Introduction
Moving from one code management and ticketing system to another can be a real pain. The article is about migrating from an Assembla account to a Github one using 3 Python scripts, Assembla's Tickets export and Github repositories import.
In a nutshell, the process includes:
- Create a backup of all Tickets (which unfortunately doesn't contain any images or attached files).
- Import the Assembla repository from Github's new repository.
- Customizing the scripts, as explained in this article.
- Run our script which handles all the rest via automation.
Optionally:
- Update existing Issues in a Github Repo
- Delete all Issues in a Github Repo
The Assembla SVN
Assembla is a code hosting provider of Subversion, offering managed and self-hosted SVN. For the purpose of this article, we will export an Assembla space which has an SVN repository, into a Github space with a Git repository. I have created a test SVN for the purpose of this article, which can be found here.
The Assembla Tickets
Assembla has a Ticketing system. Each ticket can contain apart from its text, several elements we would need to export. Some of these elements are optional of course, but when they exist, we would want to have them exported as well.
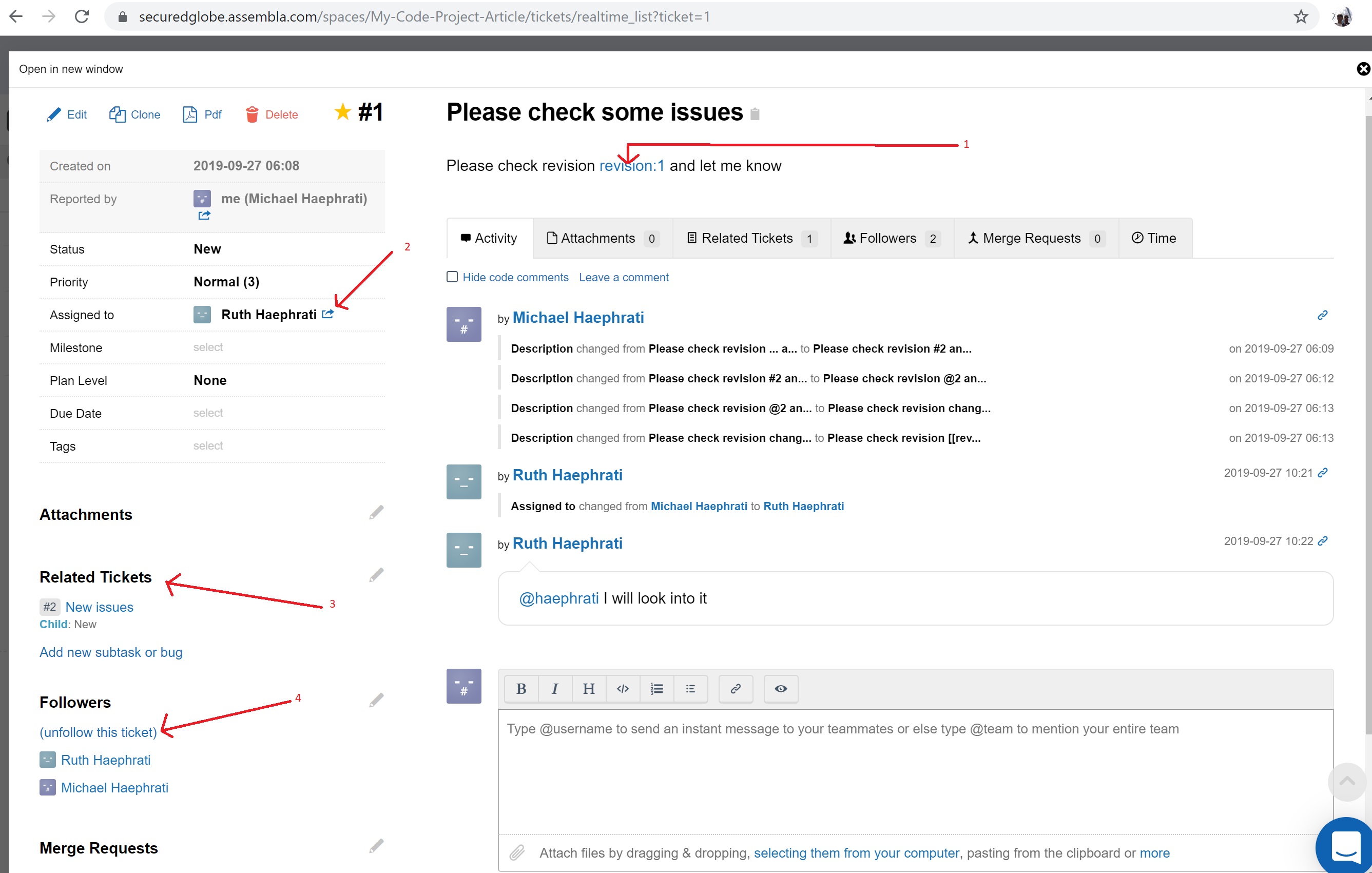
- Commit - A reference to a revision (commit). Such reference is made by inserting [[revision:1]] to the text.
