Coordinating counting requests within a time window across a cluster can't be done in-memory, you need a backing store and this article walks through using Node.js and RavenDB to accomplish throttling client-side requests to an API so you don't exceed rate limits.
When working with external services, sometimes you need to ensure you don't call a particular API too often. In a distributed environment like a web farm, this makes things even more hairy. In this post, you will see how RavenDB can help you track requests using distributed counters and sliding time windows.
Introduction
Most applications today interact with external services through HTTP-based APIs. As a service provider hosting an API for public use, it's typical to implement "rate limiting" so that you protect your services from being overloaded by your users. Rate limiting works by tracking how many requests are sent within a set time period from a specific client.
As a client, this presents a challenge when you have a high-throughput application that needs to call such an API. How do you avoid hitting the rate limit and causing exceptions in your application? Furthermore, what if the API doesn't return any HTTP headers to allow you to track the request limit dynamically? This was the case recently with a service I was calling. I needed a solution to limit outgoing requests.
There are some existing solutions for throttling outgoing API requests in JavaScript using packages like limiter and bottleneck. Bottleneck is especially interesting because it supports clustering like we want! However, it uses Redis as the backing store and in my environment I use RavenDB so we'll be looking at how to achieve the same solution with RavenDB instead.
The reason this becomes more complex in a distributed environment is the need to count requests across clients. A "client" in this case means a process on a VM or container. For example, in a message queue architecture, it's typical to have multiple consumers of a message queue. Each consumer is an isolated process that may be spread out across multiple physical or virtual servers. If each consumer processes messages independently and can potentially send outgoing API requests, how can you collectively throttle outgoing HTTP requests?
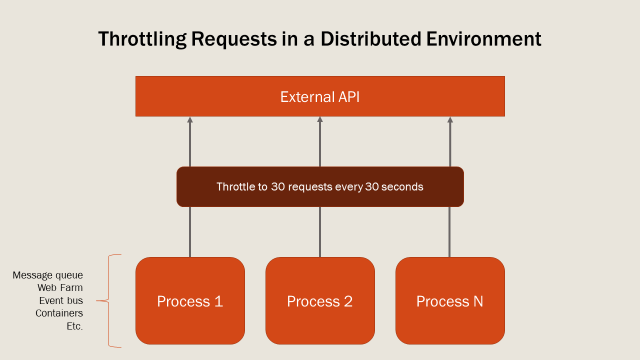
You may expect coordinating requests across multiple clients would involve complex bits of code to write and you'd be right! You need an orchestrator that can track requests and throttle them. This would normally involve multiple layers like a database and request middleware. The backing store could be Redis (which bottleneck uses), MongoDB, or any other technology.
There are many possible solutions to this problem and in this article, I'll show you how you can use RavenDB to implement throttling in less than 40 lines of code.
Curious how to throttle requests across a cluster in .NET? Check out my previous article covering the same topic using .NET Core.
Why RavenDB?
In case you aren't familiar with RavenDB, it is a cross-platform, high-performance, scalable NoSQL document database. At first glance, it may seem similar to MongoDB as both of them are document databases but dig a little deeper and you'll soon find that is where the similarities stop.
We will be taking advantage of some unique features of RavenDB well-suited for this problem: Counters and Document Expiration.
Counters are specifically designed for distributed scenarios, allowing high frequency updates that work reliably across a cluster. I discussed distributed counters briefly in my previous article, What's New in RavenDB 4.2.
Using counters will let us track outgoing requests across our client instances but we also need to track requests across a sliding time window. To accomplish that, we'll use another useful feature, Document Expiration. RavenDB will track the document expiration time and will automatically remove the document once it expires.
Since Counters are attached to documents, pairing these two features will allow us to track requests over a specific time window. If the counter exceeds the rate limit during that window, we can wait until RavenDB removes the document once it expires.
Creating a Sample Client
The code samples I will show are part of a Node.js console application. The code has a mock API it calls (external-api) and uses RavenDB to track requests for throttling.
The code for this article is available on GitHub. You will need an instance of RavenDB setup and if you're just starting out, I recommend creating a free instance using RavenDB Cloud. This will get you up and running within minutes!
The README for the sample explains how to set up the user secrets required and the steps to generate a client certificate used for authentication.
