This article is a user guide to a static analysis tool for C++ code. Among other things, the tool can clean up #include lists, highlight violations of C++ best practices, and analyze dependencies within the code base. It can also implement many of its suggestions by editing the code. The article also provides a high-level overview of the tool's implementation.
Introduction
C++ is a large language—too large, some would argue. Because it's a superset of C, it's easy for developers with a C background to build a hybrid OO/non-OO system. C++ also kept the preprocessor, which is sometimes used in what can only be described as despicable ways. And rather than risk offending legacy systems, the C++ standards committee seems very reluctant to deprecate anything—but not at all reluctant to keep adding what seems like one pedantic feature after another, at least to those of us struggling to keep up.
As a result of all this, there are often many ways to do something in C++, and figuring out which way is best can be difficult. Without guidance, it can only be learned through torturous experience. It is therefore unsurprising that there are many books about C++ best practices, such as Scott Meyers' Effective C++ and its sequels. But it's easy to forget their recommendations when you're immersed in coding, especially when new to the language. Of course, some developers don't even bother to read such books, being of the "If it works, it's correct—so don't touch it!" school. Having a tool that could serve as an automated Scott Meyers code inspector would go a long way to addressing these issues.
Background
When I started to develop the Robust Services Core (RSC), I had a reasonable knowledge of C++ but was far from proficient. The code grew very organically and was continually refactored. As I became more familiar with C++ and needed to revisit areas of the code that had lain dormant for a while, I kept finding things that I would now do differently. But there was always more code to develop and never enough time to do a tedious code inspection to find and "fix" all the things that could be improved.
Eventually I decided that, at the very least, it would be nice to clean up all the #include directives. Surely there was a publicly available tool for this. This was circa 2013, and the only thing I found was a Google initiative called "Include What You Use", which appeared to have been mothballed.1 I therefore decided to write such a tool as a diversion from the main focus of RSC.
Some diversion! It soon became apparent that fixing #include lists, to add the directives that should be there and remove those that shouldn't, meant writing a parser. And not just a parser, but something closer to a compiler, because it would also have to do name resolution and other things. Another option was to take an open-source C++ compiler and either modify it or extract the necessary information from files that it might produce.
Rather than give up, I decided to try writing the tool from scratch. It would be a learning experience, even if the attempt ultimately had to be abandoned. This article describes the current state of the code that emerged.
Using the Code
Not only does the code clean up #include directives, it serves as an automated Scott Meyers code inspector that can implement many of its recommendations by suitably editing the source code. Its main drawback is that it only supports the subset of C++11 that RSC uses. Although this is a reasonable subset of the language, what's missing will hamper its usefulness to projects that use unsupported language features. Adding one of these missing language features can be anywhere from moderately easy to quite challenging. Nonetheless, feel free to request that a specific language feature be supported—or even volunteer to implement it! This will make the tool useful to a wider range of projects.
This article focuses on how to use the code, not so much on how it works. However, it concludes with a high-level overview of the design to provide a roadmap for those who want to dig into the code.
Walkthroughs
Defining the Library
Before the tool can be used, the files that make up the code base must be defined. This can be done right after RSC starts by entering the command >read buildlib from the CLI. That ">" is RSC's CLI prompt and is not entered, but this article uses it to denote a CLI command. A dump of all CLI commands is available in help.cli2; scroll down to somewhere around line 1247, to "ct>help full", to see those in the ct directory, which is where the tool is implemented.
What >read buildlib does is execute the script buildlib, which contains a sequence of CLI commands. This results in the execution of the following commands, which are copied from the console transcript file that RSC generates, with commands not relevant to this article removed:
nb>read buildlib
nb>ct
ct>read lib.create
ct>import subs subs
ct>import nbase nb
ct>import ntool nt
ct>import ctool ct
ct>import nwork nw
ct>import sbase sb
ct>import stool st
ct>import mbase mb
ct>import cbase cb
ct>import pbase pb
ct>import onode on
ct>import cnode cn
ct>import rnode rn
ct>import snode sn
ct>import anode an
ct>import diplo dip
ct>import rsc rsc
The tool is in the ct directory, so the command >ct is used to access the CLI commands in that directory. The script lib.create is then read. It contains a series of >import commands that add, to the code library, all of the directories that are needed to compile the project (RSC, in this case). For example, the command
ct>import ctool ct
imports the code in the ct directory, which can subsequently be referred to as ctool in other CLI commands. The path to this directory is relative to the SourcePath configuration parameter. When RSC starts up, it obtains its configuration parameters from the file element.config. So to use the tools on your own code, you need to
- Modify element.config by setting its
SourcePath entry to a directory that subtends all of your project's code files. If no SourcePath is specified, RSC itself will be analyzed. - Create a file similar to lib.create in the same directory as RSC's lib.create. Each of the
>import commands in that file must specify a directory that is relative to your new setting for SourcePath. - Copy the subs directory from RSC into your own project, just below your
SourcePath directory, and include the command >import subs "subs", as found in RSC's lib.create, in your version of lib.create. - Modify the buildlib script to
>read your version of lib.create.
