This article has been presented at The Ninth International Conference on Simulated Evolution And Learning (SEAL 2012). I would like to post it here with my previous articles to everybody can more understand to my project.
Abstract.
This paper presents a library written by C# language for the online handwriting recognition system using UNIPEN-online handwritten training set. The recognition engine based on convolution neural networks and yields recognition rates to 99% to MNIST training set, 97% to UNIPEN’s digit training set (1a), 89% to a collection of 44022 capital letters and digits (1a,1b) and 89% to lower case letters (1c). These networks are combined to create a larger system which can recognize 62 English characters and digits. A proposed handwriting segmentation algorithm is carried out which can extract sentences, words and characters from handwritten text. The characters then are given as the input to the network.
Keywords: artificial intelligent, convolution, neural network, UNIPEN, pattern recognition.
Introduction
Originated in late 1950's, Artificial neural networks (ANN) did not gain much popularity until 1980s when a computer boom era. Today, ANNs are mostly used for solution of complex real world problems. This paper provides brief information of one very specific neural network (a convolutional neural network) built for one very specific purpose (to recognize handwritten digits and letters). The author also created a library for the neural network written by C# language which has shown the best performance on handwriting recognition task (MNIST and UNIPEN) using two essential techniques: elastic distortion that vastly expanded the size of the training set and convolution neural network. By using a network prototype in the library, the recognition system can create, load multi different neural networks on runtime. Furthermore, the system can combine several component networks to recognize a larger pattern dataset.
Convolution neural network (CNN)
The ability of multi-layer neural networks trained with gradient descent to learn complex, high-dimentional, non-linear mappings from large collections of examples make them obvious candidates for image recognition tasks. In the traditional model of pattern recognition, a hand-designed feature extractor gathers relevant information from input and eliminates irrelevant variabilities. A trainer classifier (normally, a standard, fully-connected multi-layer neural network can be used as a classifier) then categorizes the resulting feature vectors into classes. However, it could have some problems which should influent to the recognition results. The convolution neural network solves this shortcoming of traditional one to achieve the best performance on pattern recognition task.
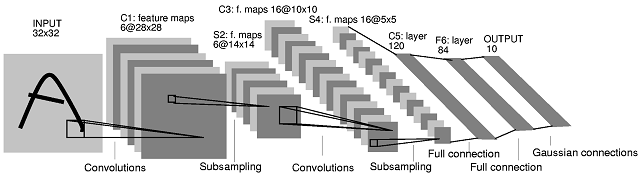
Fig. 1. A Typical Convolutional Neural Network (LeNET 5)[1]<o:p>
The CNNs is a special form of multi-layer neural network. Like other networks, CNNs are trained by back propagation algorithms. The difference is inside their architecture. The convolutional network combines three architectural ideas to ensure some degree of shift, scale, and distortion invariance: local receptive field, shared weights (or weight replication) spatial or temporal sub-sampling. They have been designed especially to recognize patterns directly from digital images with the minimum of pre-processing operations. The preprocessing and classification modules are in a single integrated scheme. The architecture details of CNN have been described comprehensively in articles of Dr. Yahn LeCun and Dr. Patrice Simard [1],[3].
The typical convolutional neural network for handwritten digit recognition is shown in figure. 1. It consists a set of several layers. The input layer is of size 32 x32 and receives the gray-level image containing the digit to recognize. The pixel intensities are normalized between −1 and +1. The first hidden layer C1 consists six feature maps each having 25 weights, constituting a 5x5 trainable kernel, and a bias. The values of the feature map are computed by convolving the input layer with respective kernel and applying an activation function to get the results. All values of the feature map are constrained to share the same trainable kernel or the same weights values. Because of the border effects, the feature maps’ size is 28x28, smaller than the input layer.
Each convolution layer is followed by a sub-sampling layer which reduces the dimension of the respective convolution layer’s feature maps by factor two. Hence the sub-sampling maps of the hidden layer S2 are of size 14x14. Similarly, layer C3 has 16 convolution maps of size 10x10 and layer S4 has 16 sub-sampling maps of size 5x5. The functions are implemented exactly as same as the layer C1 and S2 perform. The S4 layer’s feature maps are of size 5x5 which is too small for a third convolution layer. The C1 to S4 layers of this neural network can be viewed as a trainable feature extractor. Then, a trainable classifier is added to the feature extractor, in the form of 3 fully connected layers (a universal classifier).