- Assignee - a user whom this ticket was assigned to.
- Related Tickets - Assembla allows associating one ticket with another, and defining several relationships between them, such as "child", "parent", or just "related". While we can use reference to related tickets as part of the Ticket's body and/or comments, and they can be exported to, and imported from Github, there is no "Related Issues" feature which is similar to the one Assembla has.
- Followers - Each ticket can have followers which are other users who have access to this space. By default, the creator of the ticket and the assignee are followers.

- Attachments - Each ticket can have files of any type attached to it. When exporting to Github, some files can be imported as is, while others (for example: video files) must be first compressed into a .zip file. Images should be displayed inline, as part of the ticket.
Step 1 - Export the SVN
First, you need to copy the address of your SVN to the Clipboard.
Assembla sometimes displays the address in the wrong format.
The format should be:
For example:
Now we go to our new Github space and import it.
Paste the address of the original Assembla SVN, and press Begin Import.
At this stage, in case your original Assembla space is private, you will be asked to enter the Assembla's credentials so Github can connect to your old space and import the SVN from it.
Now, after import has completed, you have successfully transferred not only the source code but all revisions of it. You can see them if you go to:
For example:
Step 2 - Exporting Tickets
The next step is to export the tickets into a .bak file, generated by Assembla. As we will explain further, that file alone isn't enough to complete the migration, as it won't contain files, including images which are parts of the tickets.
First go to the Tickets settings. You can use the following link:
or (since you already logged in):
For example:
or (if you are logged in):
Press the "Settings" link.
Tickets are then exported in a JSON-like custom format. Tickets attachments are not be exported, and we need a custom made solution to export attachments as well.
First, you will see a message: "Backup successfully scheduled.", so you need to come back to this page to collect the exported file, which will end with .bak.
Step 3 - Exporting Files
Your Space ID
Our script automatically finds the space_id identifier. This ID is not the name you have given your Assembla space, but a combination of characters and numbers generated by Assembla. The space_id is one of the main building blocks of Assembla API.
Preparing the Python Environment
Preparations for the rest of the process, require installing Python and several libraries.
Download and Installing Python
- Use the following link to download.
- After installing it, add the path to the installation location to the
PATH Environmental Variables.
The default location will be:
- C:\Users\<Your user name>\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Python 3.7-32
You can add this entry to PATH using the following command:
set path "%path%;c:\Users\<YOUR USER NAME>\AppData\Local\Programs\Python\Python37-32"
- Open Command Line (CMD) and enter the following line:
python -m pip install selenium pygithub requests webdriver_manager
You may get the following warning. To ensure our script will run smoothly, add the following entry:
setx path "%path%;c:\Users\<YOUR USER NAME>\
AppData\Local\Programs\Python\Python37-32\Scripts"
This will install the following extensions:
- Selenium - used for automation in general
- PyGithub - used for interfacing with the Github API
- Requests - used for HTTP communication
- webdriver_manager - Python Webdriver Manager. Used to access various web browsers.