Each >import command ends up creating a CodeDir instance for its directory and a CodeFile instance for each code file3 in that directory. There are currently two restrictions:
- Each file name must be unique (i.e., the same name cannot be used in more than one directory).
- All of the code files in a directory get imported (i.e., there is no way to exclude a code file).
Parsing the Code
Once all of the source code directories have been imported, the entire code library can be parsed, which is a prerequisite to checking it with the static analysis tool. This is done with the command
>parse - win64 $files
in which
- specifies that no parser options are being used (the only options are ones that enable debug tools)win64 specifies that the target is 64-bit Windows (other targets are win32 and linux)$files is a built-in library variable that contains the set of all code files
If $files is replaced with f ctool, meaning all the code files in the ct directory, the result (again taken from the console transcript file) looks like this:
ct>parse - win64 f ctool
cctype
cmath
csignal
cstdint
cstdio
errno.h
exception
execinfo.h
functional
ioctl.h
iosfwd
mcheck.h
poll.h
resource.h
sched.h
typeinfo
utility
winerror.h
cstddef
endian.h
in.h
ios
process.h
ratio
spawn.h
stdlib.h
system_error
wait.h
atomic
cstdlib
cstring
cxxabi.h
iomanip
iterator
malloc.h
memory
mman.h
new
ostream
pthread.h
queue
socket.h
stack
unistd.h
algorithm
istream
list
map
netdb.h
set
unordered_map
vector
iostream
string
bitset
ctime
filesystem
fstream
sstream
chrono
windows.h
dbghelp.h
intsafe.h
mutex
thread
winsock2.h
condition_variable
ws2tcpip.h
FunctionGuard.h
SysDecls.h
LibraryTypes.h
Parser.cpp
std::chrono::duration<long long,std::ratio<1,10000000>>
std::chrono::time_point<std::chrono::system_clock,std::chrono::duration<long long,std::ratio<1,10000000>>>
CodeTools::CxxCharLiteral<char,CodeTools::Cxx::Encoding::ASCII>
CodeTools::CxxCharLiteral<char16_t,CodeTools::Cxx::Encoding::U16>
CodeTools::CxxCharLiteral<char32_t,CodeTools::Cxx::Encoding::U32>
CodeTools::CxxCharLiteral<wchar_t,CodeTools::Cxx::Encoding::WIDE>
std::iterator_t<const CodeTools::Cxx::Keyword>
std::unique_ptr<CodeTools::StringLiteral>
std::move<std::unique_ptr<CodeTools::StringLiteral>>
std::unique_ptr<CodeTools::Elif>
std::move<std::unique_ptr<CodeTools::Elif>>
std::unique_ptr<CodeTools::Else>
std::move<std::unique_ptr<CodeTools::Else>>
std::unique_ptr<CodeTools::Endif>
std::move<std::unique_ptr<CodeTools::Endif>>
std::unique_ptr<CodeTools::Error>
std::unique_ptr<CodeTools::Iff>
std::move<std::unique_ptr<CodeTools::Iff>>
std::unique_ptr<CodeTools::Ifdef>
std::move<std::unique_ptr<CodeTools::Ifdef>>
std::unique_ptr<CodeTools::Ifndef>
std::move<std::unique_ptr<CodeTools::Ifndef>>
std::unique_ptr<CodeTools::Line>
std::unique_ptr<CodeTools::Pragma>
std::unique_ptr<CodeTools::Undef>
std::move<std::unique_ptr<CodeTools::Undef>>
Updating cross-reference...
Total=204, failed=0
As each file is parsed, its name is displayed. Template instantiations are indented (and indented further, when one template causes the instantiation of another).
