Floating-Point Dissector is available for download at GitHub.
Table of Contents
The IEEE 754 standard for floating-point format has been ubiquitous in hardware and software since established in 1985. Programmers has been using floating-point indiscriminately for real-number calculations. However, not many can claim to understand floating-point format and its properties, so more than a few misunderstandings has arisen. In this new year and new decade, I throw down the gauntlet as a challenge to myself to write a concise and easy-to-digest guide to explain floating-point once and for all. Common pitfalls shall be covered.
Floating-Point Dissector (with C++ and C# version) is written for programmers to examine floating-point bits after setting its value. Only class to check single(32-bit) and double(64-bit) precision are written for. Main reason is half(16-bit), long double(80-bit) and quad(128-bit) precision are not directly supported on Microsoft platform. Code for single and double precision dissector are identical, their only difference are the constants defined at the top of each class. C++ experts should see this code ripe for template and type traits. But I prefer to keep things simple as there are only 2 class for single and double. See the usage of C# code below on how to view the single precision of value 1 with the Display() method. C++ code is not shown because it is similar.
FloatDissector f = new FloatDissector(1.0f);
f.Display();
The output from Display() is shown below. Adjusted Exponent is the true value. Adjusted Exponent = Raw Exponent - Exponent Bias. Exponent Bias in single precision case is 127. More on this later when we get to the floating-point format section.
Sign:Positive, Adjusted Exponent:0, Raw Exponent:01111111, Mantissa:00000000000000000000000, Float Point Value:1
There are also methods to set Not-a-Number(NaN), Infinity(INF). There are 2 ways to set a NaN. The first way is to pluck the NaN from double type and give it to constructor. The second way is the DoubleDissector.SetNaN() method whose first parameter is the sign bit and the second one is mantissa which can be any value but shall be greater than zero beause a zero mantissa does not constitute a NaN. This indirectly implied there are more than 1 NaN value.
DoubleDissector d = new DoubleDissector(double.NaN);
d.SetNaN(DoubleDissector.Sign.Positive, 2);
Console.WriteLine("IsNaN:{0}", d.IsNaN());
Console.WriteLine("IsZero:{0}", d.IsZero());
Console.WriteLine("IsInfinity:{0}", d.IsInfinity());
Console.WriteLine("IsPositiveInfinity:{0}", d.IsPositiveInfinity());
Console.WriteLine("IsNegativeInfinity:{0}", d.IsNegativeInfinity());
Console.WriteLine("IsNaN:{0}", double.IsNaN(d.GetFloatPoint()));
After the end of the guide, reader shall be confident of implementing his own dissector.
It is a common knowledge among programmers that floating-point format is unable to represent transcendental numbers like PI and E whose fractional part continues on indefinitely. It is not unusual to see a very high precision PI literal is defined in C/C++ code snippets whose the original poster take a leap of faith that the compiler try its best possible effort to quantize into IEEE 754 format and do rounding when needed. Taking 32-bit float as an example, the intention goes as planned (See diagram below).

Surprise pop up for E. As it turns out, there are finite bits in a floating-point to perform quantization from a floating-point literal. Reality sets in when a simple number like 0.1 cannot be represented in single precision perfectly as well.
float a = 0.1f;
Console.WriteLine("a: {0:G9}", a);
Output is as follows.
a: 0.100000001
Mathematical identities (associative, commutative and distributive) do not hold.
Associative rule does not apply.
x + (y + z) != (x + y) + z
Commutative rule does not apply.
x * y != y * x
Distributive rule does not apply.
x * y - x * z != x(y - z)
In fact with floating-point arithmetic, the order of computation matters and the result can change on every run when order changes. Programmer can be tripped by this if he rely on your result to be consistent. During C++17 standardization, the parallelized version of std::accumulate() was given a new name: std::reduce() so as to let people know this parallelized function can return different result.
Division and multiplication cannot be interchanged. Common misconception claimed division is more accurate than multiplication. This is not true. These 2 operations could yield slighly different results.
x / 10.0 != x * 0.1
Floating-point conversion to integer can be done with a int cast. The caveat is the cast actually truncate it towards zero which may not be desired.
float f = 2.9998f;
int num = (int)(f);
To fix this problem, add 0.5 before casting.
float f = 2.9998f;
int num = (int)(f + 0.5f);
To cater for negative value,
if(f < 0.0f)
num = (int)(f - 0.5f);
else
num = (int)(f + 0.5f);
A better solution for C# is to use the static Math.Round method.
int a = (int)Math.Round(4.5555);
Math.Round is very convenient to use. But it has to be noted that rounding follows IEEE Standard 754, section 4 standard. This means that if the number being rounded is halfway between two numbers, the Round operation shall always round to the even number.
int x = (int)Math.Round(1.5);
int y = (int)Math.Round(2.5);
For C++ 11, std::round and std::rint are available for rounding. std::rint operates according to the rounding rules set by calls to std::fesetround. If the current rounding mode is...