Running Assembla-Github
Assembla-Github_v5.py is the Python script we used for the entire process.
It connects to our Assembla account and based on the .bak file we generated when we exported all tickets, it downloads any files referenced in our tickets.
python Assembla-Github_v5.py -r user/repo --download
You should see the following respond while our script is scanning the .bak file.
First, it finds out the space_id and next, it opens a Chrome browser with the Assembla web site, so you can enter your credentials.
After automatically entering your credentials, it begins importing the data to Github.
Step 4 - Importing to Github
The next steps are taken before running the next Python script, Assembla-Github.py.
You need to edit this script and add / edit the following parts:
Adding Credentials
Before proceeding, update the file Credentias.py with your Assembla and Github user and password:
class Credentials():
github_user = <your Github user>
github_password = <your Github password>
assembla_user = <You Assembla user>
assembla_password = <Your Assembla password>
Adding All Contributors
In the following block of code, add each of the contributor’s IDs separated by commas. Without adding the matching contributors, the "Issues" created will have "***" instead. Please note that the Issues are generated under the account used in credentials.py, so they will have the credentials' account holder as the "creator" of the "Issue", while information about the author of each original Ticket / comment will be added right after as part of the Issue's text.
val = {
"securedglobe": "c68pgUDuer4PiDacwqjQWU",
}
Running the Script
Our script scans the sub folders within our main folder, so we can select the Assembla backup file (.bak) we wish to process.
Parsing Tickets
First, we process attachments based on the .bak file downloading the actual file mentioned in each ticket from Assembla. To do so, we use the following function:
print("Parsing tickets...")
tickets_arr = []
find_tickets = re.findall(r"^tickets,\s.*", tickets, re.MULTILINE)
for item in find_tickets:
arr = re.search(r"\[.*\]", item)
fault_replace = str(arr.group(0)).replace(",null", ',"null"')
array = ast.literal_eval(fault_replace)
ticket_info = {
"ticket_id": array[0],
"ticket_number": array[1],
"ticket_reporter_id": array[2],
"ticket_assigned_id": array[3],
"ticket_title": array[5],
"ticket_priority": array[6],
"ticket_description": array[7],
"ticket_created_on": array[8],
"ticket_milestone": array[10],
"ticket_username": None,
"status": "",
"references": set(),
"real_number": None,
"ticket_comments": []
}
"assigned_to_id","space_id","summary",
"priority","description",
"component_id","notification_list",
"importance","story_importance","permission_type",
"total_estimate","total_invested_hours","total_working_hours",
find_ticket_comments = re.findall(r"^ticket_comments,\s\[\d+\,
{}.*".format(ticket_info["ticket_id"]), tickets, re.MULTILINE)
for item in find_ticket_comments:
arr = re.search(r"\[.*\]", item)
fault_replace = re.sub(r",null", ',"null"', str(arr.group(0)))
array = ast.literal_eval(fault_replace)
"updated_at","comment","ticket_changes","rendered"]
comment_info = {
"id": array[0],
"ticket_id": array[1],
"user_id": array[2],
"created_on": array[3],
"updated_at": array[4],
"comment": array[5],
"ticket_changes": array[6],
"rendered": array[7],
"attachments": [],
"username": None
}
ticket_info["ticket_comments"].append(comment_info)
sorted_comments_array = sorted(
ticket_info["ticket_comments"],
key=lambda x: datetime.strptime(x['created_on'], '%Y-%m-%dT%H:%M:%S.000+00:00')
)
ticket_info["ticket_comments"] = sorted_comments_array
tickets_arr.append(ticket_info)
return tickets_arr
The function returns an array with all tickets.