To add RavenDB to your Node application, you can install the ravendb npm package:
npm install ravendb --save
Creating a Request Client
In this demo, we will have a module that represents a client who is calling an external API. The module exports a function to send a request and is set up like so:
const db = require('./db');
const externalApi = require('./external-api');
module.exports = {
async sendRequest() {
await externalApi.fetch();
}
}
Using Documents to Track Rate Limits
Since counters are stored on documents, the way we can track API requests is by creating a special document that will hold any metadata around the API requests and allow us to get and update counters. We'll call this our "rate limit marker" document, or limiter in the code.
We will need to try and load the rate limit marker before we send our request. Within the sendRequest method, we'll open a RavenDB session and try to load the rate limit document:
module.exports = {
async sendRequest() {
const session = db.openSession();
let limiter = await session.load("RateLimit/ExternalApi");
await externalApi.fetch();
}
}
Notice the document ID of RateLimit/ExternalApi. Since we are trying to throttle outgoing requests to externalApi, I gave the document an ID that makes it easy to lookup. If we had multiple services we needed to throttle, we could store them side-by-side in other documents.
This rate limit marker won't always be present. When we have a fresh database, the document will not be there and when we eventually enable document expiration, RavenDB will delete the document when it expires. If it isn't present, we need to create it and save it back to the database:
module.exports = {
async sendRequest() {
const session = db.openSession();
let limiter = await session.load("RateLimit/ExternalApi");
if (limiter === null) {
limiter = { id: "RateLimit/ExternalApi" };
await session.store(limiter);
await session.saveChanges();
}
await externalApi.fetch();
}
}
There is nothing new yet here as far as working with RavenDB. By assigning the id ourselves, that will be the document key RavenDB uses when storing the document. For Node apps, you can also use a class and Raven will use that as the collection type. For literal objects, you can customize the field Raven looks at using conventions. We store the entity to track changes and save immediately so the document is persisted.
Counting Requests Using RavenDB Counters
We've loaded (or created) our rate limit marker document. This is used to store counters, so we'll need to use the Counters API to retrieve any counters associated with our document.
We'll start by eagerly loading the requests counter:
module.exports = {
async sendRequest() {
const session = db.openSession();
let limiter = await session.load("RateLimit/ExternalApi", {
includes(includeBuilder) {
return includeBuilder.includeCounter("requests");
}
});
if (limiter === null) {
limiter = { id: "RateLimit/ExternalApi" };
await session.store(limiter);
await session.saveChanges();
}
await externalApi.fetch();
}
}
Normally when retrieving counter values, RavenDB will send an HTTP request to the database to grab the current value of the counter. But since session.load is already loading the document, it seems wasteful to fetch the counter value in a second request. To remove the extra roundtrip, we can eagerly load the counter value in the load call using the second options argument and the include callback which is passed an includeBuilder you can chain includes off of.
What do you mean, "includes"? Unlike many NoSQL solutions, RavenDB supports relationships and can eagerly load related documents! Counters are another type of entity RavenDB can eagerly fetch.
We can now retrieve the counter value using the session.countersFor.get API:
module.exports = {
async sendRequest() {
const session = db.openSession();
let limiter = await session.load("RateLimit/ExternalApi", {
includes(includeBuilder) {
return includeBuilder.includeCounter("requests");
}
});
if (limiter === null) {
limiter = { id: "RateLimit/ExternalApi" };
await session.store(limiter);
await session.saveChanges();
}
const limitCounters = session.countersFor(limiter);
const requests = await limitCounters.get("requests");
await externalApi.fetch();
}
}
In two lines of code, we can retrieve the request counter value. If the counter has no value yet, it will be null. Otherwise, it will return a number value. If the counter value exceeds our max limit, we can abort the request!
const REQUEST_LIMIT = 30;
module.exports = {
REQUEST_LIMIT,
async sendRequest() {
const session = db.openSession();
let limiter = await session.load("RateLimit/ExternalApi", {
includes(includeBuilder) {
return includeBuilder.includeCounter("requests");
}
});
if (limiter === null) {
limiter = { id: "RateLimit/ExternalApi" };
await session.store(limiter);
await session.saveChanges();
}
const limitCounters = session.countersFor(limiter);
const requests = await limitCounters.get("requests");
if (requests !== null && requests >= REQUEST_LIMIT) {
return;
}
await externalApi.fetch();
}
}
In the sample application, REQUEST_LIMIT is set to 30. After 30 requests, we need to stop calling the external API.
