My original goal for these experiments was to demonstrate the folly of comparing an optimized library like cuGraph to a pure Python library like NetworkX. The C++ Louvain reference implementation closes the performance gap significantly, but the large variation in the number of communities means there’s more to the story than just performance.
If you’ve read my last two blogs, Measuring Graph Analytics Performance and Adventures in Graph Analytics Benchmarking, you know that I’ve been harping on graph analytics benchmarking a lot lately. You also know that I use the GAP Benchmark Suite from the University of California, Berkeley, because it's easy to run, tests multiple graph algorithms and topologies, provides good coverage of the graph analytics landscape--and, most important--gives comprehensive, objective, and reproducible results. However, GAP doesn’t cover community detection in social networks.
The Louvain algorithm[1] for finding communities in large networks is a possible candidate to close this gap (pun intended). First, it’s a well-studied approach. According to Google Scholar*, the article describing this algorithm has over 10,000 citations as of November 2019. Second, it’s designed for large graphs. The original article analyzed a Web graph with 118 million vertices and over one billion edges. So, let’s take a look at benchmarking the Louvain algorithm.
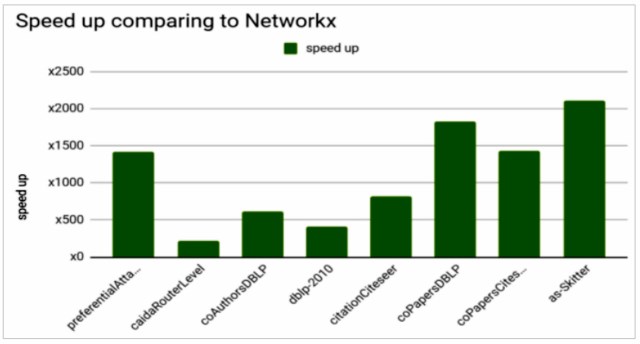
I recently came across a Louvain performance comparison of RAPIDS cuGraph* and NetworkX* (Figure 1). NetworkX is a comprehensive library for network analysis. It covers even the most obscure areas of network research. Need a triadic census? NetworkX has you covered. It’s a good library, if you’re working with very small graphs. NetworkX is a pure Python* library, so its performance isn’t great. Why compare an optimized library like cuGraph to an unoptimized library, unless the goal is to report inflated speedups? But there’s an even bigger flaw: the source article for Figure 1 didn’t say if cuGraph and NetworkX gave the same output. So, I decided to do my own comparisons.
I used the reference implementation of the Louvain algorithm (downloaded November 2019)[2] because it’s written in C++ and should give better performance than Python. I compiled this package as follows:

This creates the three executables that I need: convert (converts a raw edge list into a more efficient binary format), louvain (partitions the graph into communities using modularity optimization[3]), and hierarchy (displays the community structure). I used the standard build with the GNU C++ compiler, as I did in my previous GAP experiments. The source code was not modified, and I did not change the compiler options in the original Makefile.
I followed the instructions in the README.txt file (included in louvain-generic.tar.gz) to prepare the input data and run the Louvain reference implementation:
The graphs listed in Figure 1 were downloaded from the SuiteSparse Matrix Collection and converted to edge lists. It is worth reiterating that these are small graphs (Table 1). The largest has only 1.7M vertices.
Table 1. Size characteristics of the small graphs used in Figure 1
By comparison, the smallest and largest graphs in the GAP Benchmark Suite have 23.9M and 134.2M vertices, respectively, and the Louvain algorithm was originally tested on a 118M-vertex graph. The graphs in Figure 1 were probably selected for two reasons. First, they must be small enough to fit in the memory of a single NVIDIA Tesla V100 because the Louvain implementation in cuGraph cannot use the aggregate memory of multiple GPUs. Second, it’s comparing to NetworkX, so compute times for larger graphs would have been prohibitively expensive for a pure Python library.
Before we consider relative performance, let’s talk about correctness. The source article only showed the performance data in Figure 1 without considering whether NetworkX and cuGraph were giving the same output. Is each Louvain implementation detecting the same communities? A simple count of the communities detected by each Louvain implementation shows significant variations (Table 2). Small variations in communities are to be expected because the internal heuristics may be different in each implementation. However, some of the differences are so large that performance comparisons become suspect. For example, is one implementation converging on a set of communities too early? What constitutes correct output for Louvain computations on these graphs? One of the main advantages of GAP or any standard benchmark is that they define the correct output for a given test. Without such definitions, apples-to-apples performance comparisons are difficult or impossible.