Fig. 2. An input image followed by a feature map performing a 5 × 5 convolution and a 2 × 2 sub-sampling map
Dr. Partrice Simard in his article "Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis," [3] presented a different model of CNN for handwritten digit recognition which integrated convolution and sub-sampling processes in to a single layer. This model extracts simple feature maps at a higher resolution, and then converts them into more complex feature maps at a coarser resolution by sub-sampling a layer by a factor two. The width of the trainable kernel is chosen be centered on a unit (odd size), to have sufficient overlap to not lose information (3 would be too small with only one unit overlap), but yet to not have redundant computation (7 would be too large, with 5 units or over 70% overlap). Padding the input (making it larger so that there are feature units centered on the border) does not improve performance significantly. With no padding, a sub-sampling of two, and a trainable kernel of size 5x5, each convolution layer reduces the feature map size from n to (n-3)/2. Since the initial MNIST input using in this model is of size 28x28, the nearest value which generates an integer size after 2 layers of convolution is 29x29. After 2 layers of convolution, the feature of size 5x5 is too small for a third layer of convolution. The first two layers of this neural network can be viewed as a trainable feature extractor. Then, a trainable classifier is added to the feature extractor, in the form of 2 fully connected layers (a universal classifier).
Fig. 3. A convolution network based on Dr. Partrice Simard’s model<o:p>
Back Propagation
Back propagation is the process that updates the change in the weights for each layer, which starts with the last layer and moves backwards through the layers until the first layer is reached. Standard back propagation does not need to be used in the network library because of slow convergence. Instead, the technique called “Stochastic diagonal Levenberg-Marquardt method”, which was proposed by Dr. LeCun in his article "Efficient BackProp” [2], has been applied.
The UNIPEN trainset
In a large collaborative effort, a wide number of research institutes and industry have generated the UNIPEN standard and database [5]. Originally hosted by NIST, the data was divided into two distributions, dubbed the training set (train_r01_v07 set) and devset. Since 1999, the International UNIPEN Foundation (iUF) hosts the data, with the goal to safeguard the distribution of the training set and to promote the use of online handwriting in research and applications.
Due to UNIPEN training set is collection of particular datasets from different research institutes, these datasets are decomposed using some specific procedure. In order to be able to compare my system’s recognition results to published researches, the UNIPEN training set is used as training input to my recognizer. However, my approach is a little bit different; some general points in the structure of these datasets have been found to create a procedure which can decompose all datasets in the training set correctly in most cases.
The UNIPEN format is described in [5],[6],[15]. The format of a UNIPEN data file has KEYWORDS which are divided to several groups like: Mandatory declarations, Data documentation, Alphabet, Lexicon, Data layout, Unit system, Pen trajectory¸ Data annotations. In order to get the information and categorize these keywords, a collection of classes based on the above groups have been created which can help the system to get and categorize all necessary information from data file.
Image pre-processing and segmentation
Segmentation is an important step to pattern recognition system. Normally, projection techniques are applied to separate lines, words, and characters in a text image. However, it will be difficult if characters are organized in confusion. Therefore, a new algorithm has been developed to solve this issue.
<o:p>
Fig. 4. New algorithm for getting isolated character’s rectangle boundary.
Fig. 5. Steps of isolated character
segmentation
The figure 5 presents a sample of applying the above algorithm to a hand written character. Getting character’s rectangle boundary is started from the first left pixel of the character. The boundary is expanded step by step from left to right, from top to bottom until the boundary can wrap the character. A similar algorithm can be applied to get the character’s boundary from the topmost pixel.
By changing horizontal and vertical steps, the system can get not only isolated characters but also words or sentences without changing algorithm.
Fig. 6. Samples of word segmentation and isolated
character segmentation
Using this technique together with other well-known segmentation methods can help the system to recognize characters better in complex text images.
Recognition System using multi neural networks
The recognition results of the convolution network are really high to small patterns collection such as digit, capital letters or lower case letters etc. However, when we want to create a larger neural network which can recognize a bigger collection like digit and English letters (62 characters) for example, the problems begin appear. Finding an optimized and large enough network becomes more difficult, training network by large input patterns takes much longer time. Convergent speech of the network is slower and especially, the accuracy rate is significant decrease because bigger bad written characters, many similar and confusable characters etc. Furthermore, assuming we can create a good enough network which can recognize accurately English characters but it certainly cannot recognize properly a special character outsize its outputs set (a Russian or Chinese character) because it does not have expansion capacity. Therefore, creating a unique network for very large patterns classifier is very difficult and may be impossible.
<o:p>
Fig. 7. A handwriting recognition system
using multi neural networks
The proposed solution to the above problems is instead of using a unique big network we can use multi smaller networks which have very high recognition rate to these own output sets. Beside the official output sets (digit, letters…) these networks have an additional unknown output (unknown character). It means that if the input pattern is not recognized as a character of official outputs it will be understand as an unknown character (Figure 3). For a large pattern collection like handwritten characters, there are so many similar characters which can make not only machine but also human confuse in some cases such as: O, 0 and o; 9, 4,g,q etc. These characters can make networks misrecognize. By using an additional spellchecker/voting module at the output, the system can significant increate recognition rate. The input pattern is recognized by all component networks. These outputs (except unknown outputs) then will be set as the inputs of the spellchecker/voting module. The module will bases on previous recognized characters, internal dictionary and other factors to decide which one will be the most accurated recognized character.
