C# implementation of a simple classification problem (recognizing digits from the MNIST dataset). Working through exercises like this one can provide detailed insight into how gradient descent is implemented using back propagation. These insights will prove valuable when designing solutions in specialized libraries such as TensorFlow.
Introduction
This basic image classification program is an example of digit recognition using the well-known MNIST data set. This is the "hello world" program for machine learning. The purpose is to provide an example which programmers can code and step through to gain hands-on insight into how back propagation really works. Frameworks such as TensorFlow enable the solution of more complex, processor-intensive problems by harnessing the power of the GPU, but can become a "leaky abstraction" when the novice is at a loss to figure out why his network isn't producing the expected results. It may be useful to demystify this subject and demonstrate that no special hardware, languages, or software libraries are needed to implement machine learning algorithms for simple problems.
Background
Here are links to some useful articles which provide a theoretical framework for neural networks:
Here is a schematic diagram of the neural net we intend to build:
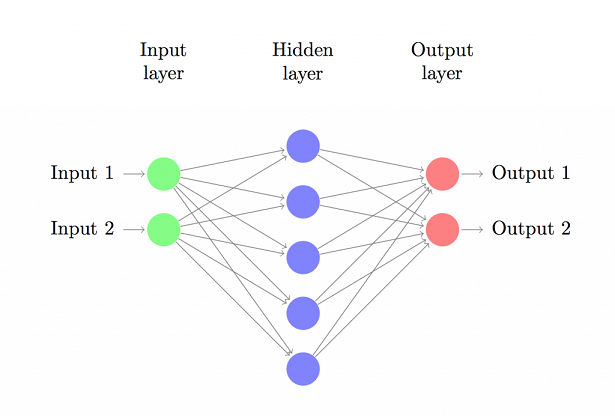
We are making a feed-forward neural net with one hidden layer. Our network will have 784 cells in the input layer, one for each pixel of a 28x28 black and white digit image. The number of cells in the hidden layer is variable. The output layer will contain 10 cells, one for each digit 0-9. This output layer is sometimes called a one-hot vector. The training goal is that for a successful inference, the cell corresponding to the correct digit will contain a value close to 1, while the rest of the cells contain a value close to zero.
Using the Program
You can build the solution in Visual Studio using the code in the accompanying zip file. The example is a Winforms desktop program.

The display shows an image of the MNIST training digits, overlaid with a representation of the hidden layer neurons. The weights of each neuronal connection to the input layer are represented as grayscale pixels. These connections correspond to the number of pixels in each handwritten digit image. They are initialized to random values, which is why they look like static. The row of grey squares at the bottom of each block represent the weight values of the connections between each hidden layer neuron and each of the 10 output cells.
You can verify that this random weighted network has no predictive value by running some tests. Click the test button and let it run for a few seconds, then click it again to stop. The results for each digit indicate the fraction of correct predictions. A value of 1.0 would mean all were correct, while a value of 0.0 would mean none were correct. This display shows that very few of the network's guesses were correct. If you ran a longer series of tests, the values would be more uniform and closer to 0.1 for each digit, which would approximate random chance (1 out of 10).
During the test procedure, the program displays each wrongly guessed digit image. The captions at the top of each image show the network's best guess, followed by a real number representing the degree of confidence the network had for this answer. The last digit shown here is a 5. The network thought it was a 2, with a confidence level of 0.2539 (this means 0.2539 was the largest value in the output layer array).
To train the network, click the Train button. The display will cycle through the digit images as each round of inference and back propagation takes place. The Digit counter represents a training round of digits 0-9 and the Epoch counter is incremented when all the digits in the training set have been completed. Progress will be quite slow due to the work of updating the graphical display (the first set of 10 digits will be especially slow because the program is building internal data structures). To make the training go much faster, unclick the Display and Weights check boxes, and minimize the program UI.
The accuracy is automatically monitored (a round of tests is run every 50 digits or so), and periodic results displayed at the bottom. Within a few seconds, accuracy will rise to 80 percent and higher before even the first epoch is completed, which takes around a minute. After a few epochs have gone by, the display may look something like this:
A few things are worth noting here. We have completed 7 epochs, or 7 trips through the training digits (each set contains over 5000 digits). We halted the training on digit set 439 of epoch 7 (which is the eighth epoch since they are numbered from 0). The estimated accuracy has improved to 0.9451, or about 94 percent. This is based on testing 50 digit sets of 0-9. If you increase the value in the Tests field and run a longer test, the accuracy may go up or down. The weight display is no longer static and has begun to show the characteristic mysterious swirls and smudges that represent the hidden layer's best idea of how to classify the digit images.
If you run a test against the test dataset again by clicking the Test button, the results now look much better. During this testing pass, the program got all the sixes correct, 96 percent of ones, threes, fours, sevens and nines, and 98 percent of eights. Fives had a very poor showing at only 86 percent.
