In this article, we’ll give a brief overview of the Intel AVX-512 Instruction Set Architecture (ISA) and describe what’s new in the Intel 18.0 compilers for Intel® Xeon® Scalable processors. Next, we present several new simd language extensions for Intel AVX-512 support in Intel’s latest compilers. Finally, we share our best practices in performance tuning to achieve optimal performance with the Intel AVX-512 ISA.
Intel® Advanced Vector Extensions 512 (Intel® AVX-512), the latest x86 vector instruction set, has up to two fused-multiply add units plus other optimizations. It can accelerate the performance of workloads such as:
- Scientific simulations
- Financial analytics
- Artificial intelligence
- 3D modeling and simulation
- Image and audio/video processing
- Cryptography
- Data compression/decompression
In this article, we’ll give a brief overview of the Intel AVX-512 Instruction Set Architecture (ISA) and describe what’s new in the Intel 18.0 compilers for Intel® Xeon® Scalable processors. Next, we present several new simd language extensions for Intel AVX-512 support in Intel’s latest compilers. Finally, we share our best practices in performance tuning to achieve optimal performance with the Intel AVX-512 ISA.
What’s New
Intel Xeon Scalable processors introduce several new variations of Intel AVX-512 instruction support. The main Intel AVX-512 ISA performance features on Intel Xeon Scalable processor-based servers compared to previous-generation Intel AVX2 are:
- Intel AVX-512 foundation:
- 512-bit vector width
- 32 512-bit long vector registers
- Data expand and compress instructions
- Ternary logic instruction
- Eight new 64-bit long mask registers
- Two source cross-lane permute instructions
- Scatter instructions
- Embedded broadcast/rounding
- Transcendental support
- Intel AVX-512 double- and quad-word Instructions (DQ): QWORD support
- Intel AVX-512 byte and word instructions (BW): Byte and Word support
- Intel AVX-512 Vector Length Extensions (VL): Vector length orthogonality
- Intel AVX-512 Conflict Detection Instructions (CDI): Vconflict instruction
These different AVX-512 features are meant to be supported directly by the hardware and enabled therein. In this article, we’ll focus on simd language extensions, compiler support, and tuning for the AVX-512-F, AVX-512-BW, AVX-512-CD, AVX-512-DQ, and AVX-512-VL features in Intel Xeon Scalable processors.
Tuning Challenges for Compilers and Programmers
Figure 1 shows the projected speedup for a theoretical application where a perfect vector speedup can be achieved for large portions of the code. In the era of four-way vectors such as in 32-bit integers/floats computed in XMM registers, having the application 80 percent vectorized results in a 2.5x speedup. Incremental benefits from the compiler and the programmers working harder to vectorize 90 or 95 percent of the code are limited.
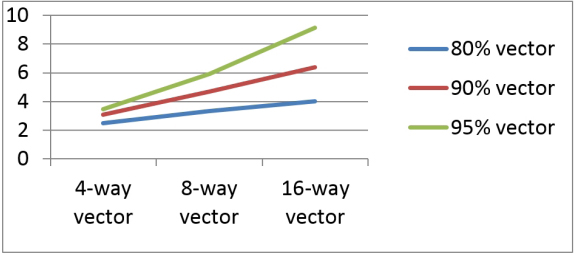
Figure 1 — Ideal vector speedup for a theoretical application
However, increasing to 8-way and especially 16-way vectors can significantly boost the performance of heavily-vectorized applications. Figure 1 clearly indicates the potential performance improvements when compilers and programmers squeeze more vector parallelism from applications to enjoy the benefits of the YMM and ZMM vectors in the Intel Xeon Scalable processors. Besides widening the vector registers, the AVX-512 ISA extension comes with a variety of architectural enhancements to help vectorize many more types of code patterns.
