Digital publication can increase access to information, but can just as easily act as a barrier if care and attention is not given to accessibility. For example, if we publish a PDF that contains only images because it was scanned with optical character recognition (OCR), it is unlikely that a screen reader will be able to read the text.
Providing access to information for people with disabilities is one of the main driving forces behind a range of laws and standards on the accessibility of digital publications, which can help guide us towards creating accessible documents.
However, the benefits are broader than being legally compliant. For example:
- A scanned PDF would not support "reflow," which could otherwise have presented the content in a single column to make viewing easier on a smartphone.
- An image-only PDF wouldn't be visible to search engines, which need to read the text.
- It wouldn't be possible to copy and paste text from an image-only PDF.
There are many sources governing the accessibility of publications — and often providing useful guidance for creating them. The legislation most commonly referenced is:
- Section 508 of Rehabilitation Act (U.S)
- European Accessibility Act (Europe)
- UN Convention on the Rights of Persons with Disabilities, Article 9 (International)
Legal definitions like those listed above often rely on other standards to judge accessibility. These include:
- World Wide Web Consortium Web Content Accessibility Guidelines (W3C WCAG)
- PDF/UA, the easy-to-remember name given to the international standard ISO 14289
Interesting fact: PDF/UA was the first ISO standard ever to be published in a format complying with PDF/UA!
If you're not accustomed to creating accessible PDFs though, this can seem daunting.
In this article, we’ll get you started with some key information about the law, standards and techniques; show you how to incorporate Aspose.PDF for .NET into an application; and how to leverage it to create accessible PDF documents.
The anatomy of an Accessible PDF Document
There are many facets to an accessible PDF. The main requirement for an accessible PDF is that it is tagged.
Like in HTML, tags help represent the structure of a document. The biggest difference between HTML and PDF is that this logical structure is stored apart from the content in a PDF so that order is independent from what is displayed. Applications such as screen readers need this structure hierarchy (or structure tree) to know in which order to traverse and read the document.
What do we need to tag?
- All standard content on pages
- Annotations
- Multimedia objects
- Form fields
- Tables
- Lists
This includes adding actual text, alternate text, expansion text, or a different language to the tags where appropriate.
Using Aspose.PDF for .NET
Aspose.PDF is a family of development products for composing, editing, converting, and viewing PDF documents. In this tutorial we'll use Aspose.PDF for .NET to demonstrate some accessible PDF creation techniques in a C# application.
Aspose.PDF for .NET is bundled in a NuGet package, which you can add to any new or existing project for .NET Framework 2.0 through 4.7.2 and .NET Standard 2.0, Core 2.0, and Core 2.1. (See the complete list of requirements for more information).
In Visual Studio, install Aspose.PDF through the package manager by clicking Tools > NuGet Package Manager > Package Manager Console.
In the package manager, execute the following command:
Install-Package Aspose.PDF
You can also install the package through the GUI by right-clicking on the project and selecting Manage NuGet Packages.
Creating a new PDF through Code
This is a very simple example of generating a PDF during runtime in code that adds a page, a header, and some text. Aspose.PDF .NET is capable of constructing a much broader range of components including forms, graphs, images, links, watermarks, tables, bookmarks, annotations, attachments, and security features such as digitally signing.
In the following code we do the following steps. As you can see, the syntax is straightforward.
- Initialize a Document object.
- Add a page.
- Create heading and text elements.
- Add elements to the page paragraphs collection in required order.
- Save the created PDF.
Document document = new Document();
Page page = document.Pages.Add();
Heading h1 = new Heading(1);
h1.Text = "Heading 1";
h1.TextState.FontSize = 20;
TextFragment text = new TextFragment("Some text here...");
text.TextState.LineSpacing = 15f;
page.Paragraphs.Add(h1);
page.Paragraphs.Add(text);
document.Save(@"CreateExample.pdf");
This code creates the following PDF output:
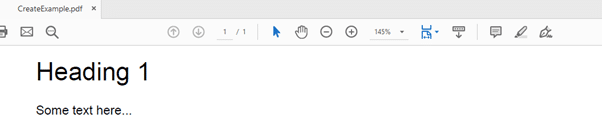
In just two lines of code, we can convert a markdown file to a PDF.
- Load a markdown file into a new Document object with the MD options.
- Save as a PDF.
var doc = new Document("sample.md", , new MdLoadOptions());
doc.Save("MarkdownToPDF.pdf");
We can also convert a PDF to another document format. Again, only two lines of code are required to convert a PDF to the Microsoft Word DOCX format.
- Load the PDF file into a new Document object.
- Save with SaveFormat.DocX.
Document pdfDocument = new Document("PDFToDOCX.pdf");
pdfDocument.Save("PDFToDOCX_out.docx", SaveFormat.DocX);
The conversion can be controlled further through the DocSaveOptions object.
- Load the PDF file into a new Document object.
- Initialize a new DocSaveOptions object.
