Introduction
The data-driven programming method can flexibly control the execution logic according to different data types, but currently this programming method does not introduce scheduling technology, and the logic sequence to be executed is fixedly encoded in the execution program. Although the correspondence between data and processes can be extracted and placed separately in the database or controlled by a script-like dynamic language to increase flexibility, if the correspondence between data and processes cannot be fixed (such as the process to be executed according to a certain rule), Or the state of the process needs to be stored (such as waiting for other data or pending), the existing processing methods are no longer applicable, and a scheduling mechanism needs to be introduced.
Data-driven process scheduling includes data objects, process (function) objects and schedulers. Data and processes (functions) can be scheduled as objects. Processes (functions) are no longer fixedly located in one or some logical processing sequences. The scheduling of process objects is driven by data objects, with a description of the types of input and output data objects and a context for scheduling. The description of the process object is similar to the function prototype definition, except that in the function prototype definition, the types of input and output are not limited and may be too general (for example: function input string, this string may have many meanings, it may be a URL, It may be formatted data, it may be ordinary text, or a sequence with some meanings), and there is no constraint between the function execution logic and the environment (such as: referencing or modifying global variables), and it does not store scheduling related information such as running status, result in very weak schedulability. Most current scheduling is based on thread granularity. Many modern programming languages support the reflection method, which can obtain the representation of the function prototype. Although it is more complicated to implement, it can support the scheduling of functions. However, due to lack of clear definition of the meaning of input and output data objects, and the context related to scheduling, Scheduling via reflection mechanism lacks flexibility and requires strict logic control. Another microservices programming method is to split complex logic into small service units, but its original intention and purpose are more to reduce the complexity and efficiency of publish, maintenance and upgrade, rather than the microservices scheduling itself.
The scheduler searches for a process (function) object capable of processing the data object according to the type of the data object, allocates the data object to the process object for execution, and obtains the output data object. When looking for a process object, apps can set the desired output data object type. If there is no single process output of this type, apps can find the process object sequence for the output target data object type according to the input and output object types of the process object. The sequence forms a process chain that processes the input data objects and obtains the desired output data objects.
Process chain programming pchain (process chain) programming implements the scheduling and programming methods mentioned here, currently supports python language and can be installed via pip:
pip install pchain
Define Data Object
The data should have a type. If the data loses its type, the original meaning of the data is lost. At this time, the processing of this data needs to be processed by a predetermined logical sequence because only the designer knows the meaning of the data. Cannot achieve automatic scheduling. Supporting a flexible definition of a large number of data object types has meaning, as in the world we live in, there are millions of insect species.
Just as the traditional scheduling has the context of the thread, the scheduling of the data object also requires the context, recording which processes the data object has been allocated to prevent the data object from being repeatedly allocated, as shown below:
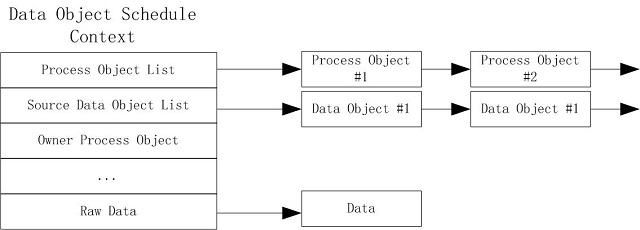
The process object list records the process objects to which the data objects have been assigned. Data points to specific data content or value. After a data object has scheduling context, more information can be recorded, such as a list of source objects: indicating which objects the data object depends on; owner process objects: indicating which process object the data object was generated by. These records reflect the data the relationship between data and the process.
The types supported by programming languages are raw types, such as integers, strings, floating-point types, and so on. These raw types do not have a specific meaning, such as integer, which can represent age, weight, size, and so on. Programming languages support structures or classes. These structures and classes have specific meanings, and their instances can be used as data objects to become input data or output data to other processes (processing functions).
Instances of classes defined in current programming languages lack such a context management structure that supports scheduling, and it is not possible to record whether the data object has been assigned to a process object, resulting in the inability to automatically assign and schedule data objects. Therefore, a new method of defining data objects is needed.
In the pchain implementation, the definition of python data objects is supported by the pydata module. It is implemented through the two functions, DefineType / DefineSubType. When defining the python data object type, you can specify the raw python type.
DefineType(tpname,rawtype=None)
DefineSubType(parenttype,tpname,rawtype = None)
Example:
pydata.DefineType("NumberClass",float)
pydata.DefineSubType(NumberClass,'IntClass')
When creating an instance of a data object, apps must specify a value or a raw instance. After the data object is created, its content should not be modified. App can call the Lock method. If the data object corresponds to a native instance of a python class, this method cannot prevent the modification of attributes in the instance, and it is guaranteed when it is used.
The data object not only records which processes have been assigned to support the scheduler's data object allocation process, but also records the relationships between the data objects, including which process object the data object was generated by and which data objects it was based on, and which data objects were generated by that data object. These relationships can be used to extract rules related to data objects. In order to support the rule system, the data objects need to have unique keywords. One-to-one correspondence between the data objects and the nodes in the rule network can be obtained by the GetTag function.
d = NumberClass(12.3)
key = d.GetTag()
print(key)
The output is:
6d5450b62cb0b8d2b4c0ace38eef4b4df697129e
Data objects can be stored as JSON strings and can be restored on other computers for sharing.
buf=Service._ServiceGroup._NewParaPkg()
realm.SaveObject(buf,d)
val = buf._ToJSon()
print(val)
The output is:
{"PackageInfo":[],"ObjectList":[{"PackageInfo":[],
"Value":[null,"gANHQCiZmZmZmZou"],"ClassName":"NumberClass"}]}
Define Process Object
A process object contains a description part that describes the type of input and output data and a logic execution part. The input and output of process objects must be the data objects defined above. Based on the management structure owned by these data objects, data object-based scheduling can be achieved. If an input of a process is not a data object, the scheduler cannot determine what data objects can be assigned to the process. And if the output of the process object is not a data object, the scheduler cannot further process the output data after the process produces output.
