictional analogues) to flush out the concepts required.
Let us consider first a uni-directional event model in which we wish to understand the load on a compute and how it relates to user interaction. In this scenario, we see two even raising sub-systems (human and computer) but all events are in the same direction (computer/human to monitor). After that, I would like to investigate modelling full bi-directional human to computer interaction via a scenario based on a fictional database management script. The second example is a member of an interesting set of challenges in which cybernetic systems have been created based on a state model where the human navigates though cyber-states via a set of questions and answers. Such systems are particularly complex to model using non event based techniques because of the bi-directional communications and the consequent two separate stateful sub-systems navigating their way around related by different cyclic directed state graphs. Other examples of this set of challenges are humans driving cars or auto-pilots flying aeroplanes.
Merging And Splitting As Applied To Polling Based Monitoring
Step 1: What are we interested in (define the domain)?
Step 2: What events are available to us?
Step 3: How can we transform this to match our domain?
We are interested in the changes of state of processes on the computer and any temporal relationship between their distribution and those of events from human interaction. An initial guess at the events in which we may be interested are:
- Disk access going above 1 megabyte per second
- Disk access going below 1 megabyte per second
- CPU consumption raising to greater than 90% for greater than 10 seconds
- CPU consumption dropping below 90% in the last 10 seconds
- Human launching an application
- Human shutting down an application
- Human requesting file delete from a file manager
- Human requesting file move from a file manager
- Human requesting an application to open file
The first thing to note is that the events raised from the computer sub-system are transitions whilst those from the human sub-system are simple actions. This can be thought of as a consequence of the human interactions having already been transformed into events before we are aware of them in our observations (we are not seeing the internal workings of the human's brain); conversely we are converting the state of the computer sub-system into state change events. We will see later that these two can be seen as nodes and edges of a state graph respectively.
Next, we can start to work out how we might acquire the computer sub-system events. It is pretty certain that these events are not already raised or even raisable by the software in the operating system (OS) of the computer. I am going to make the assumption that we are going to have to poll some internal states within the OS kernel. Let us consider the criterion that the disk access has gone above 1 megabyte per second. If we have a conjecture that the OS stores the number of 8 kilobyte blocks it has written to disk in the last 100 milliseconds, then we have to use this information to create our events. How do we convert this state into events?
To do this, we must consider the domain and event model first and the state second. It is far too tempting to design a model from the sub-system upwards rather than from the domain downwards. So for a start, we need to convert the 'how many 8 kilobyte blocks in the last 100 milliseconds' into events. We do not have to try too hard, we can just create a 'the state is this' event every 100 milliseconds; we can do so by simply polling the state of the kernel. The events thus created are in the wrong domain for our model and thus do not meet our criteria:
- Domain atomic: No, the set of these events contains repetitions of nodes (static state) and we are interested in edges (state change).
- Domain unique: Yes, they all have a simple type and that type is unique. They are all of 'disk I/O was' type.
- Data domain normal: We don't know yet - that is more implementational than we are discussing here.
- Information domain sufficient: No, they do not contain information on the change of state. Because they are not atomic they are inevitably information insufficient.
The solution to all these problems is to merge the events. We can create an event handler which also acts as an event raiser. It is impure in that it does store some state; however, it purifies the event model by discarding the need for state storage in the handlers of the events it raises its self. It stores the 19 previously raised polling events. If the first ten give an accumulated disk access of less than 1 megabytes and the second 9 plus the current event give an accumulated access of more than 1 megabyte, then an event of type one (above) is raised. If the opposite pattern is detected, then an event of type 2 is raised. These events do not store the actual amount of disk access (that would not be data domain normal) just that it has changed. We will also want to store in the event the time it changed because we have now put an appreciable delay between the event raising situation (notionally after the first 10 polling events) and the event actually being raised. Further, accumulation of timing errors is likely. Finally, time could prove important in the analysis of the human interaction events against OS events.
To illustrate the counterpart to event merging, we can now consider event splitting. If we were to find that the polling events actually contain a list of all the processes and their disk I/O, then we will need to do this very thing. Indeed, this is a very likely scenario, because without the events being created in this way, how would we be able to monitor newly created processes? An alternative would be to poll and create events which list all the running process and then poll for each process.
