Programmers with so little memory to use were accustomed to coming up with all sorts of neat tricks to pack as much information into the space as possible. So in this article we will be learning from RAM, and learning from a subset of the RAM.
In the previous article, we used RLlib’s IMPALA agent to learn the Atari Breakout environment from pixels in a respectable time.
Here, we will take it one step further and try to learn from the contents of the game’s RAM instead of the pixels.
As a software engineer, I expected the RAM environments to be easier to learn. After all, it seems likely that one location in memory would hold the x-coordinate of the bat, and two more would hold the position of the ball. If I was trying to write some code to play this game, and wasn’t using machine learning, that’s probably where I’d want to start. If forced to use graphics, I’d just process them to extract this information anyway, so surely it’s simpler to skip right over that step.
Turns out I was wrong! It’s easier to learn from the images than from the RAM. Modern convolutional neural network architectures are good at extracting useful features from images. In contrast, programmers with so little memory to use were accustomed to coming up with all sorts of "neat tricks" to pack as much information into the space as possible. One byte might represent a number, or two numbers, of four bits each, or eight flags...
Learning From RAM
Here is the code I used:
import ray
from ray import tune
from ray.rllib.agents.dqn import DQNTrainer
ray.shutdown()
ray.init(include_webui=False, ignore_reinit_error=True)
ENV = "Breakout-ramDeterministic-v4"
TARGET_REWARD = 200
TRAINER = DQNTrainer
tune.run(
TRAINER,
stop={"episode_reward_mean": TARGET_REWARD},
config={
"env": ENV,
"monitor": True,
"evaluation_num_episodes": 25,
"double_q": True,
"hiddens": [128],
"num_workers": 0,
"num_gpus": 1,
"target_network_update_freq": 12_000,
"lr": 5E-6,
"adam_epsilon": 1E-5,
"learning_starts": 150_000,
"buffer_size": 1_500_000,
}
)
This is the progress up to the point where I stopped the process:
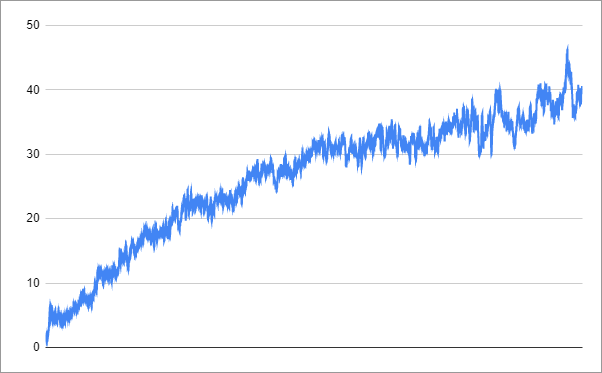
This is not a great success. I let the training run for 54 hours to achieve the score of 40. So it had learnt something, and the graph suggests it was continuing to improve, but progress was very slow. In the next article, we will see how to do better.
Learning From a Subset of the RAM
It is tempting to think that, even though Atari has only 128 bytes of memory, many of the stored values are just noise. For example, somewhere in there would be the player’s current score, and using this as an input feature won’t help the learning.
So I tried to identify a subset of bits that carry useful information. By logging the observations and seeing which ones seemed to be changing meaningfully (that is, had lots of distinct values over the first hundred timesteps), I picked out the following column indexes as "interesting": 70, 71, 72, 74, 75, 90, 94, 95, 99, 101, 103, 105, and 119.
Here is the code I used for training a model using only these values. I switched over to using the PPO algorithm because it seemed to perform a bit better than DQN.
The interesting part is the TruncateObservation class, which simplifies the observation space from 128 bytes down to 13.
import pyvirtualdisplay
_display = pyvirtualdisplay.Display(visible=False, size=(1400, 900))
_ = _display.start()
import ray
from ray import tune
from ray.rllib.agents.ppo import PPOTrainer
ray.shutdown()
ray.init(include_webui=False, ignore_reinit_error=True)
import numpy as np
import gym
from gym.wrappers import TransformObservation
from gym.spaces import Box
from ray.tune.registry import register_env
from gym import ObservationWrapper
class TruncateObservation(ObservationWrapper):
interesting_columns = [70, 71, 72, 74, 75, 90, 94, 95, 99, 101, 103, 105, 119]
def __init__(self, env):
super().__init__(env)
self.observation_space = Box(low=0, high=255, shape=(len(self.interesting_columns),), dtype=np.uint8)
def observation(self, obs):
return obs[self.interesting_columns]
def env_creator(env_config):
env = gym.make('Breakout-ramDeterministic-v4')
env = TruncateObservation(env)
return env
register_env("simpler_breakout", env_creator)
ENV = "simpler_breakout"
TARGET_REWARD = 200
TRAINER = PPOTrainer
tune.run(
TRAINER,
stop={"episode_reward_mean": TARGET_REWARD},
config={
"env": ENV,
"num_workers": 1,
"num_gpus": 0,
"monitor": True,
"evaluation_num_episodes": 25
}
)
The learning performance looked like this:

It achieved the score of 42 after 27 hours of training, at which point I stopped the process. This looks more promising than trying to train on all the bytes. Let me know in the comments if you manage to do better than this with a slightly different subset of memory locations. For example, "Learning from the memory of Atari 2600" by Jakub Sygnowski and Henryk Michalewski calls out memory locations 95 to 105 as particularly influential.
In the next article, we will see how we can improve by approaching the RAM in a slightly different way.