The first RSC file to be parsed is FunctionGuard.h. The files that precede it are either from the standard library, Windows, or Linux. However, they are not the actual instances of those files. Rather, they are taken from the subs directory, which contains simplified versions of them. These versions avoid the need to
>import files that are external to the project from a wide range of directories#define all the names that would be needed to correctly navigate all the #ifdefs in external files- support C++ language features used by external files but not by the project
- parse lots of things that the project doesn't use
Consequently, before you can >parse your own project, you must ensure that the subs directory contains a stand-in for each external header that your project #includes, and that each stand-in declares the items that you use from it. Note that in the case of templates, subs headers do not need to provide function definitions.
Three things can go wrong during >parse. In decreasing order of severity, they are
-
An exception. The tool needs to be fixed so that it will fail gracefully if it encounters something that it cannot parse or compile.
-
Code cannot be parsed because it uses something that the parser doesn't support. A log shows where the parse failed, and the entire file fails to parse. This can be fixed either by enhancing the parser or by modifying the code so it doesn't use things that the parser doesn't understand. If it isn't fixed, it leads to problems of the next type in files that #include the one that failed to parse.
-
Code parses but cannot be compiled (for example, by resolving each name and function call). Again, a log describes the problem and where it occurred. It could be a bug in the tool, or it could be that the code is using something that is not declared by a file in the subs directory. Frequently, the problem is a missing #include: files in the subs directory transitively #include far less than their real-world counterparts, so it is important to #include the file that actually declares each item.
The more of these logs that occur, the more likely it is that the tool will emit incorrect warnings when it performs a code inspection. However, these logs are much less severe than a parser failure. A parser failure means nothing in the file was understood. But here, only the line of code mentioned in the log was not understood.
Performing a Code Inspection
Now that all of the code has been parsed, it can be checked for violations of design guidelines:
>check rsc $files
This produces the file rsc.check, which contains all of the warnings that were found. Basic documentation for each of the warnings that >check can produce can be seen in the file cppcheck. You will find that they are not the usual "pointer could be null" or "mixing signed and unsigned ints" types of warnings emitted by static analysis tools that mostly analyze the code as if it were vanilla C. Instead, this tool is more oriented toward C++ best practices, such as Rule of 5 violations and highlighting things that could be const, protected, or private.
If you run >check on a subset of the code, it will ask if you first want to parse any unparsed code that would be needed in a successful build. Parsing the additional code avoids false positives, such as warnings that a function is unused or not even defined.
Before publishing a new RSC release, I usually run >check on all of the code and use the diff tool in VS2022's Git Changes tab to see if any new warnings have arisen since the last release.
There are two ways to suppress a warning:
- To suppress all occurrences of a warning, modify the function
CodeWarning::Initialize. Change the constructor call for the warning's attributes by setting the secod bool argument (the disabled flag) to true. - To suppress only some occurrences of a warning, modify the function
CodeWarning::Suppress, which contains many examples of warnings that are suppressed in RSC's code.
Because headers in the subs directory do not provide function implementations for templates, >check can erroneously recommend things such as
- removing an
#include that is needed to make a destructor visible to a unique_ptr template instance - declaring a data member
const even though it is inserted in a set and must therefore allow std::move - removing most of the things in Allocators.h (which is only invoked from the STL, not directly from RSC)
Applying the Recommendations
The >fix command is currently able to resolve 101 of the 148 possible warnings:
fix : Interactively fixes warnings detected by >check.
(0:148) : warning number from Wnnn (0 = all warnings)
(t|f) : prompt before fixing?
<str> : a set of code files
For example, the following modifies all code files by deleting unnecessary #include directives, which is warning W018:
>fix 18 f $files
To select which occurrences of a warning to fix, ask to be prompted. For example,
>fix 53 t $files
will prompt before fixing each occurrence of warning W053, "Data could be const".
WARNING: Before using >fix, be sure that you can recover the original version of the file if something goes wrong. Although it is regularly used on RSC's code, that doesn't mean it's been thoroughly tested!
Exporting the Library
After the code has been parsed, the >export command can generate any combination of the following files:
-
A .lib file displays parsed code in a standard format and includes
-
the underlying type for each auto variable;
-
the number of times each item was
-
referenced,
-
initialized, read, or written (for data),
-
called (for functions); and
-
the file in which each item was defined (for data and functions).
-
A .trim file lists the external symbols used within each file, as well as the recommendations for which #include directives, using statements, and forward declarations the file should add or remove. Those recommendations also appear as warnings in the .check file.
