This article shows how to extend the accompanying source code to create and test your own implementation of the basic four arithmetic operations.
This article is part of a series of articles:
Multiple Precision Arithmetic: A recreational project
Introduction
In this article, I am going to review the code accompanying this series of articles.
The repo (link above, a snapshot of the code is attached to the article for future reference, because links tend to break) contains two implementations: the big one is "C" language version + some x64 assembler code, the small one is a JavaScript prototype, made to be as simple as possible, that I even use as a debug tool to verify the correctness of the big implementation.
C code is not written to be an usable API, it just contains core algorithms, it is “study” code, apotheosis of recreational programming, which could be polished and used as a working but poor featured API, of course, but I think it does not make any sense to create a new API since there are a lot of existing high performance feature rich MP API, like the GMP or the like, made by highly rated professional mathematicians.
This program is more a “compiled script” than a real program: compile it and run! Its output only depends on the speed of the executing computer: same output on the same computer for each run. Once you collected output data for analysis, you can throw away the executable.
To change the output on the same machine: edit the source code, recompile and run… in this sense, it is more like a script than a program.
The whole sense of the thing is being able to edit the code and recompile it to find newer outputs, to enrich the code and the personal culture as a programmer. If somebody feels like using parts of the code in real life? Why not!
The program outputs diagnostic messages to stderr and results to stdout as a tab separated file.
Here's the output tab separated file as loaded by R-Studio:
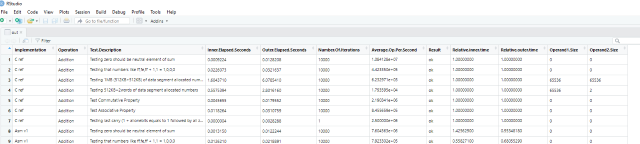
Same file loaded by Excel:

Program Usage
C Version
After having compiled the code, run the program redirecting standard output to a txt file:
After some minutes (or more… tests are not executed in parallel), you could open the txt file for your analysis using r-studio, Excel or any other tool.
Example: Comparing implementation speed of division by operand2_size using a pivot bar chart:
JavaScript Version
The JS implementation is more “real” than the “big program”, in the sense that it can accept input and produce output based on input, but of course, performance cannot be compared.
To open JS implementation, look into the sources directory and open the BigIntSimple/wwwroot/default.html, that page is something for which using the "spartan" adjective is just appropriate. Being created with best practices on UX usability (LOL) its usage should be self-explanatory.
Here is an example multiplication made on base 10, interestingly it shows intermediate steps which can be useful when debugging the big implementation, especially if set to use base16, but honestly, to multiply numbers of size 2KWords, it is quite hard with that tool.
Here a base 16 example of a division:
Portability Issues
The core of the program is written using portable STD “C”, but some parts are not.
Assembler Language
“C” code on the project is somewhat portable, but assembler code is less, if you don’t have an assembler or your assembler does not support x64 intel syntax, or your architecture is different, get rid of the ASM code: the linker will complain about missing code, you should then work out what code to remove in order to let the C code to compile. The assembler part is an "add-on" and can be removed safely, except that you may need to redefine some small parts on pure "C" code.
Non Portable C Code
Even some C parts are not portable, I added some guards and where possible, I added some fallback portable routines, for example, the high definition clock routines are implemented like this:
test.h
#if defined(_WIN32) || defined(WIN32)
#include <Windows.h>
#define CLOCK_T unsigned long long
#undef FAILED
#undef BitScanReverse
#else
#warning maybe you want to define a better CLOCK_T for your platform,
#also checkout test_common.c
#define CLOCK_T clock_t
#endif
test_common.c
#if defined(_WIN32) || defined(WIN32)
CLOCK_T precise_clock() {
unsigned long long o;
if (QueryPerformanceCounter((LARGE_INTEGER*) &o) != 0){
return o;
}
return clock_zero();
}
double seconds_from_clock(CLOCK_T clock){
unsigned long long o;
if (QueryPerformanceFrequency(
(LARGE_INTEGER*)&o
) == 0)return 0.0;
double d = (double)(clock) /(double)o;
assert(d > 0);
return d;
}
CLOCK_T clock_zero() {
return 0ULL;
}
#else
#warning maybe you want to define a better clock function
CLOCK_T precise_clock() {
return clock();
}
double seconds_from_clock(CLOCK_T clock){
return clock / CLOCKS_PER_SEC;
}
CLOCK_T clock_zero(){
return 0L;
}
#endif
Compiler should raise a warning giving you the opportunity to write the non-portable part.