Image Processing
The MNIST dataset is available online in various formats, but I chose to work with jpeg images of the training sets. The image files are included with the solution zip file. They reside in FeedForward/bin/Debug. The program reads these images and extracts the pixel information. Here is the snippet that copies the pixel values to a byte array. The bitmap data is locked and InteropServices are used to access unmanaged code. This is the most efficient and speedy way to get to each pixel value.
public static byte[] ByteArrayFromImage(Bitmap bmp)
{
Rectangle rect = new Rectangle(0, 0, bmp.Width, bmp.Height);
BitmapData data = bmp.LockBits(rect, ImageLockMode.ReadOnly, bmp.PixelFormat);
IntPtr ptr = data.Scan0;
int numBytes = data.Stride * bmp.Height;
byte[] image_bytes = new byte[numBytes];
System.Runtime.InteropServices.Marshal.Copy(ptr, image_bytes, 0, numBytes);
bmp.UnlockBits(data);
return image_bytes;
}
From there, the information is arranged into structures that make it possibly to randomly access each pixel in each image of the training and test data sets. Each original image shows thousands of digits arranged in a grid. Since the individual digits have consistent dimensions, it is possible to isolate each digit and store it in an instance of the DigitImage class. The digit pixels are stored as a list of byte arrays which represent the scan lines for each individual digit. This is done in the DigitImages class library.
namespace digitImages
{
public class DigitImage
{
public static int digitWidth = 28;
public static int nTypes = 10;
static Random random = new Random(DateTime.Now.Millisecond + DateTime.Now.Second);
public static DigitImage[] trainingImages = new DigitImage[10];
public static DigitImage[] testImages = new DigitImage[10];
public Bitmap image = null;
public byte[] imageBytes;
List<byte[]> pixelRows = null;
.
.
.
public static void loadPixelRows(int Expected, bool testing)
{
if (testing)
{
byte[] imageBytes = DigitImage.testImages[Expected].imageBytes;
Bitmap image = DigitImage.testImages[Expected].image;
if (DigitImage.testImages[Expected].pixelRows == null)
{
DigitImage.testImages[Expected].pixelRows = new List<byte[]>();
for (int i = 0; i < image.Height; i++)
{
int index = i * image.Width;
byte[] rowBytes = new byte[image.Width];
for (int w = 0; w < image.Width; w++)
{
rowBytes[w] = imageBytes[index + w];
}
DigitImage.testImages[Expected].pixelRows.Add(rowBytes);
}
}
}
else
{
byte[] imageBytes = DigitImage.trainingImages[Expected].imageBytes;
Bitmap image = DigitImage.trainingImages[Expected].image;
if (DigitImage.trainingImages[Expected].pixelRows == null)
{
DigitImage.trainingImages[Expected].pixelRows = new List<byte[]>();
for (int i = 0; i < image.Height; i++)
{
int index = i * image.Width;
byte[] rowBytes = new byte[image.Width];
for (int w = 0; w < image.Width; w++)
{
rowBytes[w] = imageBytes[index + w];
}
DigitImage.trainingImages[Expected].pixelRows.Add(rowBytes);
}
}
}
}
The Main Form
The main form uses a non-flicker panel to draw the weight display.
public class MyPanel : System.Windows.Forms.Panel
{
public MyPanel()
{
this.SetStyle(
System.Windows.Forms.ControlStyles.UserPaint |
System.Windows.Forms.ControlStyles.AllPaintingInWmPaint |
System.Windows.Forms.ControlStyles.OptimizedDoubleBuffer,
true);
}
}
Here is how the program draws the grayscale depiction of the 784 input to hidden layer weights, and the 10 hidden layer to output layer weights:
private void rangeOfHiddenWeights(out double MIN, out double MAX)
{
List<double> all = new List<double>();
for (int N = 0; N < NeuralNetFeedForward.hiddenLayer.nNeurons; N++)
{
foreach (double d in NeuralNetFeedForward.hiddenLayer.neurons[N].weights)
{
all.Add(d);
}
}
all.Sort();
MIN = all[0];
MAX = all[all.Count - 1];
}
private void drawWeights(Graphics ee, HiddenLayer hidLayer)
{
int weightPixelWidth = 4;
int W = (digitImages.DigitImage.digitWidth * (weightPixelWidth + 1));
