Introduction
This month, I had hoped to release a Unicode enabled version of Rolex based on a new finite automata engine I am working on.
However, the engine is show-stopped until I get a book I need in order to finish the implementation.
That said, I still needed Rolex to be Unicode enabled. I had been using GPLEX for this but the input and output it deals in is clunky and undesirable. The input spec looks like a LEX document and the output can span multiple files and had a programming interface like LEX, complete with yylex() method. Ugh.
What I've done is created an interim release of Rolex based on a deconstructed and somewhat retooled version of the GPLEX 1.2 engine. The program was modified to take a Rolex lexer specification and emit a tokenizer class implementing IEnumerable<Token>.
Limitations
This interim release will only generate lexers in C#. Other .NET language support will return in a future release of Rolex.
Copyright
For those of you unfamiliar with it, GPLEX, aka the Garden Points Lexer is Copyright (c) 2009, Queensland University of Technology. Full copyright is included with the source. I did not write GPLEX. I modified it.
Conceptualizing this Mess
The Rolex Command Line Interface
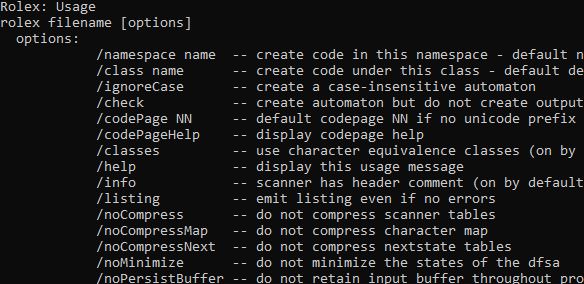
Using Rolex is relatively straightforward but there are a lot of options, most of which you will never need. Here is the usage screen:
Rolex: Usage
rolex filename [options]
options:
/namespace name -- create code in this namespace - default none
/class name -- create code under this class - default derived from <output>
/ignoreCase -- create a case-insensitive automaton
/check -- create automaton but do not create output file
/codePage NN -- default codepage NN if no unicode prefix (BOM)
/codePageHelp -- display codepage help
/classes -- use character equivalence classes (on by default if unicode)
/help -- display this usage message
/info -- scanner has header comment (on by default)
/listing -- emit listing even if no errors
/noCompress -- do not compress scanner tables
/noCompressMap -- do not compress character map
/noCompressNext -- do not compress nextstate tables
/noMinimize -- do not minimize the states of the dfsa
/noPersistBuffer -- do not retain input buffer throughout processing
/noShared -- do not generated shared code - useful for
2nd scanner in same project
/noUnicode -- do not generate a unicode enabled scanner
/output path -- send output to filename "path"
/output - -- send output to stdout
/parseOnly -- syntax check only, do not create automaton
/stack -- enable built-in stacking of start states
/squeeze -- sacrifice speed for small size
/summary -- emit statistics to list file
/verbose -- chatter on about progress
/version -- give version information for Rolex
I've listed the more important ones below:
filename (required) - indicates the lexer specification file to generate from. These are described belowoutput - indicates the output code file to generate to or - for stdout.class - indicates the name of the generated tokenizer class. By default, it is derived from output.namespace - indicates the namespace to render the code under. Defaults to no namespace.ignoreCase - indicates that the entire specification should be treated as case insensitivenoShared - indicates that the shared dependency code should not be generated. By default, Rolex generates all dependency code as part of the tokenizer output file. If you're generating multiple tokenizers, you only want one copy of the shared code, so simply specify noShared for the 2nd tokenizer and onward
The Rolex Lexer Specification
The lexer specification was designed primarily to be machine generated by other tools, like Parsley However, it's easy enough to use by hand if you aren't afraid of regular expressions.
It is a line based format where each line is formed similar to the one that follows:
ident<id=1>= '[A-Z_a-z][0-9A-Z_a-z]*'
or more generally:
identifier [ "<" attributes ">" ] "=" ( "'" regexp "'" | "\"" literal "\"" )
Each attribute is an identifier followed optionally by = and a JSON style string, boolean, integer or other value. If the value isn't specified, it's true meaning any attribute without a value specified explicitly is set to true. Note how literal expressions are in double quotes and regular expressions are in single quotes.