AVX-512F, AVX-512VL, and AVX-512BW
AVX-512F, AVX-512VL, and AVX-512BW include natural extensions of AVX and AVX2 for 32 registers and masking support. Together, they cover the largest portion of the Intel AVX-512 family of extensions. AVX-512F extends vector register size to 512-bit for 32-bit and 64-bit integer and floating-point element data. It also:
- Increases the number of architectural vector registers from 16 to 32
- Introduces dedicated mask registers
- Adds masking support for non-load/store operations
AVX-512VL extends AVX-512F so that support for 32 registers and masking can be applied to 128- and 256-bit vectors. Intel AVX-512BW extends Intel AVX-512F so that 32 registers and masking can be applied to 8- and 16-bit integer element data.
Table 1 uses vector add instructions to illustrate the relationship between the element data type (b/w/d/q/ps/pd), the instruction features (xmm/ymm/zmm, masked or no-mask, and register number 0-15/16-31),

Table 1. Relationship between element data type and instruction features (xmm/ymm/zmm, masked/no-mask, etc.)
and the minimum required ISA extensions on an Intel64 platform. For example, to add a vector of bytes (vpaddb) on the XMM16 register, support for both AVX-512VL and AVX-512BW are required whether the operation uses a mask or not. By providing support for all of AVX-512F, AVX-512VL, and AVX-512BW, Intel Xeon Scalable processors allow the programmers to utilize all 32 available registers and masking capability to all register sizes (XMM, YMM, or ZMM) and all data element types (byte, word, dword, qword, float, and double) on most of the operations.
Beyond natural extensions of AVX and AVX2, AVX-512F includes:
- Data compress (vcompress) operations that read elements from an input buffer on indices specified by mask register 1’s bits. The elements, which have been read, are then written to the destination buffer. If the number of elements is less than the destination register size, the rest of the space is filled with zeroes.
- Data expand (vexpand) operations that read elements from the source array (register) and put them in the destination register on the places indicated by enabled bits in the mask register. If the number of enabled bits is less than destination register size, the extra values are ignored.
AVX-512CDI
Intel AVX-512CDI is a set of instructions that, together with Intel AVX-512F, enable efficient vectorization of loops with possible vector dependences (i.e., conflicts) through memory. The most important instruction is VPCONFLICT, which performs horizontal comparisons of elements within a single vector register. In particular, VPCONFLICT compares each element of a vector register with all previous elements in that register, then outputs the results of all of the comparisons. Other instructions in Intel AVX-512CDI allow for efficient manipulation of the comparison results. We can use VPCONFLICT in different ways to help us vectorize loops. The simplest is to check if there are any duplicate indices in a given simd register. If not, we can safely use simd instructions to compute all elements simultaneously. If so, we can execute a scalar loop for that group of elements. Branching to a scalar version of the loop on any duplicate indices can work well if duplicates are extremely rare. However, if the chance of getting even one duplicate in a given iteration of the vectorized loop is large enough, then we would prefer to use simd as much as possible, to exploit as much parallelism as we can.
What’s New in Compiler 18.0 for AVX-512 Tuning
To achieve optimal performance on Intel Xeon Scalable processors, applications should be compiled with the processor-specific option –xCORE-AVX512 (/QxCORE-AVX512 on Windows*). Such an executable will not run on non-Intel® processors or on Intel processors that support only older instruction sets. Intel® Compilers 18.0 provide a new option
–qopt-zmm-usage=[high|low] for users to tune ZMM code generation:
- Option value low provides a smooth transition experience from the AVX2 ISA to AVX-512 ISA on Skylake (SKX) targets, such as for enterprise applications. Programmers are encouraged to tune for ZMM instruction usage via explicit vector syntax such as
#pragma omp simd simdlen(). - Option value high is recommended for applications that are bounded by vector computation (e.g., HPC applictions) in order to achieve more computations per instruction through wider vectors.
The default value is low for SKX-family compilation targets (e.g. -xCORE-AVX512). Intel compilers also provide a way to generate a fat binary that supports multiple instruction sets by using the –axtarget option. For example, if the application is compiled with –axCORE-AVX512,CORE-AVX2 the compiler can generate specialized code for AVX-512 and AVX2 targets, while also generating a default code path that will run on any Intel, or compatible non-Intel, processor that supports at least SSE2. At runtime, the application automatically detects whether it is running on an Intel processor. If so, it selects the most appropriate code path for Intel processors; if not, the default code path is selected.