int H = (digitImages.DigitImage.digitWidth * (weightPixelWidth));
int wid = H / 10;
int yOffset = 0;
int xOffset = 0;
bool drawRanges = false;
double mind = 0;
double maxd = 0;
rangeOfHiddenWeights(out mind, out maxd);
double range = maxd - mind;
Bitmap bmp = new Bitmap(W, H + wid);
Graphics e = Graphics.FromImage(bmp);
for (int N = 0; N < hidLayer.nNeurons; N++)
{
double[] weights = hidLayer.neurons[N].weights;
double maxout = double.MinValue;
double minout = double.MaxValue;
for (int output = 0;
output < NeuralNetFeedForward.outputLayer.nNeurons; output++)
{
if (N < NeuralNetFeedForward.outputLayer.neurons[output].weights.Length)
{
double Weight =
NeuralNetFeedForward.outputLayer.neurons[output].weights[N];
if (Weight > maxout)
{
maxout = Weight;
}
if (Weight < minout)
{
minout = Weight;
}
double Mind =
NeuralNetFeedForward.outputLayer.neurons[output].weights.Min();
double Maxd =
NeuralNetFeedForward.outputLayer.neurons[output].weights.Max();
double Range = Maxd - Mind;
double R = ((Weight - Mind) * 255.0) / Range;
int r = Math.Min(255, Math.Max(0, (int)R));
Color color = Color.FromArgb(r, r, r);
int X = (wid * output);
int Y = H;
e.FillRectangle(new SolidBrush(color), X, Y, wid, wid);
}
else
{
maxout = 0;
minout = 0;
}
}
for (int column = 0; column < digitImages.DigitImage.digitWidth; column++)
{
for (int row = 0; row < digitImages.DigitImage.digitWidth; row++)
{
double weight = weights[(digitImages.DigitImage.digitWidth * row) +
column];
double R = ((weight - mind) * 255.0) / range;
int r = Math.Min(255, Math.Max(0, (int)R));
int x = column * weightPixelWidth;
int y = row * weightPixelWidth;
int r2 = r;
if (hidLayer.neurons[N].isDropped)
{
r2 = Math.Min(255, r + 50);
}
Color color = Color.FromArgb(r, r2, r);
e.FillRectangle(new SolidBrush(color), x, y,
weightPixelWidth, weightPixelWidth);
}
}
xOffset += W;
if (xOffset + W >= this.ClientRectangle.Width)
{
xOffset = 0;
yOffset += W;
}
ee.DrawImage(bmp, new Point(xOffset, yOffset));
}
}
Input Layer
The input layer is very simple (some experimental code about implementing dropouts has been omitted for clarity). It has one function, which sets the input layer to the representation of the digit to be classified. The thing to note here is that the 0-255 byte information from the grayscale image is squashed into a real number between 0 and 1.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace NeuralNetFeedForward
{
class InputLayer
{
public double[] inputs;
public void setInputs(byte[] newInputs)
{
inputs = new double[newInputs.Length];
for (int i = 0; i < newInputs.Length; i++)
{
inputs[i] = (double)newInputs[i] / 255.0;
}
}
}
}
Hidden Layer
The hidden layer is similarly very simple. It has two functions, activate (inference) and backPropagate (learning).
class HiddenLayer
{
public int nNeurons = 30;
public HiddenNeuron[] neurons;
public NeuralNetFeedForward network;
public HiddenLayer(int N, NeuralNetFeedForward NETWORK)
{
network = NETWORK;
nNeurons = N;
neurons = new HiddenNeuron[nNeurons];
for (int i = 0; i < neurons.Length; i++)
{
neurons[i] = new HiddenNeuron(i, this);
}
}
public void backPropagate()
{
foreach (HiddenNeuron n in neurons)
{
n.backPropagate();
}
}
public void activate()
{
foreach (HiddenNeuron n in neurons)
{
n.activate();
}
}
}
}
Class for the hidden layer neuron. Some experimental code about dropouts has been omitted for clarity. There are only three functions: activate, backPropagate, and initWeights, which initializes the weights to random values. Note that on the backward pass, the error for each output must be calculated according to this neuron's contribution to that error. Since the output layer weights change on the backward pass, the previous forward pass weights must be saved and used to calculate the error. Another wrinkle here is that the program allows the use of four different activation functions. More on this later.
