This post is about availability in the cloud and how to architect for resiliency around storage. It discusses a common scenario which is being able to write new files to blob storage and read from storage account while requiring it to be as resilient as possible.
I’ve been doing a lot of work around availability in the cloud and how to build applications that are architected for resiliency. And one of the common elements that comes up, is how do I architecture for resiliency around storage.
So the scenario is this, and it's a common one, I need to be able to write new files to blob storage, and read from my storage accounts, and need it to be as resilient as possible.
So let’s start with the SLA, so currently if you are running LRS storage, then your SLA is 99.9%, which from a resiliency perspective isn’t ideal for a lot of applications. But if I use RA-GRS, my SLA goes up to 99.99%.
Now, I want to be clear about storage SLAs, this SLA says that I will be able to read data from blob storage, and that it will be available 99.99% of the time using RA-GRS.
For those who are new to blob storage, let’s talk about the different types of storage available:
- Locally Redundant Storage (LRS): This means that the 3 copies of the data you put in blob storage are stored within the same zone.
- Zone Redundant Storage (ZRS): This means that the 3 copies of the data you put in blob storage, and stored across availability zones.
- Geo Redundant Storage (GRS): This means that the 3 copies of the data you put in blob storage, are stored across multiple regions, following Azure region pairings.
- Read Access Geo Redundant Storage (RA-GRS): This means that the 3 copies of the data you put in blob storage, are stored across multiple regions, following Azure region pairings. But in this case, you get a read access endpoint you can control.
So based on the above, the recommendation is that for the best availability you would use RA-GRS, which is a feature that is unique to Azure. RA-GRS enables you to have a secondary endpoint where you can get read-only access to the back up copies that are saved in the secondary region.
For more details, look here.
So based on that, you gain the fact that if your storage account is called:
storagexyz.blob.core.windows.net
Your secondary read-access endpoint would be:
storagexyz-secondary.blob.core.windows.net
So the next question is, “That’s great Kevin, but I need to be able to write and read”, and I have an architecture pattern I recommend for that. And it is this:
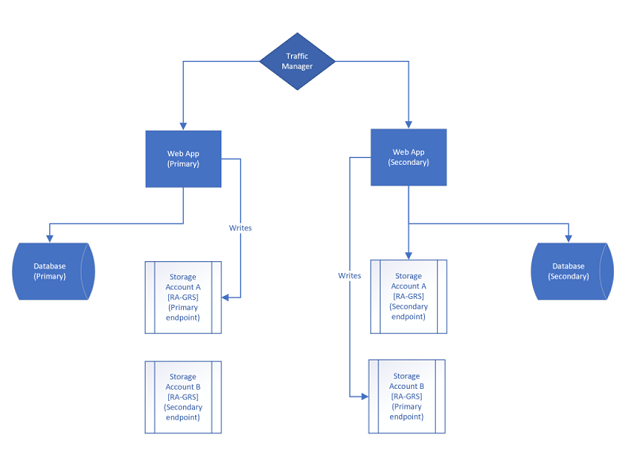
So the above architecture is oversimplified but focuses on the storage account configuration for higher availability. In the above architecture, we have a web application that is deployed behind traffic manager, with an instance in a primary region, and an instance in a secondary region.
Additionally, we have an Azure SQL database that is ego-replicated into a backup region.
Let’s say for the sake of argument, with the above:
- Region A => East US
- Region B => West US
But for storage, we do the following, Storage Account A, will be in East US, which means that it will automatically replicate to West US.
For Storage Account B, will be in West US, which means it replicates to East US.
So let’s look at the Region A side:
- New Blobs are written to Storage Account A
- Blobs are read based on database entries.
- Application tries to read from database identified blob storage, if it fails it uses the “-secondary” endpoint.
So for Region B side:
- New Blobs are written to Storage Account B
- Blobs are read based on database entries
- Application tries to read from database identified blob storage, if it fails it uses the “-secondary” endpoint.
So in our databases, I would recommend the following fields for every blob saved:
- Storage Account Name
- Container Name
- Blob Name
This allows for me to easily implement the “-secondary” when it is required.
So based on the above, let’s play out a series of events:
- We are writing blobs to Storage Account A. (1,2,3).
- There is a failure, we fail over to Region B.
- We start writing new blobs to Storage Account B. (4,5,6).
- If we want to read Blob 1, we do so through the “-secondary” endpoint from Storage Account A.
- The issue resolves.
- We read Blob 1-3 from Storage Account A (primary endpoint).
- If we read Blob 4-6, it would be from the “-secondary” endpoint of Storage Account B.
Now some would ask the question, “when do we migrate the blobs from B to A?” I would make the argument you don’t, at the end of the day, storage accounts cost nothing, and you would need to incur additional charges to move the data to the other account for no benefit. As long as you store each piece of data, you can always find the blobs so I don’t see a benefit from merging.