It’s important to note that irrespective of the options used, compiler may insert calls to specialized library routines (such as optimized versions of memset/memcpy) that will dispatch to the appropriate code path at runtime based on processor detection.
New simd Extensions for AVX-512
Intel Compilers pioneered explicit vectorization of C/C++ and Fortran* application programs and led the standardization effort in OpenMP* 4.0 and 4.53,4,5,7,8. What follows are the results of our continued innovation on extending the power of explicit vectorization. We proposed them for future OpenMP specifications and have implemented them in Intel Compilers 18.0 as a lead vehicle for OpenMP standardization3,8.
Compress and Expand
Figure 2 shows compress and expand idioms. The compress and expand terms come from the code semantics. For instance, the compress pattern compresses all positive elements from the array A[] and stores them consecutively in the array B[]. It’s known that both patterns contain loop-carried dependencies (Figures 3 and 4) and can’t be parallelized.
// A is compressed into B
int count = 0;
for (int i = 0; i < n; ++i) {
if (A[i] > 0) {
B[count] = A[i];
++count;
}
}
// A is expanded into B
int count = 0;
for (int i = 0; i < n; ++i) {
if (A[i] > 0) {
B[i] = A[count];
++count;
}
}
Figure 2 — Compress and expand idioms
Figure 3 — Data dependence graph for compress and expand patterns
Figure 4 — Compress and expand execution
However, vectorizing compress and expand idioms is possible with special processing of the dependencies. AVX-512 ISA adds v[p]compress and v[p]expand instructions that helps effectively vectorize these codes. Figure 5 shows the generated simd code for the compress idiom using the new AVX-512 instruction vcompressps.
..B1.14:
vmovups (%rdi,%r11,4), %zmm2
vcmpps $6, %zmm0, %zmm2, %k1
kmovw %k1, %edx
testl %edx, %edx
je ..B1.16
..B1.15:
popcnt %edx, %edx
movl $65535, %r10d
vcompressps %zmm2, %zmm1{%k1}
movslq %ebx, %rbx
shlx %edx, %r10d, %r12d
notl %r12d
kmovw %r12d, %k1
vmovups %zmm1, (%rsi,%rbx,4){%k1}
addl %edx, %ebx
..B1.16:
addq $16, %r11
cmpq %r9, %r11
jb ..B1.14
Figure 5 — Compress idiom vectorization with AVX-512
Automatic idiom recognition and vectorization of compress and expand idioms have been implemented in the compiler for simple cases without a guarantee for complicated cases. To provide a vectorization guarantee for these idioms, we proposed and implemented simple language extensions to the OpenMP 4.5 simd specification to express the compress and expand idioms. Figure 6 shows the new clause monotonic added to the OpenMP ordered simd construct.
int j = 0;
#pragma omp simd
for (int i = 0; i < n; i++) { if (A[i]>0) {
#pragma omp ordered simd monotonic(j:1)
{
B[j++] = A[i];
}
}
}
int j = 0;
#pragma omp simd
for (int i = 0; i < n; i++) {
if (A[i]>0) {
#pragma omp ordered simd monotonic(j:1)
{
A[i] = B[j++];
}
}
}
Figure 6 Block-based syntaxes for compress and expand patterns
The monotonic clause and its associated ordered simd code block impose the following semantics and rules:
- When a vector iteration reaches the structured block of code, it evaluates step. This must yield an integral or pointer value that is invariant with respect to the
simd loop. The simd execution mask, under which the structured block of code is executed, is computed as well. Private copies of each monotonic list item are created for the structured block of code and initialized to item, item + step, item + 2 * step, ..., for each executing (with mask==T) simd element (from lower iteration index to higher). At the end of the structured block of code execution, a uniform copy of item is updated as item + popcount(mask) * step and private copies of list items become undefined.