Project Structure
I used MS VC++ compiler, so the repo has a VC++ project file. Compiling all the *.c files and *.asm into a single executable should be just fine if you don't use MSVC++.
Typedef reg_t so that it Corresponds to the Target Platform Native Unsigned WORD
On each platform, you should check some typedefs, check out BigIntSimple.h and test.h for some platform specific, see the following excerpt of BigIntSimple.h.
#define _R(a) ((reg_t)(a ## L))
typedef uint32_t numsize_t;
typedef uint64_t reg_t;
typedef int _result_t;
#define NO_DWORD_INTS
typedef uint32_t multiply_small;
typedef uint64_t multiply_big;
Below is some example part from test.h which is not portable:
#define NOMEM L"NO MEMORY"
#define _fprintf fwprintf
#define _sprintf swprintf
typedef wchar_t _char_t;
#define STR(x) L ## x
#define EXPAND_(a) STR(a)
#define WFILE EXPAND_(__FILE__)
#define LOG_INFO(x, ...) _fprintf(stderr, L"[INFO] " x L"\n", ##__VA_ARGS__)
#define MY_ASSERT(c, x, ...) if (!(c))
{ _fprintf(stderr, L"assertion failed: (%s %d) - " x L"\n",
WFILE, __LINE__, ##__VA_ARGS__); abort(); }
#define LOG_ERROR(x, ...) _fprintf(stderr, L"[ERROR] " x L"\n", ##__VA_ARGS__)
Other Stuff
Sorry but I did not have time to try to compile this into any Linux Box, it’s my fault and for sure I will do that, but I have very little time to dedicate to this project.
Using the Code
The Arithmetic Challenge
Now I challenge you to create your “C” implementation of one or more of the four basic operations and try to have a run time faster than the ref implementation, I know it is possible to do way better than I did.
The prize is nothing, enjoy.
I encourage the mighty volunteers to use any non-portable/exotic hardware specific, parallel, GPU, vector, any micro-optimization trick to beat ref implementation. It would be nice to see some usage of intrinsics and maybe compare output from different compilers on same machine.
I'd like to see different algorithms at work, and I have some intention to create a different algorithm that I will add (as you may notice from my commits, I seldom work on this) like some parallel version of algorithms, better multiplication algorithms, output as decimal strings, division optimized for a single digit and more.
Of course, we will compare algorithms by asymptotic complexity category.
Important Things to Know Before Adding a New Arithmetic Algorithm
The Positional System Used
Choosing a number representation affects a lot how the algorithm is going to work and the arithmetic to use, for example, one could decide to use a negative base, or a positive base with signed digits, but this is still too complicated for me. I decided to work with a positive base and positive digits (only implement unsigned arithmetic). With very little effort, the code can be extended to represent negative numbers. Of course, this may be a problem if the underlying computer does not have instructions to handle register sized unsigned digits, but AFAIK all main architectures support unsigned arithmetic.
In this project, numbers are represented as strings of unsigned digits, each digit has base 2(8*sizeof(reg_t)) (consider typedef reg_t correctly for your platform for optimal performance), the least significant digit is at position 0. The size of a string is always provided as a separated unsigned integer value of type numsize_t, that is good to be defined as:
typedef uint32_t numsize_t;
but if you feel uint32_t is too small, feel free to user larger values.
Zero
Zero is represented by passing a size value of zero, regardless of the content of the A array (which can then be NULL in this case). Also, a number having size K and K digits equals to 0 is equal to zero but it requires to scan the number, so any API code that wraps this number system should normalize the zeroes in order to have only one possible representation of zero.
If you need to build a full arithmetic API around this code, you could define numbers as a struct like that:
struct BigUnsignedInteger
{
numsize_t magnitude;
reg_t* data;
};
struct BigInteger
{
char sign;
numsize_t magnitude;
reg_t* data;
};
struct BigRational
{
char sign;
struct BigUnsignedInteger p;
struct BigUnsignedInteger q;
};
etc.
Other Important Things to Know Before You Proceed to Implementation
On the source header files, there are two kinds of operation signatures and different calling conventions.
Sum, Subtraction and Multiplication Signature
EXTERN numsize_t YourOperation(reg_t * A, numsize_t ASize,
reg_t * B, numsize_t BSize, reg_t* R);
On all three cases A is a number, ASize is size of A; B the second number, BSize its size; R the preallocated (from the caller) space to store the result (the numbers are represented as per the above paragraph “The positional System Used”).
