Here we look at a brief introduction to reinforcement learning, training the cartpole environment, and retrieving the video in a remote notebook.
Welcome to the first in a series of articles about reinforcement learning. Reinforcement Learning is a powerful tool that helps machine learning algorithms to achieve positive outcomes, from autonomous vehicles to stock trading. In this series, we’ll use reinforcement learning to teach a neutral network how to master a Breakout-style game.
Some prior familiarity with machine learning is assumed. It’s not strictly necessary, but I won’t be explaining underlying concepts, such as neural networks, in any depth here. I also assume you have some experience with Python 3, and how to manage your virtual environments and add packages.
A Brief Introduction to Reinforcement Learning
First, some definitions:
- Environment – the arena in which learning is to take place, such as a space invaders game or a robot arm
- Observation – some measurement of an environment’s state (possibly noisy or incomplete)
- Reward – a bonus or penalty awarded to you by the environment, such as the score you get for shooting a space invader
- Agent – an entity making observations about its environment, taking actions within it, and gaining rewards based on those actions
- Policy – the rules that tell an agent how to act
Armed with the above glossary, we can say that reinforcement learning is about training a policy to enable an agent to maximise its reward by taking optimal actions in its environment. Note that "do nothing" is often one of the available actions.
Typically, we want to use a framework to bring together all the required components and simplify the task of running experiments. Some popular RL frameworks are Garage, Dopamine, and RLlib. We’ll be using RLlib.
Running the Code
By the end of this article, you should be up and running, and would have done your first piece of reinforcement learning.
There are a few different options available to you for running your code:
- Run it on your local machine. This can be a good option if you already have a Python environment set up, especially if it has a GPU. Even if you don’t, tools such as Anaconda can greatly simplify the setup process. Some of the training sessions will take a long time (hours to days), and will hog your machine’s resources. If you’re running Windows, you’ll have to run the code using WSL2, as RLib’s native Windows support is still in progress. It’s worth it - RLib is the best tool for reinforcement learning.
- Run it on a remote computer. You will have to pay for this; however, with the various suppliers charging by the hour, it need not be expensive. This approach gives you lots of flexibility about how many CPU cores and GPUs you want.
- Run it in a hosted Jupyter Notebook. Hosted notebooks are backed by virtual machines (so you can install extra software), optionally with GPUs. Some of these services are free, although these usually have limited allowed runtime, which is fine for training simple models. Options include Google Colab, Paperspace Gradient Notebooks, and Azure Notebooks.
We will be using the Ray project’s RLlib framework. To enable RLlib record videos of the training progress on systems with no GUI, you can install a virtual display. I used the following commands in both remote Linux terminals and hosted notebooks (starting each line with an exclamation mark in the latter case):
apt-get install -y xvfb x11-utils
pip install pyvirtualdisplay==0.2.* PyOpenGL==3.1.* PyOpenGL-accelerate==3.1.*
Then, in the Python file/notebook:
import pyvirtualdisplay
_display = pyvirtualdisplay.Display(visible=False, size=(1400, 900))
_ = _display.start()
Training the Cartpole Environment
We’ll be using OpenAI Gym to provide the environments for learning. The first of these is the cartpole. This environment contains a wheeled cart balancing a vertical pole. The pole is unstable and tends to fall over. The agent can move the cart in response to observations about the state of the pole, and gets rewarded based on the length of time for which the pole is balanced without falling.
The overall framework we will be using is Ray/RLlib. Installing this (for example, with pip install ray[rllib]==0.8.5 or via Anaconda) will bring in its dependencies, including OpenAI Gym.
Perhaps the best thing to do with each new environment is to fire it up and take a look. If you are running an environment with a graphical display, you can "play" the environment directly:
import gym
from gym.utils.play import play
env = gym.make("CartPole-v0")
play(env, zoom=4)
We’re going to dive straight into training an agent to solve this environment. We’ll wait until the next article before digging into the details.
import ray
from ray import tune
from ray.rllib.agents.dqn import DQNTrainer
ray.shutdown()
ray.init(
include_webui=False,
ignore_reinit_error=True,
object_store_memory=8 * 1024 * 1024 * 1024
)
ENV = 'CartPole-v0'
TARGET_REWARD = 195
TRAINER = DQNTrainer
tune.run(
TRAINER,
stop={"episode_reward_mean": TARGET_REWARD},
config={
"env": ENV,
"num_workers": 0,
"num_gpus": 0,
"monitor": True,
"evaluation_num_episodes": 25,
}
)
You should see lots of output. The last line of each batch shows the status, including the mean reward earned. We continue training until this reward reaches the environment’s target of 195. Progress is not linear, so the reward might edge teasingly close to the target before falling back again. Have patience; it should get there before too long. It took less than 15 minutes on my computer.
195? Congratulations! You now have trained your first reinforcement learning model!