FE_DOWNWARD, then std::rint is equivalent to std::floor.FE_UPWARD, then std::rint is equivalent to std::ceil.FE_TOWARDZERO, then std::rint is equivalent to std::trunc.FE_TONEAREST, then std::rint differs from std::round in that halfway cases are rounded to even rather than away from zero.
C++ equivalent of above C# code is below, using std::rint.
int x = (int)std::rint(1.5); int y = (int)std::rint(2.5);
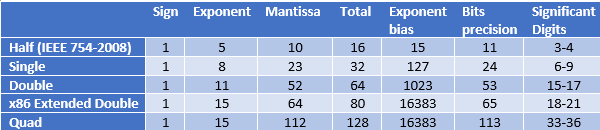
In this guide, we focus on single-precision (32-bit) float. Everything covered, applies to other precision float where information can easily adjust with the table found at the end of this section.
A single-precision format has one sign bit, 8-bit exponent and 23-bit mantissa. The value is negative when the sign bit is set. To get the true exponent, subtract exponent bias(127) from the raw exponent. In the raw exponent, 0(all zeroes) and 255(all ones) are reserved, valid range comprises of 1 to 254. The mantissa for normalized number(as opposed) has a hidden bit which is not stored. So we could infer mantissa has in fact 24-bits of precision. How do we get zero when hidden bit is always 1? Zero is a special number when both the raw exponent and mantissa are zero.

This is the formula for converting the components into a floating-point value.
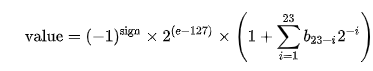
Let's see what the dissector display for the exponent of 0.25, 0.5 and 1.0. Do note that hidden mantissa bit is on.
FloatDissector f = new FloatDissector(0.25f);
f.Display();
f.SetFloatPoint(0.5f);
f.Display();
f.SetFloatPoint(1.0f);
f.Display();
Output of the above code is shown below. Take note the exponent is in radix 2, not 10: M * 2e. So 1 * 2-2 would give 0.25. And 1 * 2-1 = 0.5 and 1 * 20 = 1.
Sign:Positive, Adjusted Exponent:-2, Raw Exponent:01111101, Mantissa:00000000000000000000000, Float Point Value:0.25
Sign:Positive, Adjusted Exponent:-1, Raw Exponent:01111110, Mantissa:00000000000000000000000, Float Point Value:0.5
Sign:Positive, Adjusted Exponent:0, Raw Exponent:01111111, Mantissa:00000000000000000000000, Float Point Value:1
As the number gets larger as shown, mantissa precision remains constant(223=8,388,608), we can say the precision actually becomes lesser. The number of floats from 0.0 ...
- ...to 0.1 =
1,036,831,949 - ...to 0.2 =
8,388,608 - ...to 0.4 =
8,388,608 - ...to 0.8 =
8,388,608 - ...to 1.6 =
8,388,608 - ...to 3.2 =
8,388,608
Between 0.0 and 0.1, there is more floats because subnormal is included with normal number. Subnormal are small numbers very close to zero.
Now let's play around mantissa bits to see how it works. As we proceed from MSB to LSB, each bit value is halved from its preceding bit value. If the MSB or hidden bit has the value of 1, its next bit is 1/2 and the 3rd bit is 1/4. If we set those 2 bits to one, we should get 1 + 0.5 + 0.25 = 1.75

FloatDissector f = new FloatDissector(1.0f);
f.SetMantissa(0x3 << 21);
f.Display();
The output is as we expected.
Sign:Positive, Adjusted Exponent:0, Raw Exponent:01111111, Mantissa:11000000000000000000000, Float Point Value:1.75
However, the hidden bit value is not always 1. It depends on the exponent. When the exponent is -1, it is 1*2-1=0.5!

If we set those 2 bits again, we should get 0.5 + 0.25 + 0.125 = 0.875
FloatDissector f = new FloatDissector(0.5f);
f.SetMantissa(0x3 << 21);
f.Display();
We are right again!
Sign:Positive, Adjusted Exponent:-1, Raw Exponent:01111110, Mantissa:11000000000000000000000, Float Point Value:0.875
The size of fields in each floating-point type is shown together with their significant digit precision.