Handling Ticket Updates
Each Assembla Ticket (and similarly each GitHub Issue) is in many ways a "conversation", where followings and users can comment to. The next function scans these statuses and comments and associates them with the original ticket.
def parseStatus(tickets):
print("Parsing tickets status data...")
find_status = re.findall(r"^ticket_changes,\s.*", tickets, re.MULTILINE)
status_arr = []
for item in find_status:
"subject","before","after",
"extras","created_at","updated_at"]
arr = re.search(r"\[.*\]", item)
fault_replace = str(arr.group(0)).replace(",null", ',"null"')
array = ast.literal_eval(fault_replace)
ticket_status_info = {
"id": array[0],
"ticket_comment_id": array[1],
"subject": array[2],
"before": array[3],
"after": array[4],
"extras": array[5],
"created_at": array[6],
"updated_at": array[7],
"ticket_comments": []
}
status_arr.append(ticket_status_info)
return status_arr
Handling Tickets Attachments
Each Ticket in Assembla may contain one or more attachments. As mentioned earlier, Assembla doesn't imply any limitation as for the file types or sizes you can attach, however Github allows only certain file types to become part of an "Issue", so we define these allowed types in our script, and anything not within these types, is packed as a .zip file and then uploaded.
EXTS = ['jpg', 'png', 'jpeg', 'docx', 'log', 'pdf', 'pptx', 'txt', 'zip']
# list of allowed extensions
Fields fetched from Tickets
The following fields are fetched from each Ticket:
- Ticket number - We need to take into consideration that in the event a certain ticket has been entirely deleted from Assembla, and not just marked as "
Fixed" or "Invalid", when importing to Github, the numbering would have become different. That is being resolved by adding "dummy" tickets for each deleted Assembla ticket, just so the numbering is preserved. - Reporter ID - the user ID of the creator of this ticket
- Assigned ID - the user ID of the Assignee
- Title - the title of the ticket
- Priority - the priority of the ticket
- Description - the ticket body's text
- Creation date - date in which the ticket has been created
- Milestone - if a Milestone has been assigned to the ticket, it will be shown here
"ticket_id": array[0],
"ticket_number": array[1],
"ticket_reporter_id": array[2],
"ticket_assigned_id": array[3],
"ticket_title": array[5],
"ticket_priority": array[6],
"ticket_description": array[7],
"ticket_created_on": array[8],
"ticket_milestone": array[10],
Other fields are filled by calling a function:
"references": set(),
"ticket_comments": []
To process all attachments, we use the parseAttachmentsFromBak function:
def parseAttachmentsFromBak(sid, tickets):
filelist = []
link = f"https://bigfiles.assembla.com/spaces/{sid}/documents/download/"
if not os.path.isfile('filenames.txt'):
find_files = re.findall(r".*?\[\[(file|image):(.*?)(\|.*?)?\]\].*?", tickets)
for file in find_files:
if file:
filelist.append(rf"{file[1]}")
else:
dirfile = glob.glob(f"{FILES_DIR}\**")
with open("filenames.txt") as file:
for line in file:
filelist.append(line.strip())
for file in dirfile:
file = file.replace(f"{FILES_DIR}\\", "")
file = file[:file.rfind(".")]
for c, fi in enumerate(filelist):
if fi in file:
del filelist[c]
elif os.path.isfile(FILES_DIR+'\\'+fi):
del filelist[c]
chrome_options = webdriver.ChromeOptions()
path = os.path.dirname(os.path.realpath(__file__))
chrome_options.add_experimental_option("prefs", {
"download.default_directory": f"{path}\\temp",
"download.prompt_for_download": False,
"download.directory_upgrade": True,
"safebrowsing.enabled": True
})
chrome_options.add_argument("user-data-dir=selenium")
chrome_options.add_argument("start-maximized")
chrome_options.add_argument("--disable-infobars")
try:
driver = webdriver.Chrome(executable_path=ChromeDriverManager().install(),
options=chrome_options, service_log_path='NUL')
except ValueError:
print("Error opening Chrome. Chrome is not installed?")
