Here we look at: Inspecting the environment, an overview of Ray’s Architecture, and using Impala for learning Breakout more quickly.
The previous article introduced the OpenAI Gym environment for Atari Breakout, together with some code for training an agent to solve it using reinforcement learning.
Now we are going to take a closer look at the details of this environment, and use a more sophisticated algorithm to train an agent on it much quicker.
Inspecting the Environment
You can use the following simple Python code to play the game interactively (and, it has to be said, more slowly than usual). The keys you need are A for left, D for right, and Space to launch the ball. This will only work if you’re in an environment with a real graphical display; otherwise, you can just read this bit.
import gym
from gym.utils.play import play, PlayPlot
def callback(obs_t, obs_tp1, action, rew, done, info):
return [rew]
plotter = PlayPlot(callback, 30 * 5, ["reward"])
env = gym.make("Breakout-ramNoFrameskip-v4")
play(env, callback=plotter.callback, zoom=4)
We use a callback function to show the reward received over time. As you can see, we get no reward except when the ball hits and removes a brick. There is no negative reward for losing a life.
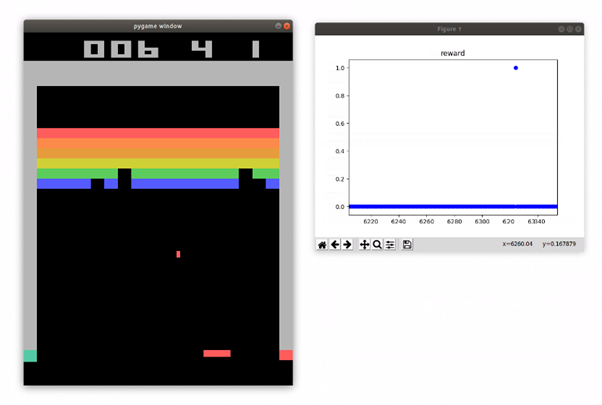
Several things aren’t apparent from this screenshot:
- You get a higher reward for knocking out bricks in the higher levels
- After a while, the bat gets smaller
- The velocity of the ball varies a great deal
So, a few challenges for an agent to overcome!
Overview of Ray’s Architecture
Since we are inspecting things, this is a good opportunity to have a brief overview of Ray’s architecture and, in particular, the things we might like to tweak to change its performance. In the previous article, we ran on a single CPU; this time we are going to make use of more cores and a GPU.
The architecture of Ray consists of one trainer and zero or more external worker processes, which feed back batches of observations. Each worker can run one or more environments, based on what you have configured.
Here are some of the common parameters you can change to affect performance and scaling:
num_cpus_per_worker: the number of CPUs each worker is allowed to use; there’s no benefit to this being more than one for any of the standard environments, but it might be useful if you have an expensive custom environmentnum_envs_per_worker: the number of environments spun up by each worker processnum_gpus: the total number of GPUs to use for trainingnum_gpus_per_worker: the number of GPUs to use per worker, typically zeronum_workers: the number of worker processesrollout_fragment_length: the number of observations to take from each environment before a worker sends it back to the trainertrain_batch_size: the number of observations in each batch when training the policy
Using Impala for Learning Breakout More Quickly
The following code sets up seven Ray workers, each running five Breakout environments. We are also switching to use the IMPALA algorithm instead of DQN.
import ray
from ray import tune
from ray.rllib.agents.impala import ImpalaTrainer
ray.shutdown()
ray.init(include_webui=False, ignore_reinit_error=True)
ENV = "BreakoutNoFrameskip-v4"
TARGET_REWARD = 200
TRAINER = ImpalaTrainer
tune.run(
TRAINER,
stop={"episode_reward_mean": TARGET_REWARD},
config={
"env": ENV,
"monitor": True,
"evaluation_num_episodes": 25,
"rollout_fragment_length": 50,
"train_batch_size": 500,
"num_workers": 7,
"num_envs_per_worker": 5,
"clip_rewards": True,
"lr_schedule": [
[0, 0.0005],
[20_000_000, 0.000000000001],
]
}
)
Using eight CPU cores and a GPU, this took about 0.6 hours to train to the score of 200. Much quicker than the DQN model we used in the previous article.
Progress wasn’t exactly linear. In particular, it had a very wobbly moment towards the end, where the mean score dropped right back.

Having learned to solve the Breakout environment in half the time, you might think we are done with it. But no, this is only half the battle. Learning Breakout from RAM, instead of from pixels, throws up some interesting challenges, as we will discover in the next article.