- The use of the monotonic list item outside of the associated ordered
simd construct is disallowed (Figure 7). Multiple usages of the same list item in more than one ordered simd construct is also disallowed.
int j = 0;
#pragma omp simd
for (int i = 0; i < n; i++) {
if (A[i]>0) {
#pragma omp ordered simd monotonic(j:1)
{
++j;
}
B[j] = A[i];
}
}
Figure 7 — Disallowed usage of a monotonic item outside of the block
- Ordered
simd construct with monotonic clause may be implemented as ordered simd construct without the monotonic clause.
Histogram
Histogram (Figure 8) is a well-known idiom. The semantics of the histogram code counts equal elements of the array B[] and stores results in the array A[]. Obviously, depending on the content of the array B[], this loop may or may not have loop-carried dependency.
for (int i = 0; i < n; ++i) { ++A[B[i]]; }
Figure 8 — A simple histogram idiom
Essentially, there are three cases:
- If the array B[ ] has unique values, there is no loop-carried dependency.
- If all values of the array B[ ] are equal, this statement represents reduction of a scalar value.
- If some values are repeated in the array B[ ], this loop has loop-carried dependency.
At compile time, if the compiler can’t prove whether the values of B[] may or may not introduce data dependencies, the compiler behaves pessimistically and assumes loop-carried dependency. Programmers can help the compiler for case 1 by using #pragma ivpdep. For case 2, programmers may be asked to do manual transformation. For case 3, depending on the target architecture, vectorization can be implemented in the following ways with explicit vector annotations:
- Array reduction implementation (use
simd construct and reduction over array A[ ])
- Serial implementation (use ordered
simd construct for the self-update statement)
- Gather-update-scatter implementation and repeat for equal B[ ] values
For the gather-update-scatter implementation, AVX-512 provides AVX-512CDI, which contains the v[p] conflict instruction that allows efficient computation of overlapping indices within a vector of indices. To effectively leverage AVX-512CDI with a programmer guarantee to handle the histogram idiom, a new clause overlap is proposed and implemented in the Intel compilers as shown in Figure 9.
#pragma omp simd
for (int i = 0; i < n; i++) {
#pragma omp ordered simd overlap(B[i])
{
A[B[i]]++;
}
}
Figure 9 — Usage example of the overlap clause on the histogram idiom
This new clause has the following language semantics:
- When execution reaches the ordered
simd construct, it evaluates the values of overlap expression B[i] as an r-value, which must yield an integral or pointer value. The implementation must ensure that if two iterations of the enclosing simd loop compute the same values, the iteration with the lower logical iteration number must complete the execution of ordered simd code block before the other iteration starts execution of the same code block.
- Total ordering is not guaranteed by the compiler. It is the programmer’s responsibility to check whether the partial ordering is sufficient for any possible aliasing between stores to A[] and any loads of A[] and B[].
- The ordered
simd block specifies the region where overlapping should be checked. Thus, for statements outside of the ordered simd overlap block, the overlap check will not be performed.
- The ordered
simd construct with overlap clause may be implemented as an ordered simd construct without the overlap clause.
Conditional Lastprivate
A common case in many programs is that a loop produces the value of its last iteration where the assignment statement is actually executed (i.e., produces a write to a scalar). The value of the scalar will be used after the loop (Figure 10).
int t = 0;
#pragma omp simd lastprivate(t)
for (int i = 0; i < n; i++) {
t = A[i];
}
int t = 0;
for (int i = 0; i < n; i++) {
if (A[i] > 0) {
t = A[i];
}
}
Figure 10 — The code on the left gets the last element of A[i], while the code on the right gets the last positive element of A[i].