Sum/Subtraction Calling Conventions
The convention is that for sum and subtraction, the caller passes the R array as an already allocated array having a capacity of at least MAX(Asize, BSize)+1, as you receive the R array in input you must consider its value as undefined, before returning from your implementation, you should always set it to the result, if the result is zero, then your implementation returns zero and you can leave the content of R undefined, otherwise you must return the number of significant digits (of base 2(8*sizeof(reg_t)) ) and set R values accordingly.
On subtraction, if B is bigger than A the result is undefined, you do not have to check that A>=B, that's the responsibility of the caller, you need to be as fast as possible here: this is one of the reasons this function could be wrapped into some other in order to build an eventual API.
It is not required for the implementation, but some Sum and Subtraction algorithms MAY be able to work in place, so for example, R could point to the same array as A or B; this could be useful if you intend to reuse your sum / sub routine as a subroutine for multiplication or division to save you the need of having extra buffers around, but that’s not required.
Multiplication Calling Convention
In multiplication, the caller must pass the R array allocated and having capacity of ASize + Bsize. As you receive R in input, you must consider its value as not defined, if your implementation needs R to be filled with zeros, your implementation must do it.
Division Signature
_div_result_t LongDivision(reg_t *A, numsize_t m, reg_t *B, numsize_t n, reg_t * Q,
numsize_t * q, reg_t * R, numsize_t * r);
This signature is slightly more complex because we need to signal DIVIDE_BY_0 or other possible error situation: sum, sub and mul do not need to allocate any additional space (well multiplication will sometimes need to allocate but can fallback to other slower algorithms which does not need extra buffer space).
So we have A and its size m, B and its size n, Q the space dedicated to store the result and q, the place where to store the output q size, R the space dedicated to store the remainder, r the place where to store the remainder size.
The caller must guarantee A to have a capacity m+1 and B to have capacity n, this way your implementation is free to shift B to left of some bit position until its first bit at left become 1, because normalizing B lets your algorithm to work better, your implementation must be as fast as possible so you don't want to allocate things or complicate your algorithm, better to give responsibility for this to the caller, of course, a hypothetical API should wrap numbers in a way that this constraint will be transparent to users .
The caller guarantee that Q be large enough to hold the result, that is at least m-n+2 digits of space (2 because of possible shifts).
The caller also guarantees that R be large enough to contain the remainder so it must be as large as n digits.
Create Your Own Arithmetic Algorithm
Working by example, let’s create an example new multiplication algorithm: the same procedure applies to sum, sub and div.
- Edit the BigIntSimple.h file and add the signature for your super-fast multiplication algorithm.
numsize_t MySuperFastMultiplication
(reg_t* A, numsize_t m, reg_t* B, numsize_t n, reg_t* R);
- Then add a new .c file to the project where you will implement the multiplication, add it to the project, then add the following code:
#include "BigIntSimple.h"
numsize_t MySuperFastMultiplication
(reg_t* A, numsize_t m, reg_t* B, numsize_t n, reg_t* R)
{
return 0;
}
- Edit the test_config.c file and insert your algorithm to the list of multiplication algorithm (search for the initialization of multiplications):
static _operationdescriptor multiplications [] =
{
{
STR("C ref"),
OP,
LongMultiplicationV2,
{0,0,NULL}
},
{
STR("My super fast multiplication"),
OP,
MySuperFastMultiplication,
{0,0,NULL}
},
};
That’s it!
Now compile and run the program.
Here is an excerpt of the STDERR output, of course, tests are failing because we always return 0 on our super-fast multiply (but it passes the test that A*0 must be equals 0, and it have also the commutative and associative property.😊)
And here is how a sample Excel chart looks like:
Wow the “my super fast multiplication” is really fast, it takes 0 seconds against 8 on 32Kwords operands… but the problem is that the “my super fast algorithm” is not working… it needs implementation.
Debugging Your Implementation
You can debug it as you want but I suggest to do like that: comment all the other multiplication algorithms on test_config.c except your and the reference one, and on the main function, comment all test cases except the one for the operation you are working on:
int main(){
setlocale(LC_ALL, "");
initTest();
testMul();
write_summary();
return 0;
}
Adding New Unit Tests
If you need additional unit tests, you can add as many as you want, follow the manual on the git repo for suggestions, or do whatever you want instead: https://github.com/andreasimonassi/bigint/blob/master/BigIntSimple/creating_unit_tests_readme.md
History
- May 2020: First release
- 11th June, 2022: Published online

