The Atari game environments are available in two fundamentally different versions: the standard, one and the version which yields observations in terms of what is going on in the computer memory. Here we look at this second version.
In the earlier articles in this series, we looked at the classic reinforcement learning environments: cartpole and mountain car. For the remainder of the series, we will shift our attention to the OpenAI Gym environment and the Breakout game in particular.
The game involves a wall of blocks, a ball, and a bat. If the ball hits a block, you get some score and the block is removed. You have to move the bat at the bottom of the screen to avoid the ball going out of play, which would cause you to lose one of the five lives.
Naming Conventions for the Atari Environments
Because I found naming conventions for the Atari environments somewhat confusing, I thought it was worth briefly explaining them here.
The environment names include a version and a suffix.
Version:
- v0 has a repeat action probability of 0.25, meaning that a quarter of the time the previous action will be used instead of the chosen action. These so-called sticky actions are a way of introducing stochasticity into otherwise deterministic environments, largely for benchmarking.
- v4 always performs the chosen action.
- There are no versions 1, 2, or 3for Breakout.
Suffix:
- No suffix: skip 2, 3 or 4 frames at each step, chosen at random each time
- Deterministic: skip 4 frames at each step
- NoFrameskip: skip 0 frames at each step
In practice, I didn’t find that the frame-skipping options made a lot of difference. That’s probably because most of the runs used DQN with an experience buffer, so you’re effectively just pumping four similar experiences into the pool but not learning from them straight away. It might be that using the Deterministic environment would allow you to achieve the same results with a smaller buffer but not necessarily learn faster.
Graphics vs RAM
The Atari game environments are available in two fundamentally different versions. The standard, and by far the more commonly used, versions provide their observations in terms of pixels on the screen. At each step, you observe an array of uint8 values of shape (210, 160, 3), representing the red, green and blue values for each pixel. The second version yields observations in terms of what is going on in the computer memory. Atari 2600, which is what is simulated to enable these environments, had only 128 bytes of RAM. Not 128K, 128 bytes!
We will be trying to solve both types of Atari environment in this series. We will start with the more straightforward and better-studied version: learning from what’s happening on the screen.
Learning Breakout From Pixels
Here is the code I used for learning from pixels:
import pyvirtualdisplay
_display = pyvirtualdisplay.Display(visible=False, size=(1400, 900))
_ = _display.start()
import ray
from ray import tune
from ray.rllib.agents.dqn import DQNTrainer
ray.shutdown()
ray.init(
include_webui=False, ignore_reinit_error=True,
memory=4000 * 1024 * 1024,
object_store_memory=400 * 1024 * 1024,
driver_object_store_memory=200 * 1024 * 1024)
ENV = "BreakoutNoFrameskip-v4"
TARGET_REWARD = 200
TRAINER = DQNTrainer
tune.run(
TRAINER,
stop={"episode_reward_mean": TARGET_REWARD,
config={
"env": ENV,
"num_gpus": 0,
"monitor": True,
"evaluation_num_episodes": 25,
"num_workers": 0,
"double_q": True,
"dueling": True,
"num_atoms": 1,
"noisy": False,
"prioritized_replay": False,
"n_step": 1,
"target_network_update_freq": 8000,
"lr": .0000625,
"adam_epsilon": .00015,
"hiddens": [512],
"learning_starts": 20000,
"buffer_size": 400_000,
"rollout_fragment_length": 4,
"train_batch_size": 32,
"exploration_config": {
"epsilon_timesteps": 500_000,
"final_epsilon": 0.01,
},
"prioritized_replay_alpha": 0.5,
"final_prioritized_replay_beta": 1.0,
"prioritized_replay_beta_annealing_timesteps": 2_000_000,
"timesteps_per_iteration": 10_000,
}
)
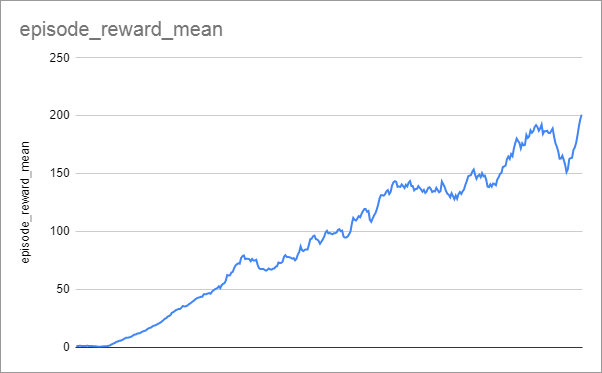
Note that with this configuration it took 36 hours to reach the performance of 200 on a single CPU core with no GPU. This does show that you can try your hand at reinforcement learning without expensive hardware, as long as you have the patience.
The training progress was relatively linear:
In the next article, we will see how you can use a different learning algorithm (plus more cores and a GPU) to train much faster on the mountain car environment. If you are following along, you might not want to wait for the simple approach to fully train before continuing.

