We’ll walk you through a few key Vulkan performance samples that demonstrate common optimizations and best practices to follow in your mobile games, so you can start squeezing every last drop of performance out of the device and give your fans the game they absolutely need to play, through the power of Vulkan APIs.
As an Android game developer, you have two choices for graphics APIs: OpenGL ES and Vulkan. In this article, we’re going to take a look at Vulkan. Designed for developers looking to push the cutting edge of real-time 3D graphics on mobile devices, Vulkan acts as a super-thin abstraction layer, giving you much more control, lower CPU overhead, a smaller memory footprint, and greater stability.
We’ll walk you through a few key Vulkan performance samples that demonstrate common optimizations and best practices to follow in your mobile games, so you can start squeezing every last drop of performance out of the device and give your fans the game they absolutely need to play, through the power of Vulkan APIs.
Maximum Performance. Minimum Overhead.
How Vulkan enables high-performance, cross-platform graphics is simple: “With great power comes great responsibility.” To enable developers to reach the maximum graphics performance possible on a device, Vulkan allows more control over the hardware resources than OpenGL ES, in exchange for requiring more explicit memory management and operations. And to achieve lower CPU overhead, the Vulkan API supports multithreading and takes advantage of the four to eight cores built into mainstream mobile devices.
For more detail, Vulkan Essentials is a great resource with an in-depth explanation of how Vulkan works under the hood.
Vulkan API Samples and Tutorials
There are tons of great resources and examples available to learn how to use the Vulkan API. The two examples we’ll look at are Render Passes and Wait Idle, which demonstrate some of the most useful optimizations you can take advantage of in your own mobile game. These performance samples show recommended best practices for enhancing performance with the Vulkan APIs, and provide real-time profiling information to help you identify and understand bottlenecks in your application. The full set of samples and tutorials, open-sourced by Arm and administered by the Khronos Group, can be found here.
This article assumes you’re familiar with 3D render pipelines and Vulkan API basics. If you’re new to Vulkan, this Vulkan Guide and introductory tutorial will help you get your first triangles rendered. For additional examples, refer to these API samples that cover topics such as HDR, instancing, texture loading, and tessellation.
Prerequisites
To work with the Vulkan samples, you need to have the right tools and dependencies. For Android, you can check out the Android section of the Build Guide.
The main prerequisites are:
- CMake v3.10 or later
- JDK 8 or later
- Android NDK r18 or later
- Android SDK
- Gradle 5 or later
- Sample 3D Models
Appropriate Use of Render Pass Attachments
Render pass attachments are how Vulkan keeps track of your input and output render targets. It might make sense to think of them as references to color or depth buffers. Configuring them optimally is a simple but effective way to gain precious milliseconds during the render pass.
Let’s start by taking a look at this performance tutorial and sample code.
If you run this sample, you’ll see an app rendering a 3D scene in a single pass, with a GUI showing render stats and options to switch between load operations for the color attachment and store operations for the depth attachment.
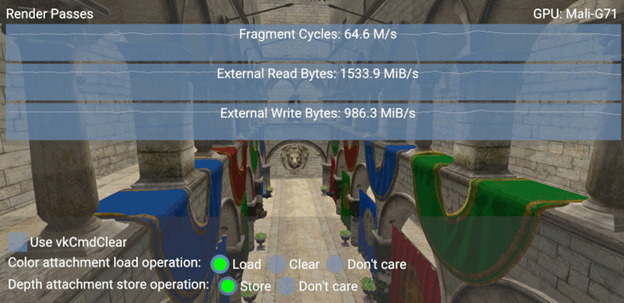
Knowing whether or not the contents of the attachment buffer needs to be cleared of a color, read from, or written to can greatly affect the draw performance because you can set it up in a way to minimize the number of read/write operations.
For example, because you don’t need to read the contents of the final color buffer drawn to the screen, in Vulkan, you can set its load operation for the attachment description to VK_ATTACHMENT_LOAD_OP_DONT_CARE and speed up your render pass.