There are a few available attributes, listed as follows:
id - Indicates the non-negative integer id associated with this symbol- const - Indicates the name of the constant generated for this symbol
hidden - Indicates that this symbol should be passed over by the lexer and not reportedblockEnd - Indicates a multi-character ending condition for the specified symbol. When encountered, the lexer will continue to read until the blockEnd value is found, consuming it. This is useful for expressions with multiple character ending conditions like C block comments, HTML/SGML comments and XML CDATA sections.
Rules can be somewhat ambiguous. If they are, the first rule in the specification is the rule that is matched, yielding a set of rules prioritized by document order.
The regular expression language supports basic non-backtracking constructs and common character classes, as well as [:IsLetter:]/[:IsLetterOrDigit:]/[:IsWhiteSpace:]/etc. that map to their .NET counterparts. Make sure to escape single quotes since they are used in Rolex to delimit expressions.
Coding this Mess
The Generated Code API
Rolex exposes generated tokenizers using a simple API. Each tokenizer is a class which each symbol an integer constant on that class. The tokenizer when constructed, takes an IEnumerator<char> which is typically a string but can be a char[] array or some custom source you implement. It can also be a TextReader, or a Stream. The Tokenizer can be created using the static Open() method which takes a filename, and automatically manages opening and closing the file as needed. This is the recommended way to read from a file. The tokenizer class supports foreach enumeration over the tokens, whose information is returned using the Token struct. The Token struct meanwhile, returns line, column, position, symbol and capture information in Line, Column, Position, SymbolId, and Value respectively. Note that column and position are not the same thing! Your position is essentially the index into your input. If you passed a string into the tokenizer, the Token.Position, when cast to an int would be your absolute index into the string. The Column property on the other hand, is 1 based, like Line and indicates the position within the input device layout. This includes accounting for tabs, newlines, and carriage returns.
Let's put what we've covered together to get some lexing going on. First, let's make a spec file, Example.rl:
id='[A-Z_a-z][0-9A-Z_a-z]*'
int='0|\-?[1-9][0-9]*'
space<hidden>='[\r\n\t\v\f ]'
lineComment<hidden>= '\/\/[^\n]*'
blockComment<hidden,blockEnd="*/">= "/*"
Above, we've definied id and int, and the rest are hidden whitespace and comments.
Now, we need to cajole some code for it out of Rolex:
Rolex.exe Example.rl /output ExampleTokenizer.cs /namespace RolexDemo
After including ExampleTokenizer.cs in our project, we can use it like this:
var input = "foo bar/* foobar */ bar 123 baz -345 fubar 1foo *#( 0";
var tokenizer = new ExampleTokenizer(input);
foreach(var tok in tokenizer)
{
Console.WriteLine("{0}: {1} at column {2}", tok.SymbolId, tok.Value,tok.Column);
}
Which will spit this to the console:
0: foo at column 1
0: bar at column 4
0: bar at column 20
1: 123 at column 24
0: baz at column 28
1: -345 at column 32
0: fubar at column 37
1: 1 at column 43
0: foo at column 44
-1: * at column 48
-1: # at column 49
-1: ( at column 50
1: 0 at column 52
The underlying algorithm that makes it work is based on a fast DFA algorithm, like standard Rolex is. All you need to do is worry about enumeration and let the tokenizer handle everything else.
Visual Studio Integration
Rolex can integrate with Visual Studio as a Visual Studio Custom Tool by installing RolexDevStudio.vsix.
Simply navigate to your Rolex lexer spec file and go to Properties|Custom Tool and type Rolex, and the generation process will begin.
You can set or override command line options in the lexer spec by using the @options directive which takes a comma separated list of values in attribute format sans < and >. This can be useful for specifying alternate class files. Note that specifying an alternate output file option in the lexer spec will make the custom tool behave badly. It's best not to specify it, and just let the custom tool do its thing. The @options directive must appear before any rules.
Points of Interest
Much of this code is a monumental hack of GPLEX, where I've torn apart parts of the AST, and the parser and modified them, as well as the code generator. I've left much of the original functionality, including the original parser intact if I ever want to make Rolex accept GPLEX lexer specs, It's not exposed to the command line right now, but it's in there for the most part. There's some stale code in here, but it's mostly because I am still developing against this codebase and I may need it. I'm keeping my options open with this codebase until I can get my rewrite shored up.
History
- 31st January, 2020 - Initial submission

