On July 9, 2019, a new set of libraries for working with Azure services was announced. These SDKs target multiple languages including 🐍 Python, ☕ Java, JavaScript, and .NET. A few popular services are covered including Azure Cosmos DB.
Learn how I leveraged CosmosDB to store telemetry from a URL shortening tool, then analyze the data in a PowerBI dashboard.
The dashboard is useful but is only refreshed once a day. What if I could write something quick and easy to give me a real-time snapshot of things? To keep it simple, I decided to start with a console app. Oh, look at that. It’s done, and it appears my post about the new SDKs is the most popular page over the past 24 hours!
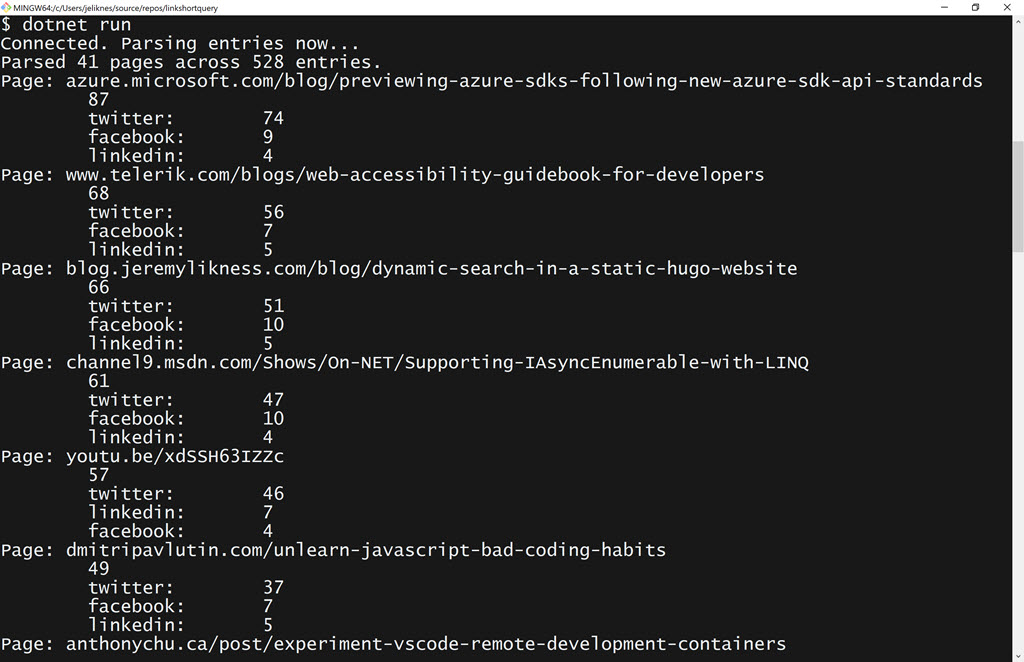
The finished app
But how did I get here? Let me back up, and I’ll start from the beginning.
The Console App
I decided to write something in cross-platform .NET Core. I already installed the .NET Core SDK, so I just needed to create a directory and initialize a new console application.
dotnet new console
I advise against checking credentials into source control, so I store them locally in an appSettings.json file that doesn’t get checked into source control thanks to a .gitIngore. That means adding the configuration package so I can read the settings:
dotnet add package Microsoft.Extensions.Configuration.Json
Finally, I added the new Azure SDK for Cosmos DB.
dotnet add package Microsoft.Azure.Cosmos --version 3.0.0.19-preview
After that, I launched Visual Studio Code and was on my way!
code .
Get Connected
The new SDKs contain plenty of samples to get started, so I “borrowed” the main code from here:
Azure/azure-cosmos-dotnet-v3/blob/master/Microsoft.Azure.Cosmos.Samples/CodeSamples/Queries/Program.cs
This code sets up a configuration service and pulls in the settings:
IConfigurationRoot configuration = new ConfigurationBuilder()
.AddJsonFile("appSettings.json")
.Build();
string endpoint = configuration["EndPointUrl"];
if (string.IsNullOrEmpty(endpoint))
{
throw new ArgumentNullException("Please specify a valid endpoint in the appSettings.json");
}
Of course, I had to create an appSettings.json file and populate it:
{
"EndPointUrl": "https://don't you wish.documents.azure.com:443",
"AuthorizationKey": "DoodleDoodleDeeWubbaWubbaWubba=="
}
(You didn’t think I’d give my credentials away, did you?)