-
An .xref file contains a global cross-reference (each symbol, followed a list of the files that use it, along with the line numbers where the symbol appears).
Renaming Identifiers
The >rename command allows namespaces, classes, functions, data, enumerations, enumerators, typedefs, and macro names to be renamed. Its syntax is >rename <oldname> <newname>, where <oldname> can be qualified with scope operators or selected from a list that is provided if the name is ambiguous.
Analyzing Code Dependencies
Many of the CLI commands in the ct directory take an expression as their last parameter. So far, we've only mentioned $files, but an expression can contain both variables and operators. The user defines a variable with the >assign command, and the library also provides the following variables, which cannot be modified directly:
| Variable | Contents |
$dirs | directories that have been added to the library by >import |
$files | all code files (headers and implementations) found in $dirs |
$hdrs | headers in $files |
$cpps | implementations (.c*) in $files |
$subs | headers that declare items which are external to the code base |
$exts | headers that appear in an #include directive but whose directories were not added to the library by >import (which will cause >parse to fail) |
$vars | all variables (those above, and any that the user has defined) |
An expression is evaluated left to right, but parentheses can be used to override this. A variable is a set of directories, files, or C++ code items. The following notation is used in the expressions that appear below:
| Set | Contents |
| D | the name of a directory (as defined by >import) or a set of directories |
| F | the name of a specific file or a set of files |
| C | the name of a specific C++ code item or a set of such items |
| S | any of the above (D, F, or C) |
Here are the operators that can be used as soon as >import commands have built the library. The Expression column specifies the type of parameter(s) that the operator expects. The Result column is what the operator returns, which can be used as the input to other operators or commands such as >assign and >list.
| Operator Name | Expression | Result | Semantics |
| union | S1 | S2 | S | set union of S1 and S2 (the '|' is optional) |
| intersection | S1 & S2 | S | set intersection of S1 and S2 |
| difference | S1 - S2 | S | set difference between S1 and S2 |
| files | f S | F | the files in S |
| directories | d S | D | the directories in S |
| filename | F fn <str> | F | files in F with the file name <str>* |
| filetype | F ft <str> | F | files in F with the file type *.<str> |
| matches | F ms <str> | F | files in F whose name partially matches <str> |
| in | F in D | F | files in F whose directory is in D |
| users | us F | F | files that #include any in F |
| used by | ub F | F | files that any in F #include |
| affecters | as F | F | ub F, transitively |
| affected by | ab F | F | us F, transitively |
| common affecters | ca F | F | (as f1) & (as f2) & … (as fn), where f1…fn are the files in F |
After the >parse command has run, additional operators become available for compiled code:
| Operator Name | Expression | Result | Semantics |
| implements | im F | F | for each item declared (defined) in F, add the file that defines (declares) it |
| needers | ns F | F | files that also need F in a build (im ab F, transitively) |
| needed by | nb F | F | files that F also needs in a build (im as F, transitively) |
| declared by | db S | C | code items declared within S |
| declarers | ds C | C | code items that declare the items in C |
| definitions | df C | C | definitions (if separate from declarations) of the items in C |
| referenced by | rb S | C | code items referenced within S |
| referencers | rs C | C | code items that reference those in C |
The main purpose of these operators is to analyze dependencies among code files and C++ items. Here are some simple examples as an introduction.
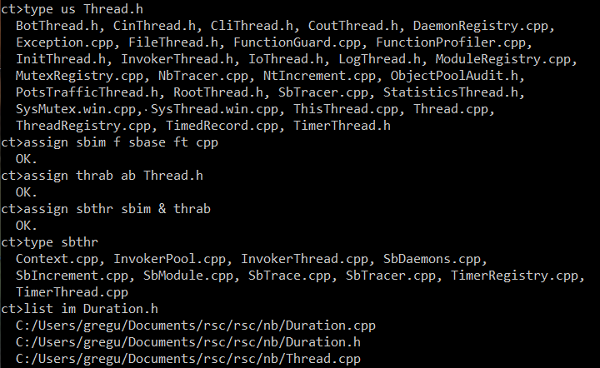
In the first image, the first command lists the users of Thread.h. If you searched all of RSC's code files for include "Thread.h", these are the files that you would find. Next, the .cpp files in the sbase directory are assigned to the variable sbim, and the files that could be affected by changing Thread.h are assigned to thrab. The intersection of sbim and thrab is assigned to sbthr and the result is displayed. These are the .cpp files in the sbase directory that could be affected by changing Thread.h. Finally, the files that implement Duration.h are listed. What's Thread.cpp doing in there?! Well, if you looked at the code, you would find that a number of constants declared in Duration.h, and used even before main is entered, are initialized at the bottom of Thread.cpp to avoid the "static initialization order fiasco" for which C++ is so infamous.4
We continue by assigning Thread to thr. But Thread can refer to many things: the Thread class, its constructor, or one of its forward declarations. So we have to indicate that we want the constructor. If we had entered Thread::Thread instead, it would have been unambiguous. When we list thr, we see that it's a function in Thread.h. If we list its definition, we see that its implementation begins on line 1062 of Thread.cpp. Finally, listing the items referenced by thr reveals a forward declaration of Daemon and the enumerator Faction. These types are used to specify the parameters to the Thread constructor.