Table 2. Variation in the number of communities detected by each Louvain implementation. cuGraph
[4] tests were run in an AWS EC2 p3.16xlarge instance.
[5] cuGraph was run on a single V100. NetworkX and the Louvain reference implementation were run on a single Intel® Xeon® processor.
[6]Comparing cuGraph to the sequential C++ reference implementation of the Louvain algorithm significantly closes the performance gap (Figure 2). I can probably close the gap even further with a few simple changes. For example, I could switch to the Intel compiler to enable aggressive optimization and vectorization, or I could try parallelizing the reference implementation using OpenMP, but I’m reluctant to do this until I can establish ground truth. For now, I’m satisfied that the 1.4x to 10x speedups for cuGraph are a far cry from the 200x to 2,100x speedups reported in Figure 1. However, I’m only satisfied because I know there are problems with these performance comparisons. As with most ad hoc, undefined benchmarks, the results must be taken with a grain of salt.
Figure 2. Performance comparison of the Louvain reference implementation vs. cuGraph for several small graphs.
[7] Note that only compute time (in seconds, lower is better) is measured. The time to load and setup the graphs is ignored. cuGraph tests were run in an AWS EC2 p3.16xlarge instance. cuGraph was run on a single V100. The Louvain reference implementation was run on a single intel Xeon processor.
Establishing Ground Truth
In an attempt to establish ground truth, I ran each Louvain implementation on the famous Zachary[8]Karate Club social network. This graph is small enough (only 34 vertices and 78 edges) to manually check if all implementations produce the same communities. NetworkX, cuGraph, and the Louvain reference implementation each give slightly different results (variations are highlighted).
NetworkX
Louvain Reference Implementation
cuGraph
Given the variations in Table 2, it’s not surprising that each package produces different communities. They find communities that are subjectively reasonable, though not identical to those reported by Girvan and Newman (2002, see Figure 4b):
Conclusions
My original goal for these experiments was to demonstrate the folly of comparing an optimized library like cuGraph to a pure Python library like NetworkX. The C++ Louvain reference implementation closes the performance gap significantly, but the large variation in the number of communities means there’s more to the story than just performance. What are the correct communities for each input graph? Is one Louvain implementation right, and the others wrong?
The difficulty establishing ground truth for even the widely-studied Zachary social network highlights the importance of objective, clearly-defined graph analytics benchmarks. The Louvain algorithm might make a good addition to the GAP Benchmark Suite because it would expand coverage into community detection, which GAP currently lacks, but ad hoc performance measurements are insufficient. A reasonable and reproducible test must be defined by the graph analytics community. Until then, if community detection performance is important for decision-making, I recommend the LDBC Graphalytics benchmark.
[1] Blondel et al. (2008). “Fast unfolding of Communities in Large Networks,” J Stat Mech, P10008.
[2] See "Louvain method: Finding Communities in Large Networks" for more information about this package. It is worth noting that the reference implementation has not been parallelized.
[3] Girvan and Newman (2002). "Community Structure in Social and Biological Networks," Proc Natl Acad Sci, 99(12), 7821-7826.
[4] The cuGraph code was adapted from https://github.com/rapidsai/notebooks/blob/branch-0.11/cugraph/community/Louvain.ipynb.
[5] GPU: NVIDIA Tesla V100 with 16 GB HBM; System memory: 480 GB; Operating system: Ubuntu Linux release 4.15.0-1054-aws, kernel 56.x86_64; Software: RAPIDS v0.1.0 (downloaded and run November 2019).
[6] CPU: Intel® Xeon® Gold 6252 (2.1 GHz, 24 cores), HyperThreading enabled (48 virtual cores per socket); Memory: 384 GB Micron DDR4-2666; Operating system: Ubuntu Linux release 4.15.0-29, kernel 31.x86_64; Software: GNU g++ v7.4.0, NetworkX v2.3, community API v0.13, Louvain reference implementation (downloaded and run November 2019).
[7] For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
[8] Zachary (1977). “An Information Flow Model for Conflict and Fission in Small Groups,” J Anthropol Res, 33(4), 452-473.