Both code snippets in Figure 10 can be vectorized, but only the code on the left has explicit support in OpenMP through the lastprivate clause. The lastprivate clause can’t be used for the code on the right because of its semantics. The scalar t gets the value from the last executed iteration of the loop; thus, the t is undefined if the condition A[n-1]>0 is not true. To address this issue, a new modifier, conditional,is proposed and added to the clause lastprivate (Figure 11).
int t = 0;
#pragma omp simd lastprivate(conditional:t)
for (int i = 0; i < n; i++) {
if (A[i] > 0) { t = A[i]; }
}
Figure 11 — A lastprivate example of supporting conditionally assigned scalars
Here are the language semantics of the new conditional modifier:
- A list item that appears in a conditional lastprivate clause is subject to the private clause semantics. At the end of the
simd construct, the original list item gets the value as if the lexically last conditional assignment happened during scalar execution of the loop. - The item should not be used if its use happens prior to its definition or it’s outside of the definition’s scope.
Loops with Early Exits
The existing simd vectorization in OpenMP 4.5 does not support loops with more than one exit. For example, a common usage such as finding an index of some elements in an array (Figure 12) can’t be explicitly vectorized properly with the existing simd construct.
for (int i = 0; i < n; ++i) {
if (A[i] == B[i]) {
j = i; break;
}
}
// use of j.
int j = 0;
#pragma omp simd early_exit lastprivate(conditional:j)
for (int i = 0; i < n; i++) {
if (A[i] == B[i]) { j = i; break; }
}
// use of j.
Figure 12 — A loop with two exits that is searching for the first equivalent elements of the arrays A[ ] and B[ ]
To address this issue, the Intel Compilers have introduced a new loop-level clause, early_exit, as shown in the right box of Figure 12, with the following semantics:
- Each operation before the last lexical early exit of the loop may be executed as if early exit were not triggered within the
simd chunk. - After the last lexical early exit of the loop, all operations are executed as if the last iteration of the loop was found.
- The last value for
linear and conditional lastprivate is preserved with respect to scalar execution. - The last value for reductions is computed as if the last iteration in the last
simd chunk was executed upon exiting the loop. - The shared memory state may not be preserved with regard to scalar execution.
- Exceptions are not allowed.
- If the innermost loop has an exit out of the
simd construction, execution of the innermost loop is similar to if it had been completely unrolled.
Performance Results
Tables 2 through 4 provide performance results of micro-kernel programs for the monotonic, overlap, and early_exit extensions discussed previously. Performance measurement is done on an Intel® system with preproduction Intel Xeon Scalable processors running at 2.1GHz, in a 2-socket configuration with 24x 2666MHz DIMMs. Actual performance on specific configurations can vary. The loops are the examples shown in previous sections. Loop trip count n is 109, data types are all 32-bit integers, vector length is 16, and the compilation command line is icc –xCORE-AVX512. Baseline is scalar execution of the same set of loops.
Table 2 shows the normalized speedup of vectorized compress and expand idioms. In the "all false" column, compress/expand conditions are all false. Compressing stores or expanded loads are completely skipped. Vector evaluation of the condition, and the reduced number of iterations from vectorization, still lead to 1.17x to 1.19x speedup. For the "all true" column, compress/expand conditions are true; thus, all 16 elements are stored/loaded.
Table 2 — Normalized speedup of compress/expand versus scalar execution. Each column has a different number of true conditions.
In the middle columns, 2, 4, 8, or 15 elements of the 16-way vector are compress stored or expand loaded. This table indicates that regardless of the actual number of elements compressed/expanded, the vectorization of these idiomatic patterns is favorable compared to scalar execution. We ran the same experiment using aligned and misaligned compressed-to/expanded-from arrays. As we expected, trending was very similar between aligned and misaligned cases, except for the "all true" extreme, where the aligned cases have better cache line access characteristics.
Table 3 shows the normalized speedup of the vectorized histogram example. On the left, there is no overlap case, which is running 23 percent slower than scalar execution. Consider finding alternatives where the programmer can assert no-overlaps and thus avoid using overlap extension. Sometimes, choosing a shorter vector length may accomplish that. If conflict resolution is required for vector execution to make sense, other parts of the loop need to be highly profitable to vectorize. It’s interesting to note that the eight repeats and full overlap (16 repeats) cases look more favorable than the cases with fewer repeats. This is likely due to register-based repeats in the vector execution catching up the speed of on-memory dependency over scalar execution. For more information on conflict performance, see reference 9 at the end of this article.