The approach is again centred on understanding the domain and basing everything on events. We can view the polling events as actually being a collection of events which have been merged. We simply split them into their separate events (one per process) and then pass these split events into the event handler for single process events which then does the state tracking and event merging. This splitting is again, done in an event handler which then raises events.
We have thus created a model which is entirely event based throughout and eventually emits fully compliant events into the final marshaller/dispatcher/handler model.
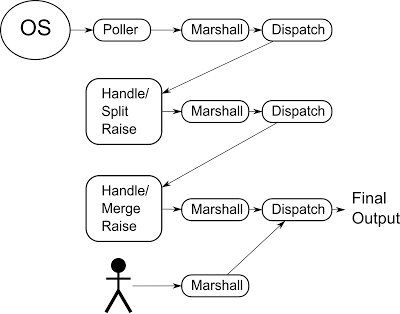
An overview of the final event model for our OS monitor using
merging and splitting.
I will not labour this example any further because I believe all its key issues have been covered. However, it still stands as a possible straw man to be pulled to pieces in later (not in this document) analysis.
Analysis of the Bi-directional Stateful System
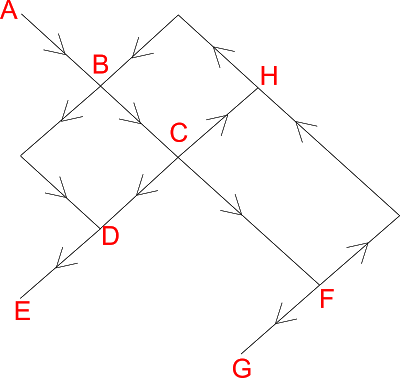
A visualization of a cyclic directed graph.
Given the success of splitting and merging in the previous example, one might ask if we can use the same techniques on the more complex second example. To do this, I will first bring into the open the idea of graphing to which I so far only eluded. The idea is that we can view the state of a cyber-sub-system as a cyclic directed graph. This is a formalization in that real physical systems cannot be viewed as fully deterministic; even if one assumes that there is no random element to physical reality, chaos shows that finite measurement error prevents fully deterministic modelling. However, the cyclic directed graph is a useful metaphor at the very least. We can use it in either one of two ways. Both assume that the graph is graphing state. Nodes are known states and edges show transitions from one state to another. The known states being resolved within the domain of the model. In other words, if the model is not concerned with a variable X in a program, the changes in X would not cause transitions between nodes.
If we are interested only in the instantaneous state, then we can raise events as the sub-system arrives at a node. If we are interested in the transitions between states, then we can raise events as the system passes along an edge. But: what are these events and what data information do they contain? To answer this question, we can go back to considering for what we are creating our model. The temptation is to create events based on our understanding of the event raising sub-system rather than (the correct) approach of considering the model and its domain.
By example: Let us consider a state change of a 4 digit unsigned integer. We can imagine an event of type 'IntVarChange' which holds data in which are 'previous-value' and 'current-value'. This event models that the state has changed but is type ambiguous as to the values of its data. Alternatively one could have one hundred million different types of event, each one unambiguously defining the previous and current value of the state change via type alone. Neither of these approaches is wrong. However, we can work out which is appropriate for our model:
- Will the event handler do something different depending on data values? This is a weak reason for having different types.
- Will the resultant model have an intractable number of different event types? This is a strong reason for not having different event types.
- Will different event handlers be used for different values. If the answer is yes, and the handlers are functionally normal, this is a strong reason for having different types.
Reality may be anywhere between these two extremes. I feel it is up to taste and skill to resolve the issue further.
Back to the Example
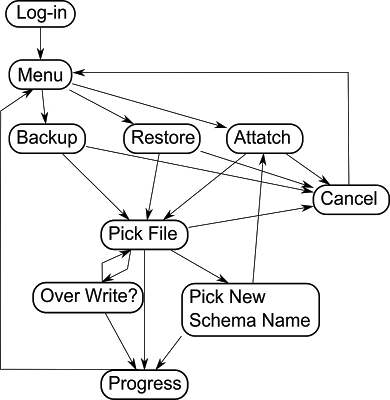
The cyclic directed graph of our notional example program.
