The GZIP example design takes advantage of the massive spatial parallelism available in FPGAs to accelerate the LZ77 compression algorithm by parallelizing memory accesses, dictionary searches, and matching. Since the design is implemented using oneAPI, the code can target any compute technology, but we specifically optimize for FPGAs. The example produces GZIP-compatible compressed data files so that developers can use standard software tools to decompress the compressed files produced by this design.
Field programmable gate arrays (FPGAs) provide a flexible hardware platform that can achieve high performance on a large variety of workloads. In this article, we’ll discuss the Intel GZIP example design, implemented with oneAPI, and how it can help make FPGAs more accessible. (For more on oneAPI, see this issue's feature article, Heterogeneous Programming Using oneAPI.)
The example design implements DEFLATE, a lossless data compression algorithm essential to many storage and networking applications. The example is written in SYCL and compiled using the oneAPI Data Parallel C++ (DPC++) Compiler, demonstrating a significant acceleration in compression times with compelling compression ratio.
How FPGAs Work
FPGAs are reconfigurable devices consisting of many low-level compute and storage elements (e.g., adders/multipliers, logic operations, memories) structured as a 2D array and connected by reconfigurable routing. These elements can form complex compute pipelines and specialized on-chip memory systems. In contrast to traditional architectures, which are designed to execute generic code, FPGAs can be reconfigured to implement custom architectures that boost the performance of a target application. For example, FPGAs can implement specialized compute pipelines that can execute an entire loop iteration every clock cycle. FPGAs fit well in an acceleration model, with off-chip attached memory (e.g., DDR4) and connectivity to a host CPU (e.g., through PCIe).
DPC++ Compilation to FPGAs
The FPGA backend of the DPC++ Compiler produces a bitstream that reconfigures the FPGA for the given code. Each kernel in the SYCL program is implemented using a subset of the FPGA resources. All implemented kernels can execute concurrently.
Within a kernel, each loop body is translated to a deep and specialized pipeline that contains all the functional units required to process an entire loop iteration. Conditional statements are refactored as predicated execution. Traversing the pipeline once executes an entire loop iteration.
The compiler identifies instructions that can be executed in parallel, and places them in the same pipeline stages, so that they execute in parallel on arbitrarily many functional units. Further, it optimizes the pipeline by ensuring that data can be forwarded, so that subsequent loop iterations can be issued as soon as possible (often in consecutive cycles), without data hazards (Figure 1).
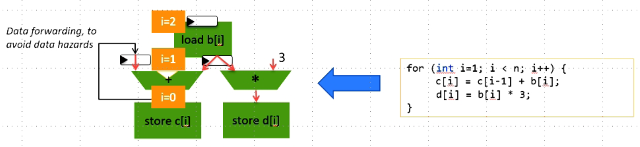
1 - Pipeline generated user code
Compiling for the FPGA typically takes several hours. To accelerate the development cycle, the FPGA backend is accompanied by an emulator, static performance reports, and a dynamic profiler to guide optimization decisions. Emulation and static report generation take minutes instead of hours, vastly improving the productivity of FPGA application development compared to traditional RTL development flows.
The oneAPI Advantage
The GZIP design takes full advantage of key oneAPI programming features such as single-source design and multiple accelerators, as well as heterogeneous computing where the accelerator runs the hotspot code and the CPU is processing the non-hotspot code. Since the design is written using oneAPI, this enables anyone who knows C++ to write an algorithm suitable for compilation to FPGAs, focusing mainly on the algorithmic details and leaving the hardware translation to the compiler backend. Since the algorithm is expressed in C++, it can be easily tested for correct functionality. Hardware performance can be anticipated by examining reports before committing to a hardware compilation.
The Example Design
The GZIP design’s architecture follows DEFLATE’s dataflow. We create three kernels to do the work:
- LZ77
- Huffman
- CRC
Our first kernel computes LZ77 data, searching and eliminating duplicate sequences from the file. The idea is illustrated in Figure 2.

2 - Example of LZ77 compression
A duplicated sequence is replaced with a relative reference to the previous occurrence. Less storage is required to encode the reference than the original text, reducing the file size.
To find matches, we need to remember all the sequences we’ve seen and pick the best candidate match. The sequence is replaced, and the matching process continues from the end of the current match―or, if we didn’t find a good match, at the next symbol. This is harder than it sounds.
Our goal will be to process 16 bytes on every FPGA clock cycle. So, in one clock cycle, we need to:
- Look in our history for the best match at each of 16 starting points
- Pick the best match (or matches, if there are several that don’t overlap)
- Write the result to our output
- Store the string we just read back into the dictionary
It’s not obvious that this work can be done in parallel, since matches can’t overlap. We can’t pick a match starting at a given byte until we know that no earlier match already covers it. (We’ll cover this in detail in the next section.)
The second kernel applies Huffman encoding to the data, generating the final compressed result. During this step, all symbols and references are replaced with a variable bitwidth encoding which provides codes with fewer bits for the most frequent symbols, further reducing the file size. It’s easier to see how this step can be parallelized: we can have 16 (or more) independent units of hardware, each determining the Huffman code for a given symbol. There’s still a problem, though. Since the output has variable length, we need to eventually write each output to the right location in the output stream―which means we need to know how large all the previous outputs were. Also, Huffman codes are not byte-aligned, so we’ll need to do a lot of bit-level manipulation. Fundamentally, though, this is a less complicated problem than LZ77, and we won’t go into more detail here.
