In this article, we’ll explore the HiFUN solver, proprietary software from S&I Engineering Solutions (SandI) Pvt. Ltd., as an example of a CFD application that can take full advantage of the architecture of massively parallel supercomputing platforms.
Computational fluid dynamics (CFD) is a branch of science that deals with numerical solutions for equations governing fluid flow―with the help of high-speed computers. And, because they’re based on a mountain of data, it’s essential for CFD solutions to get every last bit of performance out of today’s high-performance computing (HPC) hardware platforms.
CFD uses the Navier-Stokes equations―non-linear, partial differential equations describing mass, momentum, and energy conservation for a fluid flow. In CFD, discretization is a technique to convert the Navier-Stokes equations into a set of algebraic equations. Due to the geometric complexity and complicated flow physics associated with an industrial application, the typical size of the algebraic system varies from a few million to over a billion equations. That means realistic numerical simulations need to be carried out on large-scale HPC platforms to obtain design data in a timeframe short enough to impact the design cycle.
In this article, we’ll explore the HiFUN* solver, proprietary software from S&I Engineering Solutions (SandI) Pvt. Ltd., as an example of a CFD application that can take full advantage of the architecture of massively parallel supercomputing platforms.1,2
Reaching Scalable Performance
Three factors affect the performance of HPC applications:
- Single-process performance
- Load balance
- Algorithmic scalability3
To reach load balance, the discretized computational domain (also called the workload, grid, or mesh) should be divided so that the computational work assigned to every processor core is approximately the same. However, load balancing shouldn’t lead to excessive data communication among the distributed processors. These two requirements often conflict, so it’s necessary to strike a balance between them. Domain decomposition using METIS2 is a common way to achieve load balance in CFD simulations. Algorithmic scaling is another critical performance factor in parallel applications.2 Ideally, the performance of a parallel solver shouldn’t degrade as the number of processors increases.
The third factor limiting the parallel performance of a CFD application like the HiFUN solver is the gap between faster processor speed and slower memory access speed―which can lead to a decline in single-process performance. To overcome this problem, many computers use a memory hierarchy, where a small portion of the data required for immediate computations resides in memory, which has the fastest access, called cache. This means it’s important to fully utilize the data brought into the cache memory―which requires good data layout in the memory to ensure spatial locality of the grid data. Though the issue of single-process performance is partly addressed at the application level with ordering algorithms like Cuthill McKee , it’s still a chore to completely exploit process performance given the varied nature of computational operations involved in a CFD solver. In this context, the evolution of Intel® processor technology is boosting the single-process performance of CFD applications in a big way. The latest generation of Intel® Xeon® processors provides large-cache, high-memory bandwidth with an increased number of data channels between the processor and memory, as well as higher memory speed. For a CFD application, improved single-process performance naturally leads to improved single-node performance.
To explore how the advancements in processor technology translate into improved software performance, we evaluated the performance improvement of HiFUN on the Intel® Xeon® Scalable processor compared to its predecessors, assessing both the single-node and multi-node performance of HiFUN.
HiFUN CFD Solver
HiFUN is a state-of-the-art, general-purpose CFD solver that’s robust, fast, and accurate, providing aerodynamic design data in an attractive turnaround time. Its usefulness stems from its ability to handle the complex geometries and complicated flow physics in a typical industrial environment. Using unstructured data capable of handling arbitrary polyhedral volumes gives HiFUN the ability to simulate complex geometries with relative ease. Plus, the use of a matrix-free implicit procedure results in rapid convergence to steady state―making the solver both efficient and robust.
The accuracy of HiFUN has been amply demonstrated in various international CFD code evaluation exercises such as the AIAA Drag Prediction Workshops and AIAA High Lift Prediction Workshops. HiFUN has been successfully used in simulations for a wide range of flow problems, from low subsonic speeds to hypersonic speeds.
Evaluating Parallel Performance
To evaluate the parallel performance of the HiFUN solver, we need to consider these metrics:
- Ideal speedup: The ratio of the number of cores used in a given run to a reference number of cores (i.e., the smallest number of cores used in the study).
- Actual speedup: The ratio of time per iteration when the reference number of cores are used for a given computation to the time per iteration for a given number of cores.
- Parallel efficiency: The ratio of actual speedup to ideal speedup.
- Machine performance parameter (MPP): The ratio of actual speedup to ideal speedup.
The first three parameters are well-known in parallel computing literature. The fourth parameter, MPP, provides a way to evaluate different computing platforms for a given CFD application.1 A computing platform with a smaller MPP value is expected to provide better computing performance compared to other platforms.
An important strength of the HiFUN solver is its ability to scale over several thousand processor cores. This was amply demonstrated in a joint SandI-Intel study that showed HiFUN can scale over 10,000 Intel Xeon processor cores on the NASA Pleiades supercomputer. The configuration used for the study was the NASA Trap Wing (Figure1). Figures 2 and 3 show the speedup and parallel efficiency curves, respectively, obtained using a grid of 63.5 million volumes.From Figure 2, we can see that HiFUN shows a near-ideal speedup for 4,096 processor cores. It’s also worth noting that for 7,168 processor cores on Pleiades, the parallel efficiency exhibited by HiFUN is about 88%. Also, even for 10,248 processor cores with a modest grid size of about 63.5 million volumes, HiFUN offers reasonable parallel efficiency of about 75%. This scalable parallel performance of HiFUN is a boon to designers because they can expect to have a turnaround time independent of the problem size.