If we list the items referenced by the definition of thr—that is, by the constructor's implementation—the output fills the screen:
Finally, listing the references to thr reveals the constructors that make a base class constructor call to Thread:
The operators db, ds, df, rb, and rs allow dependencies between C++ code items, not just files, to be analyzed. This can assist the architect who wants to layer a monolithic code base by partitioning it into libraries so that the software not required by a given product can be excluded from its build. Although these operators return sets of C++ code items, the files where those items reside can easily be found by prefixing the f operator, and the db and rb operators can also be used on files or even directories. For example:
>list f ds C displays the files that declare the items in C
>list f rs C displays the files that reference the items in C
>list db F1 & rb F2 displays the items declared in files in F1 and referenced by files in F2
Additional Details
What to #include
Interactions exist among the warnings for adding and removing #include directives, using statements, and forward declarations. CodeFile::Trim generates these warnings. Its basic rules are
- Always
#include something if nothing guarantees that it will be visible transitively. - Don't
#include something that will definitely be visible transitively. It is necessary to #include a base class, as well as a class that is used directly. However, it is not necessary to #include their base classes, even when using something declared in one of those transitive base classes. Similarly, it is not necessary for a .cpp to #include anything that its header will #include. - If a class is only used indirectly (i.e., as a pointer or reference type), don't
#include it. Use a forward declaration instead. If there is no guarantee that one will be visible transitively, add one to this file. - A header should not contain a
using directive or declaration. It is therefore told to remove it, and any .cpp that relies on it is told to add it. - If an
#include, forward declaration, or using statement is not needed to resolve a symbol, remove it.
All of these warnings can be resolved by >fix, which will, for example, insert a forward declaration in the correct namespace and fully qualify symbols from another namespace when removing a using statement.
High-Level Design
The parser is implemented using recursive descent, which makes its code easy to read and modify. The advent of unique_ptr was a godsend to these types of parsers, which were previously cursed by the need to delete objects when backing up. Placing each of these objects in a unique_ptr allows the parser to back up without having to write any code to delete them.
As each code file is read in during >import, #include relationships are noted. This allows a global compile order to be calculated. The only other preprocessing that occurs before parsing is to erase, within C++ code, any macro name that is defined as an empty string. One such name is NO_OP, which RSC uses before or after a bare semicolon when a for statement is missing one of the components in its parentheses.
Once this simple preprocessing is complete, all of the code is parsed together, in a single pass. After an item is parsed, it is added to the scope (namespace, class, function, or code block) in which it appears, and its virtual EnterScope function is invoked. It is then compiled by invoking its virtual EnterBlock function. An item's EnterScope or EnterBlock function also invokes the same function on each of its constituent parts.
The tool does not check everything in the same way that a full compiler must. It assumes that the code correctly compiles and links, so it only contains enough checks to produce a correct parse. Its grammar, which is informally documented in the relevant functions, is simpler than a complete C++ grammar.
Some of the warnings generated by >check are detected during >parse, and some are detected during >check itself, through the virtual function Check.
CodeFile::Trim, mentioned in the previous section, uses the virtual function GetUsages to obtain, from all of its file's C++ items, the symbols that are used (a) as base classes, (b) directly, and (c) indirectly; those that were resolved by (d) forward declarations, (e) friend declarations, and (f) using statements; and those that were (g) inherited.
References are tracked by the virtual functions AddToXref and AddReference. This allows >export to create its cross-reference. The C++ items declared within another are obtained from the virtual function GetDecls, which supports the db operator.
C++ items created during >parse are kept synchronized with the code when >fix edits it. This involves deleting C++ items whose code is erased, and incrementally compiling inserted code to create new C++ items. However, changes to a function implementation are not incrementally compiled; it is easier to simply delete the entire implementation and recompile the new one.