Table 3 Normalized speedup of Histogram versus scalar execution. Each column has a different number of conflicts within one vector iteration.
Table 4 shows the normalized speedup of a vectorized search loop example. From left to right, the loop index value at which the match is found increases from 0 to 5,000. A few vector iterations are needed to achieve visible speedups from vectorization of the search loop.
Table 4 — Normalized speedup of Search relative to scalar execution
It’s important to note that standardization for the explicit vectorization techniques we’ve discussed is still in progress. Syntax, semantics, and performance characteristics may be subject to change in future implementations. Some features may remain as Intel-specific extensions.
Best Practices for AVX-512 Tuning
Setting the Baseline
All tuning work should start by setting an appropriate performance baseline. Tuning for Intel Xeon Scalable processors is no different. Let’s assume that the programmer already has an application reasonably tuned for Intel Xeon processors using the –xCORE-AVX2 flag of Intel Compilers 17.0. We recommend starting from the following three binaries using Intel Compilers 18.0:
- Build the binary with
–xCORE-AVX2 (/QxCORE-AVX2 for Windows) - Build the binary by replacing
–xCORE-AVX2 with –xCORE-AVX512 (/QxCORE-AVX512 for Windows) - Build the binary by replacing
–xCORE-AVX2 with –xCORE-AVX512 –qopt-zmm-usage=high(/QxCORE-AVX512 /Qopt-zmm-usage=high for Windows)
Although we expect overall performance of binary-B and/or binary-C to be on-par or better than binary-A, it’s still best to double-check.
Read Optimization Reports for the Hotspots
Intel compilers produce an optimization report when compilation is performed with –qopt-report (/Qopt-report for Windows). Before trying to change the behavior of the compiler, it’s best to understand what the compiler has done and what it knows already. Article 1 in the References section at the end of this article is a good intro-
duction to using the optimization report. [Editor’s note: Vectorization Opportunities for Improved Performance with AVX-512 also has a good and more current overview of compiler reports.]
Compare Hot Spot Performance
Responses to the different compilation flag combinations can vary from one hotspot to another. If one hotspot runs fast with binary-B and another hotspot runs fast with binary-C, learning what the compiler did for those cases greatly helps in achieving the best for both.
Fine Tuning for ZMM Usage
For binary-B and binary-C, with the OpenMP simd construct, vector length can be explicitly controlled using the simdlen clause. Try using a larger or smaller vector length on a few hot spots to see how application performance responds. You may need to combine one or more tuning techniques.
Alignment
When you’re using Intel AVX-512 vector load/store instructions, it’s recommended to align your data to 64 bytes for optimal performance6, since every load/store is a cache-line split whenever a 64-byte Intel AVX-512 unaligned load/store is performed, given the cache line is 64 bytes. This is twice as much as the cache-line split rate of Intel® AVX2 code that uses 32-byte registers. A high rate of cache-line split in memory-intensive code may cause a 20 to 30 percent performance degradation. Consider the following struct:
struct RGB_SOA {
__declspec(align(64)) float Red[16];
__declspec(align(64)) float Green[16];
__declspec(align(64)) float Blue[16];
}
The memory allocated for the struct is aligned to 64 bytes, if you use this struct as follows:
RGB_SOA rgb;
However, if a dynamic memory allocation is used as follows, the __declspec annotation is ignored and the 64-byte memory alignment is not guaranteed:
RGB_SOA* rgbPtr = new RGB_SOA();
In this case, you should use dynamic aligned memory allocation and/or redefine the operator new. For AVX-512, align data to 64 bytes when possible using the following approaches:
- Use the
_mm_malloc intrinsic with the Intel® Compiler, or _aligned_malloc of the Microsoft* Compiler for dynamic data alignment—e.g.: DataBuf = (float *)_mm_malloc (1024 * 1024 * sizeof(float), 64); - Use
__declspec(align(64)) for static data alignment—e.g.: __declspec(align(64)) float DataBuf[1024*1024];
Data allocation and uses may happen in different subroutines/files. Thus, the compiler working on the data us-age site often does not know that the alignment optimization has been made at the allocation site. __assume_aligned()/ASSUME_ALIGNED is a common assertion to indicate alignment at the data usage site. (See article 2 in the References section of this article and the applicable Intel Compiler Developer Guide and Reference for details.)