exit(1)
FILE_SAVER_MIN_JS_URL =
"https://raw.githubusercontent.com/eligrey/FileSaver.js/master/src/FileSaver.js"
file_saver_min_js = requests.get(FILE_SAVER_MIN_JS_URL).content
driver.get("https://bigfiles.assembla.com/login")
sleep(2)
checklink = driver.execute_script("return document.URL;")
if checklink == "https://bigfiles.assembla.com/login":
login = driver.find_element_by_id("user_login")
login.clear()
login.send_keys(Credentials.assembla_user)
passw = driver.find_element_by_id("user_password")
passw.clear()
passw.send_keys(Credentials.assembla_password)
btn = driver.find_element_by_id("signin_button")
btn.click()
sleep(1)
for file in filelist:
download_script = f"""
return fetch('{file}',
{{
"credentials": "same-origin",
"headers": {{"accept":"*/*;q=0.8",
"accept-language":"en-US,en;q=0.9"}},
"referrerPolicy": "no-referrer-when-downgrade",
"body": null,
"method": "GET",
"mode": "cors"
}}
).then(resp => {{
return resp.blob();
}}).then(blob => {{
saveAs(blob, '{file}');
}});
"""
driver.get(f"{link}{file}")
sleep(1)
try:
loc = driver.find_element_by_tag_name('img')
if loc:
driver.execute_script(file_saver_min_js.decode("ascii"))
driver.execute_script(download_script)
WebDriverWait(driver, 120, 1).until(every_downloads_chrome)
WebDriverWait(driver, 120, 1).until(every_downloads_chrome)
except TimeoutException:
pass
except NoSuchElementException:
pass
except JavascriptException:
pass
sleep(8)
temps = glob.glob(f"temp\**")
try:
for tm in temps:
if tm.endswith('jpg'):
os.rename(tm, f"files\{file}.jpg")
elif tm.endswith('png'):
os.rename(tm, f"files\{file}.png")
elif tm.endswith('zip'):
os.rename(tm, f"files\{file}.zip")
elif tm.endswith('pdf'):
os.rename(tm, f"files\{file}.pdf")
elif tm.endswith('docx'):
os.rename(tm, f"files\{file}.docx")
elif tm.endswith('txt'):
os.rename(tm, f"files\{file}.txt")
else:
os.rename(tm, f"files\{file}")
except FileExistsError:
pass
driver.close()
driver.quit()
Renaming Attachment Files
The Tickets attachments in Assembla are kept under a random alphanumeric name such as "c68pgUDuer4PiDacwqjQWU", and we need to convert these names back to the original name and extension of each ticket's attachment. That is done using the renameFiles function:
def renameFiles(sorted_tickets_array):
print("Renaming files...")