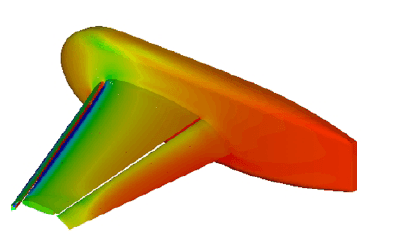
Figure 1 – Surface pressure fill plot on NASA Trap Wing configuration

Figure 2 – Speedup curve
Figure 3 – Parallel efficiency curve
The configuration for the study was the NASA Common Research Model (CRM) used in the 6th AIAA Drag Prediction Workshop. As shown in Figure 4, this configuration represents a transport aircraft with wing, fuselage, nacelle, and pylon. The free-stream Mach number, angle of attack, and free-stream Reynolds number, based on mean aerodynamic chord, are 0.85, approximately 2.6°, and 5 million, respectively. The workload for the analysis has approximately 5.1 million hexahedral volumes. The computed pressure distribution on the surface of NASA CRM is shown in Figure 4.
Figure 4 – Surface pressure fill plot on NASA CRM configuration
In this study, we chose two generations of Intel Xeon processors for comparing the single-node performance of the HiFUN solver (Table 1):
- Intel Xeon E5-2697 v4 processor
- Intel Xeon Scalable processor Gold 6148
Note that the Intel Xeon Scalable processor has 20 cores, while the Intel Xeon processor has 18 cores. Since the clock frequency of individual processor cores for both processors is nearly the same, based on just the increased numbers of cores, and assuming linear scalability, we expected the performance improvement would be about 11%. But, as shown in Figure 5, the HiFUN solver shows a performance improvement of about 22% on the Intel Xeon Scalable processor compared to the Intel Xeon processor. We can attribute this to:
- Extra processor cores
- Larger L2 cache
- Higher memory speeds
- Higher memory bandwidth from the increased number of memory channels available in the Intel Xeon Scalable processor.
Table 1. Processors used in the study
| Features | Intel Xenon Processor | Intel Xenon Scalable Processor |
| Processor | Intel Xeon E5-2697 v4 processor | Intel Xeon Scalable processorGold 6148 |
| Cores per socket | Intel Xeon E5-2697 v4 processor>18 | Intel Xeon Scalable processorGold 6148>20 |
| Cores per socket>Speed | 2.3 GHz | 2.4 GHz |
| Cache (L2/L3) | 256 KB/45 MB | 1 MB/27 MB |
| Memory size | 128 GB | 192 GB |
| Memory speed | 2,400 MHz | 2,666 MHz |
| Memory channels | 4 | 6 |
Figure 6 shows the MPP for both the processors. As expected, the Intel Xeon Scalable processor has lower MPP compared to the Intel Xeon processor―clearly establishing its superior computing performance. At this stage, we should note that the higher core density of the Intel Xeon Scalable processor leads to improved intra-node parallel performance and results in a compact parallel cluster for a given number of processor cores.
Figure 5 – Performance of Intel Xeon Scalable processor compared to Intel Xeon processor
Figure 6 – MPP for Intel Xeon Scalable processor compared to Intel Xeon processor
Figure 7 shows a comparison of ideal speedup and actual speedup curves obtained using the HiFUN solver. We can see that as the number of nodes increases, the actual speedup becomes increasingly higher compared to the ideal speedup. We can also see this from Figure 8, where the parallel efficiency curve shows super-linearity for a number of nodes greater than or equal to two. This is because during the scalability study, as the given problem is fragmented into a large number of parts, the reduced memory requirement per processor core means the cache utilization becomes better. But, in general, the performance gain from improved cache utilization is offset by the overhead associated with increased data transfer across the processor cores as the problem is fragmented into a large number of parts.
In our study, we can attribute the ability of the HiFUN solver to exploit the improvement in cache utilization― leading to the super-linear performance―to an excellent interconnect between the nodes and the optimized Intel® MPI Library.
Figure 7 – Speedup of HiFUN on a multi-node Intel processor-based cluster
Figure 8 – Parallel efficiency of HiFUN on a multi-node Intel processor-based cluster
Maximizing HPC Platforms
To summarize, we’ve shown how the latest-generation Intel Xeon Scalable processor enhances the single-node performance of the HiFUN solver through the availability of large cache, higher core density per CPU, higher memory speed, and larger memory bandwidth through an increased number of memory channels. The higher core density improves intra-node parallel performance and should allow users to build more compact clusters for a given number of processor cores. Finally, we can attribute the superlinear performance of the HiFUN solver on HPC platforms based on the Intel Xeon Scalable processor to an excellent inter-node interconnect and the optimized Intel MPI Library.
#CodeModernization
References
- N. Balakrishnan, "Parallel performance of the HiFUN solver on CRAY XC40," Technical Note No. CAd TN 2015:03, November
2015. - Manke J. W., "Parallel Computing in Aerospace," guest editorial, Parallel Computing, Volume 27, 2001, pp. 329-336.
- George Karypis and Vipin Kumar, "A Software Package for Partitioning Unstructured Graphs, Partitioning Meshes and Computing
Fill-Reducing Ordering of Sparse Matrices," Version 4.0, University of Minnesota, Department of Computer Science/Army
HPC Research Center, Minneapolis, MN-55455, 1998.
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/performance.
Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.