To Peel or Not to Peel?
The vectorizer often produces three versions of the same loop:
- One processing the beginning of the loop (called the peel loop)
- One for the main vector loop
- One processing the end of the loop (called the remainder loop)
The peel loop is generated for alignment optimization purposes, but this optimization is a double-edged sword. If the loop trip count is small, it may lower the number of data elements processed by main vector loop. If the compiler chooses a wrong array to peel for, it can worsen the data alignment of the loop execution. The compiler flags –qopt-dynamic-align=F (/Qopt-dynamic-align=F for Windows) can be used to suppress the loop peeling optimization. The pragma vector unaligned can be used on a per-loop basis. The pragma vector aligned is even better if data is all aligned when entering the loop.
Vectorize Peel/Remainder and Short-Trip-Count Loops
The AVX-512 masking allows creation of a vectorized peel and remainder loops and vectorization of the short-trip-count loops. However, the vectorized versions of those special loops may not always result in performance gains, since most of the instructions need to be masked. The main reasons for possible performance problems are restrictions for store forwarding and possible stalls on merge-masked operations, when operation depends on others. In the compiler, the store forwarding issue can be addressed by thorough analysis of data flow and avoiding masking whenever possible. When the store-forwarding issue becomes inevitable, the unmasked version of the loop (e.g., scalar or vectorized loop with a shorter vector length) is preferred. You can avoid stalls on merge-masked operations by trying to use zero-masking operations. The following pragmas make it possible to provide hints to alter the compiler behaviors:
- For remainder loops:
#pragma vector novecremainder, to not vectorize remainder loops
#pragma vector vecremainder, to vectorize remainder loop depending on compiler cost model
#pragma vector always vecremainder, to vectorize remainder loop always - For short-trip-count loops:
#pragma vector always, to enforce vectorization
#pragma novector, to disable vectorization
Gather and Scatter Optimization
The gather and scatter instructions allow us to vectorize more loops. However, the vectorized code may or may not get performance benefits. The performance of loops that contain gather/scatter code depends on the ratio between the number of calculations and the number of data loads/stores and on selecting an optimal vector length for reducing the latency of gather and scatter instructions. A shorter vector length implies less latency of gather/scatter code. Often, a couple of simple optimizations at the source code level can help reduce the number of gather and scatter instructions.
Figure 13 shows the two simple manual gather/scatter optimizations while the compiler is trying to automatically perform these optimizations. The first optimization is to reduce number of gathers/scatters when the results of two gathers/scatters are blended as shown on the left. In this case, blending the indices makes it possible to have one gather instead of two as shown on the right. Note that we can apply the same process to scatter optimization.
The second gather/scatter optimization is an opposite transformation (Figure 14). In this case, a gather is performed with indices resulting from blend of unit-stride linear indices as shown on the left. To improve performance, it’s better to perform two unit-stride loads and then do the blend as shown on the right.