To ensure the settings are published locally, I added this to my .csproj configuration:
<itemgroup>
<none include="appSettings.json">
<copytooutputdirectory>PreserveNewest</copytooutputdirectory>
</none>
</itemgroup>
The code to create the client is just a few lines of code. This instantiates the client and disposes of it when done.
using (CosmosClient client = new CosmosClient(endpoint, authKey))
{
await Program.RunQueryAsync(client);
}
I ran it at this point and no exceptions were thrown, so of course I knew it was time to ship to production. Err …
Open the Container
Azure Cosmos DB organizes data into database accounts that contain information about regions, failover, the type of API to use and other properties. Inside a database you can then have multiple containers that are partitioned and provisioned differently. I have a database named url-tracking with a container named url-stats.
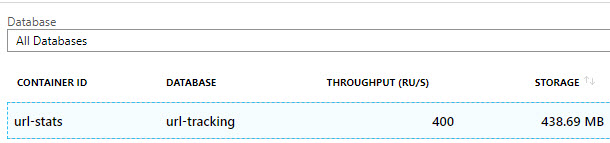
Cosmos DB Database and Container
I set up these names in my code:
private static readonly string CosmosDatabaseId = "url-tracking";
private static readonly string containerId = "url-stats";
Tip I use static readonly instead of const out of habit. I might want to move the values into a configuration file later, and with a static readonly I can initialize the values when the process is started as opposed to const that must be available at compile time.
I know the database and container already exist (this is my production data, not a demo with sample data) so getting to the container looks like this:
var cosmosDatabase = client.GetDatabase(CosmosDatabaseId);
var container = cosmosDatabase.GetContainer(containerId);
Console.WriteLine("Connected. Parsing entries now...");
Now it’s time to pull out the data!
The Shape of Data
There are a few interesting things to know about the metadata in my container. In what may have been a poor design choice but seemed fine at the time, I decided to take advantage of the fact that I don’t need a fixed schema with NoSQL. I track a medium that tells me where links are posted (for example, Twitter, Facebook, or even inside of a PowerPoint presentation). A sample entry for a Twitter click looks like this:
{
"id": "unique guid goes here",
"page": "azure.microsoft.com/blog/previewing-azure-sdks-following-new-azure-sdk-api-standards",
"shortUrl": "F61",
"campaign": "link",
"referrerUrl": "t.co/4EXayhRpzF",
"referrerHost": "t.co",
"agent": "Mozilla/5.0 etc...",
"browser": "Chrome",
"browserVersion": "77",
"browserWithVersion": "Chrome 77",
"desktop": 1,
"platform": "Windows",
"platformVersion": "10",
"platformWithVersion": "Windows 10",
"count": 1,
"timestamp": "2019-07-10T2054",
"host": "azure.microsoft.com",
"twitter": 1
}
If the same entry were from LinkedIn, it would look like this:
{
"id": "unique guid goes here",
"unimportant-stuff": "removed",
"count": 1,
"timestamp": "2019-07-10T2054",
"host": "azure.microsoft.com",
"linkedin": 1
}
Notice the property is different based on the medium. This poses a unique challenge for parsing the data. Dynamic languages like JavaScript handle it fine, but what about a strongly typed language like C#? In retrospect, I could have made it easier to intuit the “wildcard” property by doing this (note the added medium property):
{
"id": "unique guid goes here",
"unimportant-stuff": "removed",
"count": 1,
"timestamp": "2019-07-10T2054",
"host": "azure.microsoft.com",
"medium": "linkedin",
"linkedin": 1
}
… or even this:
{
"id": "unique guid goes here",
"unimportant-stuff": "removed",
"count": 1,
"timestamp": "2019-07-10T2054",
"host": "azure.microsoft.com",
"medium": {
"linkedin": 1
}
}
But I didn’t, so … for now the best I could come up with on short notice was look at the property after host. More on that in a bit. I may go back and write a utility to update the data structure later, but for now it has worked fine.