for item in sorted_tickets_array:
for comment in item["ticket_comments"]:
if comment["attachments"]:
for attach in comment["attachments"]:
fname = attach["filename"]
fid = attach["file_id"]
if not fname.endswith('.png') and not fname.endswith('.jpg') \
and not fname.endswith('.PNG') and not fname.endswith('.JPG'):
dot = re.search(r"\..*", fname)
dot = "" if not dot else dot.group(0)
try:
get_file = glob.glob(f"{FILES_DIR}\{fid}.*")
if not get_file:
get_file = glob.glob(f"{FILES_DIR}\{fid}")
get_dot = re.search(r"\..*", get_file[0])
get_dot = "" if not get_dot else get_dot.group(0)
if get_dot and not dot:
dot = get_dot
if get_dot.endswith('.png') or
get_dot.endswith('.jpg') or get_dot.endswith('.PNG') \
or get_dot.endswith('.JPG'):
pass
else:
if os.path.isfile(f"{FILES_DIR}\{fid}{dot}"):
pass
else:
print(f"Renaming: {fid} -> {fid}{dot}")
os.rename(get_file[0], f"{FILES_DIR}\{fid}{dot}")
counter = 0
for ext in EXTS:
if ext not in dot:
counter += 1
else:
pass
if counter == len(EXTS) and not get_file[0].endswith(".htm"):
print(f"Making zip file -> {fid}.zip")
if os.path.isfile(f"{FILES_DIR}\{fid}.zip"):
os.remove(f"{FILES_DIR}\{fid}.zip")
obj = zipfile.ZipFile(f"{FILES_DIR}\{fid}.zip", 'w')
obj.write(f"{FILES_DIR}\{fid}{dot}")
obj.close()
except Exception:
pass
Updating Tickets After a Previous Run
If you only need to update an existing Repo and you already have the data exported from Assembla, you can use the update option:
python Assembla-Github_v5.py -f <Your .bak file> -r <Github user>/<Github repo name> --update
For example:
python Assembla-Github_v5.py
-f My-Code-Project-Article-2019-09-27.bak -r haephrati/CodeProjectArticle-Test --update
Any files attached to tickets will then be downloaded and placed in a folder named "files". File types that can't be added to a Github "issue" as-is, will be compressed into a .zip archive.
Uploading the Data to Github
Once we are ready, we can upload the data to a Github repo. We can either update an existing Repo (which already has "issues") or create all issues for a given Repo from scratch. Such repo must already have the source code of the Repo imported to it as explained before.
def uploadToGithub(dirfiles, tickets, working_repo):
filelist = []
ready_files = ""
path = os.path.dirname(os.path.realpath(__file__))
find_files = re.findall(r".*?\[\[(file|image):(.*?)(\|.*?)?\]\].*?", tickets)
for file in find_files:
for dr in dirfiles:
di = str(dr.replace(f"{FILES_DIR}\\", ""))
di = di[:di.rfind('.')]
if di in file[1]:
filelist.append(f"{path}\{FILES_DIR}\{dr}")
if os.path.isfile('files.txt'):
print('files.txt exists, parsing existing links...')
ex_files = ""
with open('files.txt', 'r') as file:
ex_files = file.read()
file_links = re.findall(r".*?\!\[(.*?)\]\((.*?)\).*?", ex_files)
file_urls = re.findall(r".*?\[(.*?)\]\((.*?)\).*?", ex_files)
get_img = re.findall(r"alt=\"(.*?)\"\ssrc=\"(.*?)\"", ex_files)
file_links.extend(get_img)
file_links.extend(file_urls)
for flink in file_links:
for co, fi in enumerate(filelist):
if flink[0] in fi:
del filelist[co]
if not filelist:
print("uploadToGithub: Nothing to upload.")
return 1
chrome_options = Options()
chrome_options.add_argument("user-data-dir=selenium")
chrome_options.add_argument("start-maximized")
chrome_options.add_argument("--disable-infobars")
try:
driver = webdriver.Chrome(executable_path=ChromeDriverManager().install(),
options=chrome_options, service_log_path='NUL')
except ValueError:
print("Error opening Chrome. Chrome is not installed?")
exit(1)
driver.implicitly_wait(1000)
driver.get(f"https://github.com/login")
sleep(2)
link = driver.execute_script("return document.URL;")
if link == "https://github.com/login":
login = driver.find_element_by_id("login_field")
login.clear()
login.send_keys(Credentials.github_user)
passw = driver.find_element_by_id("password")
passw.clear()
passw.send_keys(Credentials.github_password)
btn = driver.find_elements_by_xpath
("//*[@class='btn btn-primary btn-block']")
btn[0].click()
sleep(1)
driver.get(f"https://github.com/{working_repo}/issues/")
sleep(2)
findButton = driver.find_elements_by_xpath("//*[@class='btn btn-primary']")
findButton[0].click()
sleep(2)
chunks = [filelist[i:i + 8] for i in range(0, len(filelist), 8)]
for chunk in chunks:
chk = (' \n ').join(chunk)
findBody = driver.find_element_by_id("issue_body")
findBody.clear()
findButton = driver.find_element_by_id("fc-issue_body")
findButton.clear()
if chk:
findButton.send_keys(chk)
print("Waiting for uploads to finish...")