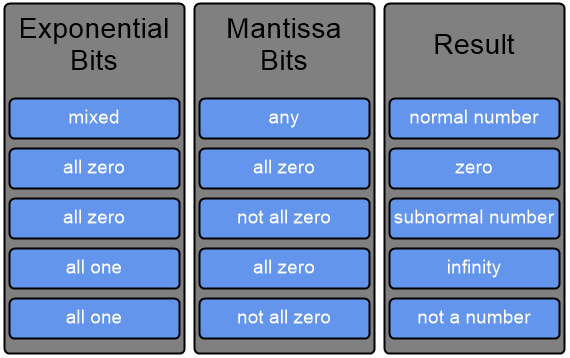
IEEE 754 floating-point has 2 distinct zero: positive and negative. A positive zero is indicated by all the bits, including the sign bit, unset. That is why, in a structure with Plain Old Data (POD) types of integer and float type, it is possible, using memset() to quickly zero-initialize every member.
Subnormal, also known as denormalized number, are IEEE 754 mechanism to deal with very small numbers close to zero. Subnormal are indicated by all zero exponent and non-zero mantissa. With normal number, the mantissa has an implied leading one bit. But with subnormal, the leading 1-bit is not assumed, so subnormal has 1-bit less mantissa precision now (23-bit precision). With the raw exponent set to zero, the true (adjusted) exponent is 0 - 127 which yields -127. The smallest positive subnormal number is when the mantissa is all zeroes except for the Least Significant Bit(LSB), which is approximate to 1.4012984643 × 10−45 while the smallest positive normal number is approximately 1.1754943508 × 10−38.
If you search on Stack Overflow for questions on subnormal, you will no doubt come across this thread which shows subnormal calculations are much slower on Intel architecture processor because normalized number arithmetic is implemented in hardware while subnormal one has to take the slow microcode path. Unless you are dealing with very small, close to zero numbers, you can safely ignore this performance issue. If you are in the other camp, using C++ and SIMD, you have 2 options.
- Use the
-ffast-math compiler flag to sacrifice correctness to gain more FP performance. Not recommended. - Set CPU flags (Stop gap measure)
- Flush-to-zero : treat subnormal outputs as 0
- Denormals-to-zero : treat subnormal inputs as 0
There are 2 ways to do the 2nd option. First one is to set control and status register(CSR) via the Intel Intrinsic, _mm_setcsr() but this method requires you to remember the hexadecimal number(0x8040) to or the bits with existing CSR.
_mm_setcsr(_mm_getcsr() | 0x8040);
A better method is to call _MM_SET_FLUSH_ZERO_MODE and _MM_SET_DENORMALS_ZERO_MODE() with _MM_FLUSH_ZERO_ON and _MM_DENORMALS_ZERO_ON respectively.
_MM_SET_FLUSH_ZERO_MODE(_MM_FLUSH_ZERO_ON);
_MM_SET_DENORMALS_ZERO_MODE(_MM_DENORMALS_ZERO_ON);
What about x87 Floating-Point Unit(FPU)? Unfortunately, there is no x87 FPU functionality to treat subnormal as zero.
1/0
When any greater than zero number is divided by zero, you get infinity, not divide-by-zero exception. That exception is for integer divide-by-zero. Infinity is indicated all ones exponent and all zeroes mantissa. As with zero number, you have both positive and negative infinity.
You can assign Infinity by .NET's Single.PositiveInfinity or Single.NegativeInfinity field and Double.PositiveInfinity or Double.NegativeInfinity field in C# or std::numeric_limits<t>::infinity() defined in limits header in C++11 or using dissector's SetInfinity() method.
To test for infinity, if you are using C#, call Single.IsInfinity() and Double.IsInfinity(). If you are on C++11, call std::isinf().
Rules for infinity correspond to common sense. See below.
6 + infinity = infinity
6 / infinity = 0
0/0
Not a Number(NaN) is what you get when you divide a zero by zero or do a square root on -1. There are 2 types of NaN: quiet and signalling but we are not covering them here. You can assign NaN by .NET's Single.NaN and Double.NaN field in C# or std::nan() defined in cmath header in C++11 or using dissector's SetNaN() method.
Never test for NaN by testing for equality with another NaN. When you compare 2 NaN, the equality test shall return false, even when the 2 NaN in question are exactly the same in binary. If you are using C#, call Single.IsNaN() and Double.IsNaN(). If you are on C++11, call std::isnan().
Rules for NaN also correspond to common sense. See below.
NaN + anything = NaN
NaN * anything = NaN
The chart summaries the corresponding exponent and mantissa that constitute the floating-point values (like Subnormal, NaN and Infinity).
C# as a language does not expose floating-point exception. Do not even think of circumventing this limitation with P/Invoke to change the FPU status because the .NET Framework and 3rd party libraries rely on the FPU in certain state.
On Microsoft C++, it is possible to catch floating-point exception via Structured Exception Handling(SEH) after enabling the FP exception through the _controlfp_s. By default, all FP exceptions are disabled. SEH style exception can be translated to C++ typed exceptions through _set_se_translator. For those who shun proprietary technology and write cross-platform Standard C++ code, read on. As noted on this cppreference page on C++11 floating-point environment. The floating-point exceptions are not related to the C++ exceptions. When a floating-point operation raises a floating-point exception, the status of the floating-point environment changes, which can be tested with std::fetestexcept, but the execution of a C++ program on most implementations continues uninterrupted.