Performance
My system takes about 2m 20s to >read buildlib, >parse, >check, and >export all of RSC's code. That's using RSC's release build, which disables various optimizations so that it can be debugged (it's about 3½ times as fast as a debug build, but only half as fast as a fully optimized release build). Microsoft's C++ compiler takes almost exactly the same amount of time to build RSC. Of course, this isn't a true apples-to-apples comparison because the tool doesn't lay out memory, emit object code, or generate files for each translation unit. But it only uses one core, isn't fully optimized, gathers information that a regular compiler doesn't (during >parse), inspects the code (>check), and generates several large files (>export).
RSC consists of ~840 source code files and ~100K lines of code, excluding those that are blank or that only contain braces or comments. When its release build initializes using its default configuration file under Win32, it uses ~100MB. After executing >read buildlib, >parse, >check, and >export, it has grown by another ~125MB.
The tools don't generate any intermediate or scratch files; everything is kept in memory. Using files would be a significant change, so the amount of available memory ultimately limits the size of the code library that the tools can accommodate. But my guess is that anyone with that much code could also provide a machine with enough memory—or simply purchase a commercial equivalent of the tool.
List of Code Files
The ct directory contains all of the code. If you want to dive into it, here's a summary of the files in that directory:
| File | Description |
CodeCoverage | code coverage tool (not discussed in this article) |
CodeDir | a directory that contains source code |
CodeDirSet | a set of code directories |
CodeFile | a file that contains source code |
CodeFileSet | a set of code files |
CodeItemSet | a set of C++ code items |
CodeSet | base class for CodeDirSet, CodeFileSet, and CodeItemSet |
CodeTypes | types for parsing and static analysis |
CtIncrement | CLI commands applicable to the ct directory |
CtModule | initialization of ct directory |
Cxx | types for C++ |
CxxArea | namespaces, classes, and class template instances |
CxxCharLiteral | character literals |
CxxDirective | preprocessor directives |
CxxExecute | tracks code during compilation |
CxxFwd | forward declarations |
CxxLocation | tracks an item's location in its source file |
CxxNamed | low-level named C++ items |
CxxRoot | global namespace and built-in terminals |
CxxScope | code blocks, data items, and functions |
CxxScoped | arguments, base classes, enums, enumerators, forwards, friends, terminals, typedefs, usings |
CxxStatement | statements used in functions |
CxxStrLiteral | string literals |
CxxString | string utilities |
CxxSymbols | parser symbol tables |
CxxToken | low-level unnamed C++ items |
CxxVector | function templates for vectors of C++ items |
Editor | source code editor for >fix command |
Interpreter | interprets expressions (in CLI commands) that manipulate instances of LibrarySet subclasses |
Lexer | lexical analysis for Parser and Editor |
Library | code files, code directories, and CLI symbols |
LibraryErrSet | generates an error message when a CLI command does not apply to a set |
LibraryItem | base class for CodeDir, CodeFile, LibrarySet, and CxxToken |
LibrarySet | base class for CodeSet, LibraryErrSet, and LibraryVarSet (sets of items to which CLI commands can be applied) |
LibraryTypes | types for code library |
LibraryVarSet | built-in or user-defined library variables |
Parser | parser for C++ source code |
SetOperations | difference, intersection, and union operators for instances of LibrarySet |
Notes
1 While preparing this article, I checked to see if anything had changed. Google's project eventually gained traction and is now on GitHub. They took the approach of building on Clang, and they say that they're currently "alpha" quality and that changes to Clang sometimes break them.
2 The file help.cli has a .txt extension, which is omitted from file names in this article.
3 A code file is assumed to be any file with no extension (e.g., <string>) or a .h, .c, .hpp, .cpp, .hxx, .cxx, .hh, .cc, .h++, or .c++ extension. This is hard-coded in CxxString::IsCodeFile.
4 Since this was written, Duration.h was simplified by using <chrono>, so Thread.cpp no longer appears in its list of implementers.
History
- 4th October, 2019: Initial version
There have been many updates to this article since its initial version. The article is reposted when its download changes, which occurs when a new release includes bug fixes and one or more of the following:
- enhance
>parse to support more C++ language features - enhance
>check to generate new warnings - enhance
>fix to resolve more warnings
These changes are summarized on RSC's Releases page, usually under the CodeTools section of the release notes.