The Query
One advantage of the Azure Cosmos DB SQL API is that you can use SQL syntax to query the document. This is a perfectly valid query:
SELECT * FROM c WHERE <filter> ORDER BY c.timestamp DESC
However, I prefer to use LINQ because I don’t have to manipulate strings and can take a more fluent approach.
Wait, Jeremy. What is this LINQ you keep speaking of? If you’re new to C# and/or .NET, have no fear. LINQ stands for (and here’s the docs link) Language Integrated Query. It’s a way to write queries using C# methods without resorting to string manipulation. The example above becomes query.Select(c=>c).Where(c=>{//filter}).OrderByDescending(c=>c.timestamp)
The goal is simple: grab all entries from the past 24 hours and aggregate them on page and medium. Sort to list the most popular page first with a total click count, then within the page sort by the most popular mediums and show click count by medium. To hold the data, I created this:
var documents = new Dictionary<string,IDictionary<string,int>>();
The dictionary indexes by page, then within page has a nested dictionary indexed by medium and click count.
Next, I built my query. Here’s the cool part: the new SDKs fully support LINQ and have no problem with dynamic data! Instead of trying to project to a dynamic type, I used an IDictionary<string, object> to emulate a “property bag” (the strings are property names, the objects their respective values). The following code sets up the query and creates an iterator so that I can asynchronously fetch the results. Notice it’s perfectly fine to cast the value of an item in the dictionary to a proper DateTime property (see what I did there?) to filter my query.
var queryable = container
.GetItemLinqQueryable<IDictionary<string, object>>();
var oneDay = DateTime.UtcNow.AddDays(-1);
var query = queryable
.OrderByDescending(s => s["timestamp"])
.Where(s => (DateTime)s["timestamp"] > oneDay);
var iterator = query.ToFeedIterator();
That’s a LINQ query for you.
Even though the dictionary value is an object type so I don’t have to lock into a specific schema, the SDK is smart enough to serialize the values to their appropriate .NET types, in this case for timestamp a DateTime.
The generic strategy to iterate over the results is straightforward and as far as I can tell automatically handles throttling requests appropriately (I haven’t dug in deep enough to claim that with a certainty, but I had no issues with my datasets).
int entries = 0;
int pages = 0;
while (iterator.HasMoreResults)
{
foreach(var document in await iterator.ReadNextAsync())
{
entries += 1;
var page = document["page"].ToString();
if (!documents.ContainsKey(page))
{
documents.Add(page, new Dictionary<string,int>());
pages += 1;
}
}
}
As you can see, you simply ask if there are more results and then asynchronously iterate over the feed. The logic to track counts by medium has nothing to do with the SDK, so I broke it out here:
var pageData = documents[page];
bool medium = false;
foreach(var key in document.Keys)
{
if (medium) {
if (pageData.ContainsKey(key))
{
pageData[key] += 1;
}
else
{
pageData[key] = 1;
}
break;
}
else {
if (key == "host") {
medium = true;
}
}
}
I’m finding the property after the host property and using that to pivot and sum the data. Yes, this requires trust in the column ordering and is why I explained the big caveat earlier on. Fortunately, if for some reason the “wildcard” property doesn’t exist, the loop will just exit after host none the wiser.
Generate the Report
Now that the data is collected, generating the report is easy, especially with the help of LINQ. I show the totals, then sort pages by most clicked first, and within them sort by most clicked medium:
Console.WriteLine($"Parsed {pages} pages across {entries} entries.");
foreach (var page in documents
.OrderByDescending(kv => kv.Value.Values.Sum()))
{
Console.WriteLine(
$"Page: {page.Key}\n\t{page.Value.Values.Sum()}");
foreach (var medium in page.Value
.OrderByDescending(kv => kv.Value))
{
Console.WriteLine($"\t{medium.Key}:\t{medium.Value}");
}
}
Wow! That was easy. It took me about 30 minutes to write the code, and far longer to write this blog post. You can bet throughout the day I’ll run:
dotnet run
…and check to see how things are tracking.
Summary
The new SDKs are here, and so far, they look good. I was able to get up and running quickly, the API felt intuitive and the examples helped me work out how to solve my problem. I look forward to seeing these evolve based on feedback and see more services covered in future releases. I hope you found this useful. As always, please feel free to share your personal experiences and feedback in the comments below!
Get started with the new Azure SDKs.
Regards,