- Specify the output format as DOCX.
- Enable recognition of bullets.
- Switch to Flow mode (which favors editability over preserving appearance).
Document pdfDocument = new Document("PDFToDOC.pdf");
var saveOptions = new DocSaveOptions
{
Format = DocSaveOptions.DocFormat.DocX,
RecognizeBullets = true,
Mode = DocSaveOptions.RecognitionMode.Flow
};
pdfDocument.Save("ConvertToDOCX_out.docx", saveOptions);
The documentation shows all formats that Aspose.PDF can work with, both importing and exporting.
How can Aspose.PDF for .NET Help with Accessibility?
PDFs are often manually composed in an application such as a word processor, then exported as a PDF. Design for accessibility should always begin with composition. This approach reduces the work required to test and revise the PDF for accessible results.
But if you don’t have the original medium or wish to create a new accessible PDF in code — perhaps because you need to create on-demand, customized PDFs — then Aspose.PDF .NET can help with its tagged PDF document feature.
Aspose.PDF NET includes a library of functions for creating accessible documents with the features required to comply with PDF/UA, including a logical structure tree, metadata, and additional descriptive text (alternative, expansion, and actual).
It can also be used to validate compliance with a single command:
using (var doc = new Document("input.pdf"))
{
bool isValid = doc.Validate("validation-log.xml", Aspose.Pdf.PdfFormat.PDF_UA_1);
}
Let's take a look at an example scenario: automating PDF/UA compliance for a batch of documents.
Aspose.PDF .NET is able to import from a wide range of formats, create tagged PDF documents, and validate PDF/UA compliance enabling us to easily automate a batch fix.
In this example we:
- Create a standard PDF that is not accessible by PDF/UA standards.
We’ve written some helper methods to create this (using Aspose.PDF .NET). We’ve left them out of this article for brevity but you can find them in the complete code sample on GitHub. - Run the validator on that PDF and consider the results.
- Open the PDF in code again and extract the content.
- Create a new tagged PDF document and add metadata.
- Insert the content extracted from the original PDF into a logical structure.
Even in this very simple PDF there are quite a few errors and a warning (if we had a broader range of component types, we would expect to see a few more errors).
- The document is not marked as tagged
- The document is not identified as PDF/UA compliant
- The image and text are not tagged
- The title is missing from the metadata and so also not displayed
- The language is missing from the metadata
<General>
<Problem Severity="Warning" Clause="7.1" ObjectID="" Page="" Convertable="True" Code="7.1:7.1(12.2)">'ViewerPreferences' dictionary missing</Problem>
<Problem Severity="Error" Clause="7.1" ObjectID="" Page="" Convertable="True" Code="7.1:7.2(12.2)">'DisplayDocTitle' entry is not set</Problem>
<Problem Severity="Error" Clause="7.1" ObjectID="" Page="" Convertable="True" Code="7.1:1.1(14.8.1)">Document is not marked as tagged</Problem>
<Problem Severity="Error" Clause="7.1" ObjectID="" Page="1" Convertable="False" Code="7.1:1.1(14.8)">XObject object not tagged</Problem>
<Problem Severity="Error" Clause="7.1" ObjectID="" Page="1" Convertable="False" Code="7.1:1.1(14.8)">Text object not tagged</Problem>
<Problem Severity="Warning" Clause="7.1" ObjectID="" Page="" Convertable="False" Code="7.1:2.1">Structure tree missing</Problem>
<Problem Severity="Error" Clause="7.1" ObjectID="" Page="" Convertable="True" Code="7.1:6.2">Title missing in document's XMP metadata</Problem>
</General>
<Text>
<Problem Severity="Error" Clause="7.2" ObjectID="" Page="1" Convertable="False" Code="7.2:3.1(14.9.2.2)">Natural language for text object cannot be determined</Problem>
</Text>
<VersionIdentification>
<Problem Severity="Error" Clause="5" ObjectID="" Page="" Convertable="True" Code="5:1">PDF/UA identifier missing</Problem>
</VersionIdentification>
Open the original non-compliant PDF. We’ll need a reference to the page containing the content we wish to extract. Note that Aspose.PDF .NET indexes from 1, not 0.
var originalDocument = new Document(inputFileName);
var pageOne = originalDocument.Pages[1];
Create a new tagged PDF with the minimum required metadata
- Initialize a new Document object for the tagged PDF.
- Create a reference to the root element of the tagged content ready to build the logical structure accessible to screen readers.
- Set the document title metadata, which will default to displaying in the title bar in Aspose.PDF. This fixes validation errors and also an error regarding missing metadata.
- Set the document language metadata. This fixes a validation error related to language and also an error regarding missing metadata.
var taggedDocument = new Document();
ITaggedContent taggedContent = taggedDocument.TaggedContent;
StructureElement rootElement = taggedContent.RootElement;
taggedContent.SetTitle("Our compliant document.");
taggedContent.SetLanguage("en-US");
Next, we'll extract and convert some text to a header structure element.