We told Ray to store snapshots of progress, which it will have put in ray_results inside your home directory. You should see many mp4 videos. If you are running in a hosted notebook, see the next section; otherwise, you can skip it.
Retrieving the Video in a Remote Notebook
The video files should have been created but there is no easy way to view them. I wrote some helper code that works around this:
from base64 import b64encode
from pathlib import Path
from typing import List
OUT_PATH = Path('/root/ray_results/')
def latest_experiment() -> Path
experiment_dirs = []
for algorithm in OUT_PATH.iterdir():
if not algorithm.is_dir():
continue
for experiment in algorithm.iterdir():
if not experiment.is_dir():
continue
experiment_dirs.append((experiment.stat().st_mtime, experiment))
return max(experiment_dirs)[1]
def latest_videos() -> List[Path]:
return list(sorted(latest_experiment().glob('*.mp4')))
def render_mp4(videopath: Path) -> str:
mp4 = open(videopath, 'rb').read()
base64_encoded_mp4 = b64encode(mp4).decode()
return f'<p>{videopath.name}</p><video width=400 controls>
<source src="data:video/mp4;base64,{base64_encoded_mp4}" type="video/mp4"></video>'
Adding this to a notebook cell should cause it to render the most recent video.
from IPython.display import HTML
html = render_mp4(latest_videos()[-1])
HTML(html)
Inspecting the Results
If you play the most recent video, representing the end of the training, it should look like this:
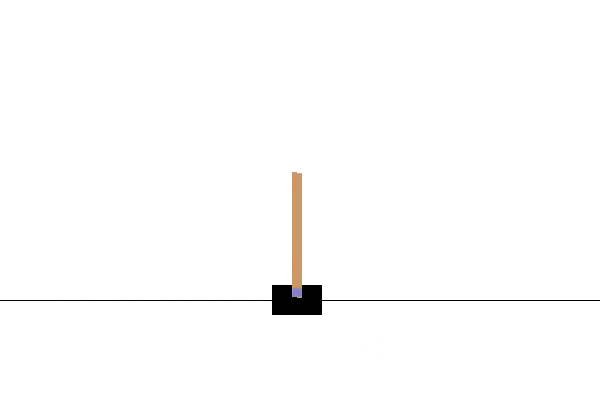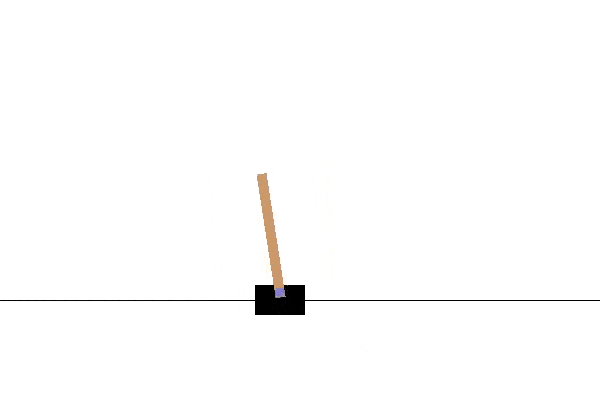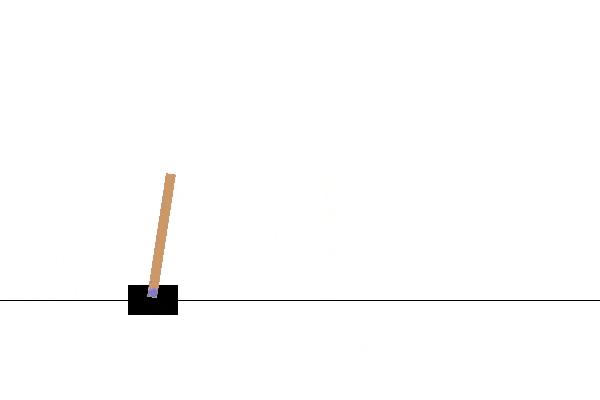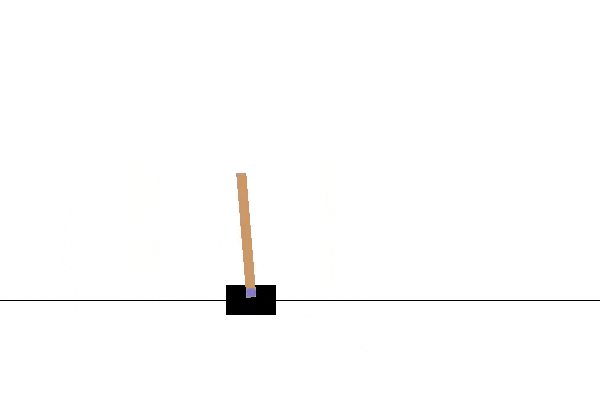
In the next article, we will see what’s going on behind the scenes and what options are available for changing the learning.
History
- 25th June, 2020: Initial version