// Two gathers in the loop
float *a, sum = 0; int *b, *c;
… …
for (int i; i < n; i++) {
if ( pred(x[i]))
sum += a[b[i]]; // gather
else
sum += a[c[i]]; // gather
}
// Optimized with one gather in the loop
for (int i; i < n; i++) {
int t;
if ( pred(x[i]))
t = b[i];
else
t = c[i];
sum += a[t]; // one gather remain
}
Figure 13 — Reducing gathers in the loop
// One gather in the loop
float *a, sum = 0; int a;
for (int i; i < n; i++) {
int t;
if (pred(x[i])) {
t = i + b;
}
else {
t = i;
}
sum += a[t]; // gather
}
// Replace gather with unit-stride loads + blending
for (int i; i < n; i++) {
float s;
if ( pred(x[i])) {
s = a[i + b]; // unit stride vector load
}
else {
s = a[i]; // unit stride vector load
}
sum += s;
}
Figure 14 — Reducing gathers with two unit-stride loads + blend in the loop
Execution Latency Improvement
For loop vectorization, a known issue for compilers is that the loop trip count is unknown at compile time. However, programmers can often predict the trip count and provide a hint to the compiler using #pragma loop count. In some cases, the loop trip count can be predicted approximately based on #pragma unroll information as well. Preferably, the unroll pragma should be used on loops with small enough bodies to decrease number of loop iterations and to increase loop iteration independency, so they can be executed in parallel on out-of-order Intel® architectures to hide execution latency. Loop unrolling is very helpful for computation-bounded loops (i.e., when the computation takes more time than memory accesses). For example, the loop shown in Figure 15 will execute about 45 percent faster when the unroll-factor (UF) is set to 8 compared to a UF equal to 0. The measurement was done for n=1,000.
float *a,*b, *c;
#pragma unroll(8)
#pragma omp simd
for (i= 0; i < n; i++) {
if (a[i] > c[i]) sum += b[i] * c[i];
}
Figure 15 — Reducing latency using simd + unroll(8)
Summary and Future Work
We’ve looked at several new simd language extensions for Intel AVX-512 support in Intel Compilers 18.0 for Intel Xeon Scalable processors. We shared and discussed a set of performance optimization and tuning practices for achieving optimal performance with AVX-512. We provided performance results based on microkernels to demonstrate the effectiveness of these new simd extensions and tuning practices. In the future, there are several new simd extensions for C/C++ under consideration for taking full advantage of AVX-512 through OpenMP and the C++ Parallel STL, including inclusive-scan, exclusive-scan, range-based C++ loops, and lambda expression support.
Learn More
#CodeModernization
References
- M. Corden. "Getting the Most out of your Intel® Compiler with the New Optimization Reports," Intel Developer Zone, 2014.
- R. Krishnaiyer. "Data Alignment to Assist Vectorization," Intel Developer Zone, 2015.
- H. Saito, S. Preis, N. Panchenko, and X. Tian. "Reducing the Functionality Gap between Auto-Vectorization and Explicit Vectorization." In Proceedings of the International Workshop on OpenMP (IWOMP), LNCS9903, pp. 173-186, Springer, 2016.
- H. Saito, S. Preis, A. Cherkasov, and X. Tian. "Obtaining the Last Values of Conditionally Assigned Privates," OpenMPCon Developer Conference, 2016.
- H. Saito, "Extending LoopVectorizer: OpenMP4.5 SIMD and Outer Loop Auto-Vectorization," presentation at LLVM Developer Conference, 2016.
- X. Tian. H. Saito, M. Girkar, S. Preis, S. Kozhukhov, A. Duran. "Putting Vector Programming to Work with OpenMP* SIMD," The Parallel Universe magazine, Issue 22, September 2015.
- X. Tian, R. Geva, B. Valentine. "Unleash the Power of AVX-512 through Architecture, Compiler and Code Modernization," ACM Parallel Architecture and Compiler Technology, September 11-15, 2016, Haifa, Israel.
- X. Tian, H. Saito, M. Girkar, S. Preis, S. Kozhukhov, A. G. Cherkasov, C. Nelson, N. Panchenko, R. Geva. Compiling C/C++ SIMD Extensions for Function and Loop Vectorizaion on Multicore-SIMD Processors. IEEE IPDPS Workshops 2012: 2349-23
- Intel Corporation. "Conflict Detection" In Section 13.16 of Intel® 64 and IA-32 Architectures Optimization Reference Manual, July 2017.

