Here we will look at: Learning From individual bits, looking at code which provides a custom observation wrapper, which uses NumPy’s unpackbits function to explode the incoming observation of 128 bytes into an observation of 1024 bytes.
In the previous article, we continued our exploration of learning the Atari Breakout environment by training an agent on the contents of the 128 bytes of RAM that the game used. Although some learning took place, the results were less impressive than we saw when learning from pixels in earlier articles of this series.
Let’s see if we can achieve better results by approaching the input features in a slightly different way.
As noted in Appendix A of the Atari Learning Environment (ALE) paper, "Atari 2600 game programmers often used these bits not as individual values, but as part of 4-bit or 8-bit words. Linear function approximation on the individual bits can capture the value of these multi-bit words."
Learning From Individual Bits
Given that various numbers might be encoded in the RAM using different schemes (for example, one value in the first four bits, and a second value in the last four bits), we might try to learn from 1024 bits instead of treating them as 128 byte values.
Here is the code I used for learning from bits. It provides a custom observation wrapper, which uses NumPy’s unpackbits function to explode the incoming observation of 128 bytes into an observation of 1024 bytes (each of which is either 0 or 1). It also uses a large buffer and a small learning rate, following my less successful attempts with higher learning rates.
import numpy as np
import gym
import ray
from gym.spaces import Box
from gym import ObservationWrapper
from ray import tune
from ray.rllib.agents.dqn import DQNTrainer
from ray.tune.registry import register_env
class BytesToBits(ObservationWrapper):
def __init__(self, env):
super().__init__(env)
self.observation_space = Box(low=0, high=1, shape=(1024,), dtype=np.uint8)
def observation(self, obs):
return np.unpackbits(obs)
def env_creator(env_config):
env = gym.make('Breakout-ramDeterministic-v4')
env = BytesToBits(env)
return env
register_env("ram_bits_breakout", env_creator)
ENV = "ram_bits_breakout"
TARGET_REWARD = 200
TRAINER = DQNTrainer
ray.shutdown()
ray.init(include_webui=False, ignore_reinit_error=True)
tune.run(
TRAINER,
stop={"episode_reward_mean": TARGET_REWARD},
config={
env: ENV,
monitor: True,
evaluation_num_episodes: 25,
double_q: True,
hiddens: [1024],
num_workers: 0,
num_gpus: 1,
target_network_update_freq: 12_000,
lr: 5E-6,
adam_epsilon: 1E-5,
learning_starts: 150_000,
buffer_size: 1_500_000,
}
)
This wrapped environment still took a long time for the agent to learn, but it was much better than the attempt to learn directly from the bytes. This one took 12,779 iterations over 26.1 hours to reach the target score of 200.
Progress looked like this:
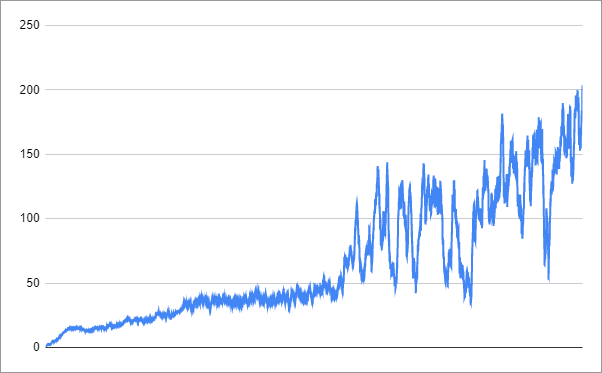
I suggest that you try different settings and, if you have some success, please share your findings in the comments.
For example, I tried training with a concatenation of bits and bytes. This didn’t work out too well, perhaps because it’s usually a good idea for all your features to be normalised to roughly the same scale. I stopped it after training for 18.3 hours, by which point it had reached a mean score of only 19.48 (compared to 86.17 after the same time for the bits-only version).
In the next, and final, article in this series, we will look at slightly more advanced topics: minimizing the "jitter" of our Breakout-playing agent, as well as performing grid searches for hyperparameters.