Never test floating-point for equality. Guess the output below!
float a = 1.3f;
float b = 1.4f;
float total = 2.7f;
float sum = a + b;
if (sum == total)
Console.WriteLine("Same");
else
{
Console.WriteLine("Different");
Console.WriteLine("{0:G9} != {1:G9}", sum, total);
}
Console.WriteLine("a: {0:G9}", a);
Console.WriteLine("b: {0:G9}", b);
The reason they are not equal because single precision cannot represent 1.3 and 1.4 perfectly. Although changing the type to double precision solves the problem in this case, all floating-point type inherently has this imprecise problem therefore they should not be used as keys in a dictionary (or a std::map in C++ case). The only time equality test poses no problem are the numbers involved, are not result of any computation but directly assignment of literal constant.
Different
2.69999981 != 2.70000005
a: 1.29999995
b: 1.39999998
Always test floating-point for nearness. Choose an epsilon value a bit larger than your largest error. There is no one-size-fits-all epsilon to use for all cases. For example, the epsilon is set to 0.0000001 and the 2 numbers are actually 0.000000008 and 0.000000005, the test will always pass, so clearly the chosen epsilon is wrong! Nearness test do not have the transitive property as equality test. For instance, a==b and b==c, does not necessarily mean a==c. See the example below.
float epsilon = 0.001f;
float a = 1.5000f;
float b = 1.5007f;
float c = 1.5014f;
if (Math.Abs(a - b) < epsilon)
Console.WriteLine("a==b");
else
Console.WriteLine("a!=b");
if (Math.Abs(b - c) < epsilon)
Console.WriteLine("b==c");
else
Console.WriteLine("b!=c");
if (Math.Abs(a - c) < epsilon)
Console.WriteLine("a==c");
else
Console.WriteLine("a!=c");
The output is as follows.
a==b
b==c
a!=c
For C++, do not use std::numeric_limits<t>::epsilon. For C#, do not use Single.Epsilon and Double.Epsilon. Why? Because these epsilon defined the smallest positive value but most of your time, your largest error value is larger than the smallest value, so your nearness test would fail most of time with those standard epsilon.
Whenever possible, turn == into >= or <= comparison, that would be more ideal.
Fixed-Point
When the exponent is fixed at certain negative number, there is no need to store it. The fractional part or decimal point is fixed, thus the name: fixed-point as opposed to floating-point. In the same application, it is not unusual to implement different fixed-point types to accommodate precision requirement of certain type of computation. In such application, conversion of floating-point result, from trigonometry or arithmetic function such as sqrt(), to fixed-point is a common practice, as it is not feasible to reimplement all the floating-point math in the standard library in fixed-point. Fixed-point is not made for calculations dealing very large quantity like total number of particles in the universe or very small numbers involving quantum mechanics due to its limited precision range.

Decimal
In C#, Decimal type in .NET Base Class Library (BCL) can represent numbers in radix 10 perfectly (due to its exponent is in radix 10), is most suitable to store currency for financial calculations without loss of precision. However, it must be noted that calculations with decimal are orders of magnitude slower than floating-point because it is 128-bit type and no hardware support.
cpp_float
In the C++ world, Boost is de facto, peer-reviewed, high quality library to go for whenever a C++ task/work needs to get done. cpp_float featured in Boost.Multiprecision library can be used for computations requiring precision exceeding that of standard built-in types such as float, double and long double. For extended-precision calculations, Boost.Multiprecision supplies a template data type called cpp_dec_float. The number of decimal digits of precision is fixed at compile-time via template parameter.
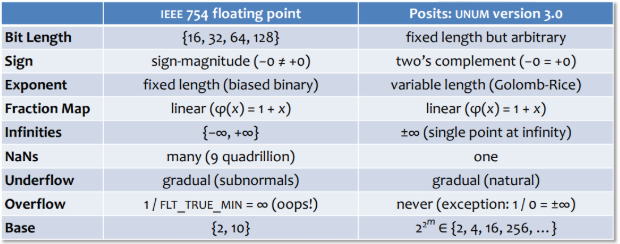
Posits
A new approach to floating-point called posits delivering better performance and accuracy, while doing it with fewer bits. Posit could cut the half the number of bits required, leaving more cache and memory for other information. In posit, there is only one zero and NaN value, leaving no ambiguity. And it is meant to be a drop-in replacement for IEEE floating-point with no modification needed to the code. As of the writing time, there is no commodity hardware implementation of posit but it could change in near future. It is an interesting developement to keep our eyes on.
IEEE 754 and Posits Compared