sleep(5)
while True:
chk = findBody.get_attribute('value')
if "]()" in chk:
sleep(5)
else:
break
with open('files.txt', 'a+') as ff:
ff.write(chk)
ready_files += chk
driver.close()
driver.quit()
return ready_files
Results
After the process is completed, you should see in your new Github repo your original Assembla Tickets, now as Issues, and your source code with all Commits. You can then see references to other tickets (issues), attached and inline files and images and references to commits.
Other Helper Functions
For other uses or needs, here are some additional functions added to our script:
Deleting All Issues in a Repo
By using the delete parameter, you can delete all Issues in a given Repo.
python Assembla-Github_v5.py -r user/repo --delete
For example:
python Assembla-Github_v5.py -r haephrati/test --delete
and the source code for doing so:
def deleteIssues(working_repo):
chrome_options = Options()
chrome_options.add_argument("user-data-dir=selenium")
chrome_options.add_argument("start-maximized")
chrome_options.add_argument("--disable-infobars")
try:
driver = webdriver.Chrome(executable_path=ChromeDriverManager().install(),
options=chrome_options, service_log_path='NUL')
except ValueError:
print("Error opening Chrome. Chrome is not installed?")
exit(1)
driver.implicitly_wait(1000)
driver.get(f"https://github.com/login")
sleep(2)
link = driver.execute_script("return document.URL;")
if link == "https://github.com/login":
login = driver.find_element_by_id("login_field")
login.clear()
login.send_keys(Credentials.github_user)
passw = driver.find_element_by_id("password")
passw.clear()
passw.send_keys(Credentials.github_password)
btn = driver.find_elements_by_xpath("//*[@class='btn btn-primary btn-block']")
btn[0].click()
sleep(1)
driver.get(f"https://github.com/{working_repo}/issues/")
while True:
get_tab = driver.find_element_by_xpath
("//*[@class='js-selected-navigation-item
selected reponav-item']/child::*[@class='Counter']")
if int(get_tab.text) == 0:
print("No issues left. Exit.")
break
else:
find_issues = driver.find_elements_by_xpath
("//*[@class='link-gray-dark v-align-middle no-underline h4 js-navigation-open']")
link = find_issues[0].get_attribute("href")
driver.get(link)
find_notif = driver.find_elements_by_tag_name("summary")
find_notif[len(find_notif)-1].click()
sleep(1)
find_button = driver.find_element_by_xpath
("//*[@class='btn btn-danger input-block float-none']")
find_button.click()
sleep(1)
driver.get(f"https://github.com/{working_repo}/issues/")
driver.close()
driver.quit()
Error Handling
In our script, we try to address possible errors:
for ticket in sorted_tickets_array:
try:
issue_name = f"""{ticket["ticket_title"]}"""
lock = None
for check_issue in repo.get_issues(state='all'):
if check_issue and check_issue.title == issue_name:
print("Issue exists; passing: [", check_issue.title, "]")
lock = 1
if not lock:
issue = createIssue(issue_name, ticket, repo, file_links)
addComments(ticket, issue, file_links, repo)
except RateLimitExceededException as e:
print(e, "Waiting 1 hour...")
sleep(60*61)
continue
except Exception as e:
print(e)
pass
Handling Security Measures That Interfere With Automation
Github, like other platform, has taken measures to prevent mass operation of their API, and after a while, these measures might block any additional operation. We identify this situation and, in such case, halt our operation for one hour.
That is handled by the following exception:
except RateLimitExceededException as e:
(e, "Waiting 1 hour...") sleep(60*61) continue
Points of Interest
History
- 30th September, 2019: Initial version