You can test this out by selecting Load for your color attachment load operation and then seeing how the External Read Bytes value increases because it prepares your color buffer to not just draw the scene, but also to be able to read in its contents for this pass.
Changing the Depth attachment store operation has a similar effect on External Write Bytes because you’re indicating whether you want to spend time saving the depth information to the buffer.
Here is a typical setup for how you could optimally use render pass attachments when drawing a 3D scene in your own code:
VkAttachmentDescription attachments[
2 ];
//
Color attachment
attachments[ 0 ].format = colorFormat;
attachments[ 0 ].samples = VK_SAMPLE_COUNT_1_BIT;
attachments[ 0 ].loadOp = VK_ATTACHMENT_LOAD_OP_DONT_CARE;
attachments[ 0 ].storeOp = VK_ATTACHMENT_STORE_OP_STORE;
attachments[ 0 ].stencilLoadOp =
VK_ATTACHMENT_LOAD_OP_DONT_CARE;
attachments[ 0 ].stencilStoreOp = VK_ATTACHMENT_STORE_OP_DONT_CARE;
attachments[ 0 ].initialLayout = VK_IMAGE_LAYOUT_UNDEFINED;
attachments[ 0 ].finalLayout =
VK_IMAGE_LAYOUT_PRESENT_SRC_KHR;
//
Depth attachment
attachments[ 1 ].format = depthFormat;
attachments[ 1 ].samples = VK_SAMPLE_COUNT_1_BIT;
attachments[ 1 ].loadOp = VK_ATTACHMENT_LOAD_OP_CLEAR;
attachments[ 1 ].storeOp =
VK_ATTACHMENT_STORE_OP_DONT_CARE;
attachments[ 1 ].stencilLoadOp =
VK_ATTACHMENT_LOAD_OP_DONT_CARE;
attachments[ 1 ].stencilStoreOp =
VK_ATTACHMENT_STORE_OP_DONT_CARE;
attachments[ 1 ].initialLayout = VK_IMAGE_LAYOUT_UNDEFINED;
attachments[ 1 ].finalLayout =
VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL;
VkAttachmentReference colorReference = {};
colorReference.attachment = 0;
colorReference.layout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL;
VkAttachmentReference depthReference = {};
depthReference.attachment = 1;
depthReference.layout = VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL;
VkSubpassDescription subpass = {};
subpass.pipelineBindPoint = VK_PIPELINE_BIND_POINT_GRAPHICS;
subpass.colorAttachmentCount = 1;
subpass.pColorAttachments = &colorReference;
subpass.pDepthStencilAttachment = &depthReference;
VkRenderPassCreateInfo renderPassInfo = {};
renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_CREATE_INFO;
renderPassInfo.attachmentCount = 2;
renderPassInfo.pAttachments = attachments;
renderPassInfo.subpassCount = 1;
renderPassInfo.pSubpasses = &subpass;
vkCreateRenderPass( g_device, &renderPassInfo, nullptr,
&renderPass );
One final option demonstrated in this sample is the Use vkCmdClear checkbox, which will explicitly clear the color attachment, and demonstrates how doing so can negatively affect performance. Resetting the whole buffer by using the load operation is more efficient, so using this explicit clear function is better reserved for other scenarios, such as when you need to specify an inner rectangular region to be cleared.
For instance, if you want to keep a 10px border intact, you could add to your command buffer like this:
VkClearAttachment clearAttachment =
{};
clearAttachment.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
clearAttachment.clearValue.color = 0;
clearAttachment.colorAttachment = 0;
VkClearRect clearRect = {};
clearRect.layerCount = 1;
clearRect.rect.offset = { 10, 10 };
clearRect.rect.extent = { width - 20, height - 20 };
vkCmdClearAttachments( g_cmdBuffer, 1,
&clearAttachment, 1, &clearRect );
Optimization Tip: Identifying specifically how you’re using each render pass attachment will help make sure you get the best read/write throughput. Remember to use VK_ATTACHMENT_LOAD_OP_CLEAR when you need to clear a render target. And when you don’t need to read an attachment’s contents, set VK_ATTACHMENT_LOAD_OP_DONT_CARE to avoid unnecessary operations.