Finally, a third kernel computes CRC32 on the input data. This kernel is independent of the other two and can operate in parallel. It’s also relatively simple to implement on the FPGA, so we won’t discuss it in detail here.
FPGA-Optimized LZ77 Implementation
To capture the sequential nature of the data processing, the LZ77 encoder is described as a single task with a single main loop. That is, the code describes a single thread of execution, iterating symbol-bysymbol on the entire file. A set of dictionaries is created to store previously seen sequences in the datafile. These dictionaries are indexed through a hash of the data they store, similar to a hash map. However, for performance reasons, a more recent (colliding) entry overwrites dictionary data corresponding to an earlier entry with the same hash key. The dictionaries are updated by writing the newly seen input to all the dictionaries. To reduce the impact of collisions in the dictionaries, we separate the previously seen sequences in multiple disjoint sets.
Why do we need more than one dictionary? Recall that we want to process 16 bytes per cycle. This means storing 16 strings (one starting at each byte) to the dictionary and doing 16 hash lookups on every clock cycle. Each FPGA memory block only has two ports. To allow all these concurrent accesses, we create 16 separate memory systems, each storing strings at a different position. We now have our history spread across 16 dictionaries, so each of our 16 hash lookups now needs to be done in 16 different dictionaries― for a total of 256 lookups. It seems like we’ve just made the problem worse.
We can solve this by building 16 copies of each of our dictionaries, for a total of 256 dictionaries. All of these dictionaries use a large fraction of the FPGA’s on-chip memory, but we've achieved our goal of doing 16 hash lookups and writes on every clock cycle. Figure 3 shows an example of the dictionary structure we would need if we only wanted to process four bytes per clock cycle. (Incidentally, the FPGA area devoted to dictionaries is the main limitation preventing us from processing more than 16 bytes per cycle.)
3 - Dictionary replication for four-byte parallel access
Expressing the parallel behavior may sound tricky. But, in fact, the compiler identifies the data parallelism between the lookups on its own. That is, the code will result in specialized FPGA logic capable of executing all the dictionary lookups concurrently. In the code, VEC is the number of bytes being processed per cycle, and LEN is the size of the string. In the example design, both are set to 16. We’ve used template metaprogramming (the unroller) to replicate the code in the inner function for all i and j. The data from all the lookups is aggregated in a reduction-like operation as part of the same pipeline.
Our dictionaries solve one problem, but we have a lot more processing to do if we want to complete a full loop iteration on each clock cycle. Luckily, we don’t need to. The FPGA compiler will automatically pipeline the datapath. So after iteration 0 of the loop finishes reading from the dictionary, iteration 1 can start, while iteration 0 starts on picking the best match. The match selection can be staged across several cycles, with a different iteration of the loop operating at each stage.
When generating the output, one final challenge is how to correctly account for the impact of a match on subsequent matches. Once a match is identified, overlapping matches must be disregarded. In our single_task code representation, this manifests as a loop-carried variable that needs to be computed before subsequent iterations of the loop can proceed. If the computation is too complex, it may limit the clock speed of the FPGA, or limit our ability to complete a loop iteration on every clock cycle.
Because we target an FPGA, we can customize the hardware to optimize the handling of this dependency. We simplify the data hazard by minimizing the amount of computation that depends on it. For example, we choose to do the hash lookups speculatively, determining all the possible matches, even if the lookups are related to overlapped matches. We simply prune the overlapping matches later on. The FPGA backend optimizes the required forwarding logic, fully avoiding the data hazard. Figure 4 demonstrates the pruning of speculative matches.
4 - Pruning speculative matches, accounting for matches identified in previous loop iterations, overlapped matches in the current loop iteration, and poor quality matches
Task-Level Parallelism
To compress a file, the three processing kernels are asynchronously submitted by the host CPU. They can run concurrently in the FPGA hardware. They operate at slightly different rates, with CRC being faster. LZ77 produces data needed by the Huffman kernel. To avoid an additional delay, and to avoid transferring data through off-chip memory, we use kernel-to-kernel communication pipes, a proposed Intel extension of the SYCL language. This extension allows different kernels to exchange data, in sequence, without writing to off-chip memory, as shown in Figure 5.
5 - Task parallelism in GZIP
Building the GZIP Design
You can download and run the GZIP design from the oneAPI code samples. You may target the FPGA emulation to verify correctness and functional behavior. Attempting to compress, for example, /bin/emacs-24.3 will result in:
The next step is to generate static optimization reports for the design. When optimizing, you should inspect these reports to understand the structure of the specialized pipelines being created for your kernels. You can find the reports at gzip_report.prj/reports/report.html.make reports.
Finally, you can compile and run the design on FPGA hardware. The optimized compilation will take a few hours.
Performance
Here’s how we invoke GZIP:
To evaluate performance, the application will call the compression function repeatedly and report on the overall execution time and throughput. Here’s some sample output:
Making FPGAs More Accessible
With oneAPI, FPGAs are more accessible than ever. Spatial architectures open great acceleration opportunities, often in domains that are not embarrassingly parallel. And it’s all at your fingertips with the DPC++ compiler and oneAPI.