During the execution of a process, there are situations where the entire execution cannot be completed at once. For example, the process may have incomplete data, require more data objects, may need to be repeatedly executed, or may be suspended due to waiting. Therefore, the process object also needs a context for scheduling. The existing method (function) definition method does not support it, and a new process object needs to be defined.
In pchain, the definition of python process objects is supported by the pyproc module, which is implemented by the DefineProc function.
pyproc.DefineProc (tpname, InputDataType, OutputDataType, PyFunc)
For example:
@pyproc.DefineProc('HelloWorldProc',None,None)
def Execute(self) :
print('Hello world !')
return (0,1,None)
When the process object is used, an instance must be created. The process object defined by the above method is a python process object, which also corresponds to the CLE process object and is responsible for recording the context of the process execution.
cle_p = HelloWorldProc().Wrap()
The process object also has a unique Tag, which is obtained by the GetTag function, and the tags of all instances are the same.
key = cle_p.GetTag()
print(key)
The output is:
proc_global_HelloWorldProc
Process objects can be stored as JSON strings and can be restored on other computers for sharing.
buf=Service._ServiceGroup._NewParaPkg()
realm.SaveObject(buf,cle_p)
val = buf._ToJSon()
print(val)
The output is:
{"PackageInfo":[],"ObjectList":[{"ClassName":"HelloWorldProc",
"ObjectID":"fa3d7eb9-5720-490f-a47a-b7a0103c6e38","Type":"PCProc"}]}
Schedule Execution
By putting data objects and process objects together, apps can schedule execution. In pchain, the cell object manages the scheduling, and cells must be added to the realm for execution. Multiple cells can be added to the realm for execution. Here is a simple example, which is to enter two numbers from the keyboard and calculate their sum:
- Define data objects
pydata.DefineType('NumberClass')
- Define process objects
Two process objects are defined here, one process object is responsible for entering numbers from the keyboard, and one process object is responsible for calculating the sum of two numbers.
- Input Process Object
The process object does not need to enter a data object, it is entered from the keyboard; a data object is output. The definition is as follows:
@pyproc.DefineProc('InputProc',None,NumberClass)
def Execute(self) :
Context = self.Context
if Context['SelfObj'].Status < 0 :
return None
val = input('input a number : ')
return (4,1,NumberClass(val))
- Sum Process Object
This process object inputs two data objects, calculates the sum of the two, and prints them out. There is no output data object. The definition is as follows:
@pyproc.DefineProc('OutputProc',(NumberClass,NumberClass),None)
def Execute(self,num1,num2) :
Context = self.Context
print('sum = ', num1.value() + num2.value())
Context['Cell'].Finish()
return (0,1,None)
After execution is complete, call the Cell.Finish() function to end execution and exit.
- Create
Cell, Realm, add the process object to Cell for execution:
cell = Service.PCCellBase()
cell.AddProc(InputProc,OutputProc)
realm.AddCell(cell)
realm.Execute()
The results are as follows:
input a number : 1
input a number : 2
sum = 12
- Description of the scheduling process is as given below:
Scheduling is divided into two steps: data object allocation and process object execution. The data object allocation is processed first. If data can be assigned to a process, an execution instance of the process is created, the data object is assigned to the process, and then execution is scheduled in turn.
In the above example, there are two processes in the cell. Since 'InputProc' does not require input data and meets the scheduling conditions, it can be scheduled for execution. 'OutputProc' requires two NumberClass objects as inputs. Since there is no data object in the cell at this time, The scheduling conditions are not met, only 'InputProc' is executed for the first scheduling.
'InputProc' will input a data from the keyboard, convert it into a digital object, and put it into the Cell. For the next round of scheduling, at this time 'OutputProc' still does not meet the scheduling conditions, and can only execute 'InputProc' again to enter a new digital object.
There are two digital objects in Cell. 'OutputProc' can be scheduled for execution. 'OutputProc' calculates the sum of the two numbers, prints it to the screen, and then calls the Cell.Finish() function to end execution and exit.
Points of Interest
By defining data object types and process object types, and adding parameters to support scheduling, a data-driven process scheduling method can be implemented. In this programming method, the process object is different from the processes (functions) currently supported by various programming languages. A process object is an object that can be scheduled and assigned, and is no longer a fixed logical sequence in the execution code. This method has great flexibility, constructivity and sharing.
- Flexibility. If the data object needs some processing at any time, app can put the data object and the process object together to get the processing result.
- Constructivity, according to the input data object and output data object types, one or more process sequences can be obtained for the expected output data type. Similar to automatic programming
- Shareability, which is not reflected in the above examples. Both process objects and data objects can be stored as strings in JSON format, which can be restored and executed on other computing units.
Each process object and data object has a unique Tag, which can be used as a Key to map objects to nodes in the graph network or database. The construction of the process chain can be guided by the graph network's rule system. At any time, cells can be created to schedule data and process object execution.
History
- 23rd December, 2019: Initial version