The Aspose.pdf.LogicalStructure namespace provides a number of types for representing standard elements semantically and automatically tagging for inclusion in the document structure hierarchy in reading order.
In the example that follows, we are copying some text and an image from the original document, but we could just as easily be creating a tagged PDF document in code with new content.
- Accept the TextFragmentAbsorber onto the page.
- Extract the existing header as the first TextFragment on the page.
- Create a new Aspose.Pdf.LogicalStructure.HeaderElement object.
- Copy across the text and font (embedding this) from the original text into the new element.
TextFragmentAbsorber textFragmentAbsorber = new TextFragmentAbsorber();
page.Accept(textFragmentAbsorber);
TextFragment originalHeaderText = textFragmentAbsorber.TextFragments[textIndex];
HeaderElement h1 = taggedContent.CreateHeaderElement(headerLevel);
h1.StructureTextState.ForegroundColor = originalHeaderText.TextState.ForegroundColor;
Font headerFont = FontRepository.FindFont(originalHeaderText.TextState.Font.FontName);
headerFont.IsEmbedded = true;
h1.StructureTextState.Font = headerFont;
h1.SetText(originalHeaderText.Text);
Next, extract and convert some text to a paragraph structure element. The process is similar to creating the header.
- Extract the text as the second TextFragment on the page.
- Create a new Aspose.Pdf.LogicalStructure.ParagraphElement object.
- Copy across the text, color, and font (embedding this) from the original text.
TextFragmentAbsorber textFragmentAbsorber = new TextFragmentAbsorber();
page.Accept(textFragmentAbsorber);
TextFragment originalText = textFragmentAbsorber.TextFragments[textIndex];
ParagraphElement p = taggedContent.CreateParagraphElement();
p.StructureTextState.ForegroundColor = originalText.TextState.ForegroundColor;
Font paraFont = FontRepository.FindFont(originalText.TextState.Font.FontName);
paraFont.IsEmbedded = true;
p.StructureTextState.Font = paraFont;
p.SetText(originalText.Text);
Perhaps we want to add the abbreviation W3C to the end of the text we imported. Within the Aspose.Pdf.LogicalStructure this is a straightforward task.
Here we will use an inline SpanElement (which you may be familiar with from HTML) to add a child element off the paragraph element we just created.
While we’re at it, we had better add expansion text to this new element (remember that PDF/UA requires that we use expansion text to describe abbreviations and jargon).
- Create a new span element.
- Set the text for span to "W3C".
- Set the expansion text for the span to "World Wide Web Consortium".
- Append the span to the end of the paragraph.
SpanElement w3cSpan = taggedContent.CreateSpanElement();
w3cSpan.SetText("W3C");
w3cSpan.ExpansionText = "World Wide Web Consortium"
p.AppendChild(w3cSpan);
We can also add an image to a figure structure element. For the image we also need to add alternative text so that a reader using assistive technology will know that it is the Aspose logo.
- Extract the existing image (the first image on the page) out to a file.
- Create a new Aspose.Pdf.LogicalStructure.FigureElement object from that file.
- Set the alternative text.
ImagePlacementAbsorber imagePlacementAbsorber = new ImagePlacementAbsorber();
page.Accept(imagePlacementAbsorber);
XImage xImage = imagePlacementAbsorber.ImagePlacements[imageIndex].Image;
FileStream outputImage = new FileStream("temp-image.png", FileMode.Create);
xImage.Save(outputImage, ImageFormat.Png);
outputImage.Close();
FigureElement figureElement = taggedContent.CreateFigureElement();
figureElement.SetImage("temp-image.png");
figureElement.AlternativeText = "Aspose logo";
Now we'll append the new elements to the new tagged PDF. From the root element on up, we append the three new elements in the required logical order.
Aspose.PDF will take care of the work constructing a structure tree with the correct tags names and any additional text we’ve added.
rootElement.AppendChild(h1);
rootElement.AppendChild(figureElement);
rootElement.AppendChild(p);
Finally, we save the tagged document and validate it to PDF/UA.
taggedDocument.Save(outputFileName);
using (var d = new Document(outputFileName))
{
bool isValid = d.Validate("compliant-validation-log.xml", Aspose.Pdf.PdfFormat.PDF_UA_1);
}
Next Steps
As you can see, Aspose.PDF makes it fairly straightforward to create PDFs that are accessible, and even test the accessibility of documents you've created programmatically.
A couple of good places to start learning about PDF/UA: PDF/UA in a Nutshell from the PDF Association and Achieving WCAG 2.0 with PDF/UA from AIIM (which includes mapping from WCAG to PDF/UA).
Download Aspose.PDF for .NET and try it yourself. You'll find the complete code sample on GitHub if you'd like to experiment further with the examples in this article, or check out the Aspose.PDF documentation and PDF Editor sample.