This solution overcomes almost limits of the traditional model. The new system includes a several small networks which are simple for optimizing to get the best recognition results. Training these small networks takes less time than a huge network. Especially, the new model is really flexible and expandable. Depending on the requirement we can load one or more networks; we can also add new networks to the system to recognize new patterns without change or rebuilt the model. All these small networks have reusable capacity to another multi neural networks system.
Recognition results.
In order to evaluate the library to a handwritten recognition system, the author experiments the library on two different handwritten training sets are MNIST and UNIPEN. The results can reach to 99% accuracy rate to MNIST training set [10], 97% to UNIPEN digits, 89% to UNIPEN digits and capital letters (1a,1b) and 89% to UNIPEN lower case letters (1c)[13].
Fig. 8. Network
training interface using UNIPEN trainset (experiment in 1c)
The figure 8 is the network training interface of the demo program. The training can reach to 89% accuracy after 48 epochs to lower case letters set 1c (the first training time is 30 epochs, the second time is 18 epochs). After the first 30 epochs, the etaTrainingRate was too small which influenced to network training performance. So the network was trained again in second time with bigger initial etaTrainingRate = 0.00045.
Fig. 9. Statistics
of network training’ parameters after 62 epochs
Figure 9 is network training’s parameters statistics of the digits and capital letters recognition network (36 outputs network). By using Stochastic diagonal Levenberg-Marquardt method in back propagation process, the convergent speech of network becomes much faster than standard back propagation. After 65 epochs the accuracy rate of the network can reach to 89%.
In order to recognize a larger character set such as English characters (62 characters), a recognition system based on the model presented in figure 5 has been created. This system is a combination of three high recognition rate neural networks: digit (97%), capital letters (89%) and low case letters (89%). The system has proved its efficient recognition capacity by using an additional spell checker module.
Fig. 10. Mouse
drawing characters recognition using multi networks [13]
All the library, demo program, source code and training results can be downloaded at [13].
Conclusion
The paper presented a method of handwriting recognition using artificial convolution neural network. By the combination of convolution neural network, elastic distortion technique and Stochastic diagonal Levenberg-Marquardt method, the experimental neural networks can reach to positive results. Furthermore, the proposed model using multi component neural networks also presented an ability of creating efficient and flexible recognition systems to large pattern sets such as English characters set etc. By using a spell checker and voting module at the output, the proposed system can choose the most accurated characters from high recognition rate component networks. Hence, it can get the better recognition results to a traditional one.
References
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, "Gradient-Based Learning Applied to Document Recognition", Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998. [46 pages].
2. Y. LeCun, L. Bottou, G. Orr, and K. Muller, "Efficient BackProp", in Neural Networks: Tricks of the trade, (G. Orr and Muller K., eds.), 1998. [44 pages]
3. Patrice Y. Simard, Dave Steinkraus, John Platt, "Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis," International Conference on Document Analysis and Recognition (ICDAR), IEEE Computer Society, Los Alamitos, pp. 958-962, 2003.
4. Fabien Lauer, Ching Y. Suen and Gerard Bloch, "A Trainable Feature Extractor for Handwritten Digit Recognition", Elsevier Science, February 2006
5. I. Guyon, L. Schomaker, R. Plamondon, R. Liberman, and S. Janet, “Unipen project of on-line data exchange and recognizer benchmarks”. In Proceedings of the 12th International Conference on Pattern Recognition, ICPR’94, pages 29–33, Jerusalem, Israel, October 1994. IAPRIEEE.
6. Louis Vuurpijl, Ralph Niels, Merijn van Erp Nijmegen, “Verifying the UNIPEN devset”.
7. Marc Parizeau, Alexandre Lemieux, and Christian Gagné, “Character Recognition Experiments using Unipen Data”. Parizeau & al., Proc. of ICDAR 2001, September 10-13, Seatle.
8. List of publications by Dr. Yann LeCun. http://yann.lecun.com/exdb/publis/index.html
9. Mike O'Neill, “Neural Network for Recognition of Handwritten Digits”. http://www.codeproject.com/Articles/16650/Neural-Network-for-Recognition-of-Handwritten-Digi
10. Pham Viet Dung, “Neural Network for Recognition of Handwritten Digits in C#”. http://www.codeproject.com/Articles/143059/Neural-Network-for-Recognition-of-Handwritten-Digi
11. Pham Viet Dung, “Library for online handwriting recognition system using UNIPEN database”. http://www.codeproject.com/Articles/363596/Library-for-online-handwriting-recognition-system
12. Pham Viet Dung, “UPV – UNIPEN online handwriting recognition database viewer control”. http://www.codeproject.com/Articles/346244/UPV-UNIPEN-online-handwriting-recognition-database
13. Pham Viet Dung,” Large pattern recognition system using multi neural networks ”. http://www.codeproject.com/Articles/376798/Large-pattern-recognition-system-using-multi-neura
14. Modified NIST ("MNIST") database (11,594 KB total).