If we haven't reached the threshold yet, only then do we increment the counter. When you call increment or decrement, you also need to call saveChanges to persist the counter update. RavenDB treats this as a transaction so if the save fails, the counter will not be updated.
const REQUEST_LIMIT = 30;
module.exports = {
REQUEST_LIMIT,
async sendRequest() {
const session = db.openSession();
let limiter = await session.load("RateLimit/ExternalApi", {
includes(includeBuilder) {
return includeBuilder.includeCounter("requests");
}
});
if (limiter === null) {
limiter = { id: "RateLimit/ExternalApi" };
await session.store(limiter);
await session.saveChanges();
}
const limitCounters = session.countersFor(limiter);
const requests = await limitCounters.get("requests");
if (requests !== null && requests >= REQUEST_LIMIT) {
return;
}
limitCounters.increment("requests");
await session.saveChanges();
await externalApi.fetch();
}
}
That is all the code we need to track the request count and abort the request if it exceeds our max limit. In a production application, you may choose to take some other action such as exponentially backing off to wait, defer execution until the sliding time window expires, or another action.
Speaking of the sliding time window, this code successfully prevents us from sending requests if we exceed the request limit but once we do, it will never send any again until the counter is reset. To account for this, we'll add a time component so that requests will start back up after a specific window expires.
Sliding Time Windows with Document Expiration
In the sample app, you can only send 30 requests within 30 seconds. If the limit is reached within any 30 second time period, you need to wait for that window to expire before trying again.
To accomplish this, we can leverage another RavenDB feature: document expiration. You will first need to enable document expiration in your database (it's disabled by default). Once enabled, it is only a matter of attaching a specific metadata key to your document with a UTC timestamp to make it expire.
To help with the date manipulation, we'll add a dependency on date-fns.
const { addSeconds } = require('date-fns');
const db = require('./db');
const externalApi = require('./external-api');
const REQUEST_LIMIT = 30;
const SLIDING_TIME_WINDOW_IN_SECONDS = 30;
module.exports = {
REQUEST_LIMIT,
SLIDING_TIME_WINDOW_IN_SECONDS,
async sendRequest() {
const session = db.openSession();
let limiter = await session.load("RateLimit/ExternalApi", {
includes(includeBuilder) {
return includeBuilder.includeCounter("requests");
}
});
if (limiter === null) {
limiter = { id: "RateLimit/ExternalApi" };
await session.store(limiter);
const metadata = session.advanced.getMetadataFor(limiter);
metadata["@expires"] = addSeconds(
new Date(), SLIDING_TIME_WINDOW_IN_SECONDS);
await session.saveChanges();
}
const limitCounters = session.countersFor(limiter);
const requests = await limitCounters.get("requests");
if (requests !== null && requests >= REQUEST_LIMIT) {
return;
}
limitCounters.increment("requests");
await session.saveChanges();
await externalApi.fetch();
}
}
Again in another two lines of code, we've added the ability to expire a document after a certain time. In the sample, SLIDING_TIME_WINDOW_IN_SECONDS is set to 30 seconds. Once the document expires and is deleted, our code will create a new rate limit marker document which resets the counters back to 0, allowing it to continue making requests until the limit is reached. Since RavenDB will remove expired documents automatically in the background, this acts as our sliding time window.
Note: It's worth calling out that by default, RavenDB deletes expired documents every 60 seconds. When your document expires, it will not be deleted until that interval lapses. This means at most, the document will stick around SLIDING_TIME_WINDOW_IN_SECONDS + 60 seconds until it's actually deleted. You can adjust this setting to suit your needs.
Sending Requests Across Multiple Instances
The premise of this article was that in a distributed scenario, RavenDB will be the orchestrator for throttling requests. How does this solution pan out?
If you have the sample set up locally, you can spin up multiple instances of to see them work together. Here's a quick demonstration of multiple processes running:
Limitations of this Solution
There are several limitations to be aware of with this solution as-is:
- Multiple processes could concurrently create a new
RateLimit document. To account for this, you could enable optimistic concurrency. - Multiple processes could increment if request counter is
N - 1, which would result in extra requests possibly causing an API exception (if your rate limit was exceeded). - When the request limit is exceeded, the program retries in a tight loop. In a production app, you would be better off deferring execution until the time window has lapsed.
These limitations could be worked around using more error checking but in the real world, these are unlikely to cause much of an issue with appropriate retry logic and API exception handling. For example, I use message queueing and Polly for distributed scenarios like this.
Conclusion
In this article, I showcased how you can throttle outgoing HTTP requests by using two features of RavenDB, Counters and Document Expiration. If you want an easy way to get started from scratch with RavenDB, check out my Pluralsight course, Getting Started with RavenDB 4. Otherwise, jump in and download the new version now or head over to the Learn RavenDB site!
History
- 5th March, 2020: Initial version