Synchronizing the CPU and GPU
Some of Vulkan’s render pipeline computations are done on the CPU, like creating command buffers, and others are done on the GPU, such as shaders and render targets. Processing them in the correct order means that the CPU and GPU need to work with each other with proper timing.
An easy and reliable way to accomplish this with Vulkan APIs is to use vkQueueWaitIdle to simply wait for the current queue to be empty before the CPU adds new commands to hand off to the GPU. However, one of the biggest gains to your render throughput can come from making sure your GPU and CPU aren’t sitting around waiting for long periods of micro-time and can work right away on preparing the next frame.
You can see how this makes a difference in the Wait Idle performance tutorial and sample code.

Running this sample shows a scene with two options, Wait Idle and Fences, and text showing the frame times (the average time it took to render the frame). This sample demonstrates how efficiently queuing up the next frame (or the next command buffer for more complex passes) can improve performance.
When you run the sample, you’ll notice that the frame times are much higher with the Wait Idle option selected, and lower when the Fences option is selected.
Here is how you could set up your render loop to do this in your code to use fences:
void render()
{
vkWaitForFences( g_device, 1, &g_renderFence, VK_TRUE,
UINT64_MAX );
vkResetFences( g_device, 1, &g_renderFence );
// Update frame with new commands
setCmdBuffer( g_cmdBuffer );
uint32_t imageIndex;
vkAcquireNextImageKHR( g_device, g_swapchain, UINT64_MAX,
g_imageSemaphore,
VK_NULL_HANDLE, &imageIndex );
VkSubmitInfo submitInfo = { VK_STRUCTURE_TYPE_SUBMIT_INFO };
submitInfo.waitSemaphoreCount = 1;
submitInfo.pWaitSemaphores = &g_imageSemaphore;
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &g_cmdBuffer;
vkQueueSubmit( g_queue, 1, &submitInfo, g_renderFence );
VkPresentInfoKHR presentInfo =
{
VK_STRUCTURE_TYPE_PRESENT_INFO_KHR };
presentInfo.waitSemaphoreCount = 1;
presentInfo.pWaitSemaphores = &g_renderSemaphore;
presentInfo.swapChainCount = 1;
presentInfo.pSwapchains = &g_swapchain;
presentInfo.pImageIndices = &imageIndex;
vkQueuePresentKHR( g_queue, &presentInfo );
}
Optimization Tip: Keep your render queue moving by avoiding vkQueueWaitIdle and vkDeviceWaitIdle and using VkFence objects and vkWaitForFences. You need to make sure that each fence works independently of the others without overlap (separate render frames, for example). Also, if you have multiple commands within a single frame on the GPU that don’t need to be synchronized with the CPU, you might consider using VkSemaphore objects instead.
To see a more detailed example on synchronizing the CPU and GPU, you can also take a look at this Vulkan tutorial for Frames in Flight.
Next Steps
We briefly looked at two examples of how to use Vulkan to maximize the graphics performance in your game. Vulkan provides some low-level optimizations that require you to manage processes in your app on a more granular level. But as you've seen, implementing some individual Vulkan APIs makes it easier to get started and can pay performance dividends immediately.
That’s only the beginning. There are many more open source tutorials and samples available here to help you optimize the drawing of polygons and do more with your render passes in your mobile game.
Here are a few more performance samples we recommend if you’re developing for Android devices with Vulkan:
- Benefits of Subpasses Over Multiple Render Passes
- Enabling AFBC (Arm Frame Buffer Compression)
- Using Pipeline Barriers Efficiently
And here are some other useful resources:
- PerfDoc - Vulkan tool that validates applications for best practices
- Mali GPU Best Practices - Best practices guide for Arm Mali GPUs
- Android NDK Vulkan Graphics API Guide