Let us look once more at our database control script. We shall give it the above state graph. This is a simple example; however, the cyclic nature of the graph is apparent: Attaching a database file to a schema will alter the choices available for backup and restore and so on.
So, what questions should be ask to start the analysis process?
-
Are we interested in the nodes or the edges? The answer is nodes with the extra proviso that we may need to accumulate information all the way along the edge and store this in the event object. The script's questions act as points to raise events. We can define the questions as being complete when the script stops and waits for input. i.e. when it 'asks' the question.
-
What information do we want to be contained in the nodes? Can we make a general description – a set of guide lines – and apply this to each node? The answer is yes to the guide lines. We should include in the events information which is dynamic and meaningful, i.e., the information has meaning to the event handlers and which is able to change between instances of the event. Information which is static (unchanging across all possible instances of a given event type) should not be included in events but should in represented, if of meaning to the event handler, in the appropriate handler. If such static information does not seem appropriate in a given handler, then the chances are that the events or handlers are not properly normalised.
Event Chaining, The Bi-directional Model
Now we have some idea of how to convert the script sub-system's state graph into events, we should look at how to managed human interaction as events can how to understand the temporal relationship between the two. Whilst our model does convert a cyber-state graph into a set of separate events, it is not true to say that these events and be raised in any order. Whilst this may be fairly intuitive of the script's graph, it is possibly less so of the human graph. In theory, the human could raise any possible event at any time and in any order.
Our model's domain is that of the question and answer interaction between the script and the human. In this domain, human events only exist as responses to questions. This means there is a temporal relationship between an event raised by the human and that raised by the script. To understand what event a human legally can raise in the domain, we do not need to know the state of the script (that would break the pure event model approach). All we need to know is the last event raised by the script. Any given event from the script can only be followed by a sub-set of all possible events raisable from the human.
This approach works equally well in reverse. For any given event raised by the human (as long as unique typing is enforced), we can see that there is a sub set of events which the script can then raise.
So, a complex system of two independent cyber-sub-systems can actually be reduced to two sets of events (script and human raised) and single step temporal chaining relationship between the members of the two.
Splitting And Merging
If we were to wish to alter the human interaction without altering the underlying script will this model offer an approach or any guidance? This question takes us right back to the issue of the real world. In a perfect world, we could re-write the script to suit any changes we have in mind. However, in the real world, we may be unable to do so for several reasons (for example, it has been security cleared getting changes passed is prohibitively expensive).
To illustrate how merging might help in this regard, we can consider the work flow which includes the scripts states 'attach' → 'pick file' → 'pick new schema name'. Using our merging concepts, we should be able to merge 'pick file' and 'pick new schema name' into a single event raised by an intermediate between the script and the human. The human could then respond with a single event containing the file name and schema name. The temporal relationship is now between the intermediate raised merged event and the human response.
However, this idea is not quite as simple as the above paragraph suggests. The script is not in a position to respond to the single event from the user and it is not obvious how to merged then events because the 'pick new schema name' event cannot be raised until after the response to the 'pick file' event. However, all is not lost. The solution is:
- Raise an 'pick file and pick new schema name' event from the intermediate when the 'pick file' event is raised from the script.
- Let the human respond with the file and schema names.
- Split the human response and send the two events to the script, the first as a response to the already raised 'pick file' and the second to the 'pick new schema name' events.
- If the 'pick new schema name' event is not the next event to be raised by the script after the 'pick file' (maybe the file is not accessible and a cancel event is raised), then the second part of the split event is thrown away.
Such an approach does allow for exact modelling of the system and the design of ways to alter the system based on the event model. It also illuminates alterations which are not possible without changing the script. For example, if the 'pick new schema name' event contains a datum in it which is dependant on the response event to the 'pick file' event, then we simply cannot merge and split in the way suggested above. Thus, our modelling approach has successfully circumscribed what changes can and cannot readily be made to the human experience without altering the script.
Conclusions
It would appear that the approach works. There are limitations in its application, however, the model seems to be able to flush out what those limitations are. I have no doubt the approach requires further refinement, but I also have no doubt the effort will be rewarded.
Also posted at CodeProject