class HiddenNeuron
{
public int index = 0;
public double ERROR = 0;
public double[] weights =
new double[digitImages.DigitImage.digitWidth * digitImages.DigitImage.digitWidth];
public double[] oldWeights =
new double[digitImages.DigitImage.digitWidth * digitImages.DigitImage.digitWidth];
public double sum = 0.0;
public double sigmoidOfSum = 0.0;
public HiddenLayer layer;
public HiddenNeuron(int INDEX, HiddenLayer LAYER)
{
layer = LAYER;
index = INDEX;
initWeights();
}
public void initWeights()
{
weights = new double[digitImages.DigitImage.digitWidth *
digitImages.DigitImage.digitWidth];
for (int y = 0; y < weights.Length; y++)
{
weights[y] = NeuralNetFeedForward.randomWeight();
}
}
public void activate()
{
sum = 0.0;
for (int y = 0; y < weights.Length; y++)
{
sum += NeuralNetFeedForward.inputLayer.inputs[y] * weights[y];
}
sigmoidOfSum = squashFunctions.Utils.squash(sum);
}
public void backPropagate()
{
double sumError = 0.0;
foreach (OutputNeuron o in NeuralNetFeedForward.outputLayer.neurons)
{
sumError += (
o.ERROR
* o.oldWeights[index]);
}
ERROR = squashFunctions.Utils.derivative(sigmoidOfSum) * sumError;
for (int w = 0; w < weights.Length; w++)
{
weights[w] += (ERROR * NeuralNetFeedForward.inputLayer.inputs[w]) *
layer.network.learningRate;
}
}
}
Output Layer
The very simple code for the output layer and neuron. Note that the number of output layer neurons is always 10. This corresponds to the number of possible answers 0-9 when classifying a digit. As previously mentioned, during back propagation, it is necessary to preserve a copy of the previous (old) weights before adjusting the weights, so they can be used in the error calculation for the middle (hidden) layer. As in the hidden layer, weights are initialized to random values.
class OutputLayer
{
public NeuralNetFeedForward network;
public HiddenLayer hiddenLayer;
public int nNeurons = 10;
public OutputNeuron[] neurons;
public OutputLayer(HiddenLayer h, NeuralNetFeedForward NETWORK)
{
network = NETWORK;
hiddenLayer = h;
neurons = new OutputNeuron[nNeurons];
for (int i = 0; i < nNeurons; i++)
{
neurons[i] = new OutputNeuron(this);
}
}
public void activate()
{
foreach (OutputNeuron n in neurons)
{
n.activate();
}
}
public void backPropagate()
{
foreach (OutputNeuron n in neurons)
{
n.backPropagate();
}
}
}
class OutputNeuron
{
public OutputLayer outputLayer;
public double sum = 0.0;
public double sigmoidOfSum = 0.0;
public double ERROR = 0.0;
public double [] weights;
public double[] oldWeights;
public double expectedValue = 0.0;
public OutputNeuron(OutputLayer oL)
{
outputLayer = oL;
weights = new double[outputLayer.hiddenLayer.nNeurons];
oldWeights = new double[outputLayer.hiddenLayer.nNeurons];
initWeights();
}
public void activate()
{
sum = 0.0;
for (int y = 0; y < weights.Length; y++)
{
sum += outputLayer.hiddenLayer.neurons[y].sigmoidOfSum * weights[y];
}
sigmoidOfSum = squashFunctions.Utils.squash(sum);
}
public void calculateError()
{
ERROR = squashFunctions.Utils.derivative(sigmoidOfSum) *
(expectedValue - sigmoidOfSum);
}
public void backPropagate()
{
calculateError();
int i = 0;
foreach (HiddenNeuron n in outputLayer.hiddenLayer.neurons)
{
oldWeights[i] = weights[i];
weights[i] += (ERROR * n.sigmoidOfSum) * outputLayer.network.learningRate;
i++;
}
}
public void initWeights()
{
for (int y = 0; y < weights.Length; y++)
{
weights[y] = NeuralNetFeedForward.randomWeight();
}
}
}
The Network
Class that implements the network. Some code about saving weights to files, dynamically reducing the learning rate and other non-essential functions has been omitted for clarity. Important functions are train(), testInference(), setExpected(), and answer(). Note that setExpected() works by setting the value of the output neuron corresponding to the desired answer to 1, and all the other output neurons to 0. This method of encoding information is sometimes called a "one-hot vector". Similarly, answer() works by finding the output neuron with the highest value. Ideally, this value would be close to 1 and all the others would be close to 0. This is the training goal against which errors are calculated and back-propagated through the network. The train() function simply calls setExpected() to establish a goal, then calls activate() and backPropagate() to attempt an inference and adjust the layer weights based on the error that was calculated. The activate() and backPropagate() functions simply call the corresponding functions for the middle layer and output layer.
class NeuralNetFeedForward
{
public enum ActivationType { SIGMOID, TANH, RELU, LEAKYRELU };
public ActivationType activationType = ActivationType.LEAKYRELU;
public double learningRate = 0.01;
public List<inferenceError> errors = new List<inferenceError>();
public static int expected;
public static Random rand = new Random(DateTime.Now.Millisecond);
public static InputLayer inputLayer;
public static HiddenLayer hiddenLayer;
public static OutputLayer outputLayer;
public int nFirstHiddenLayerNeurons = 30;
public void setExpected(int EXPECTED)
{
expected = EXPECTED;
for (int i = 0; i < NeuralNetFeedForward.outputLayer.neurons.Length; i++)
{
if (i == EXPECTED)
{
NeuralNetFeedForward.outputLayer.neurons[i].expectedValue = 1.0;
}
else
{
NeuralNetFeedForward.outputLayer.neurons[i].expectedValue = 0.0;
}
}
}
public void create()
{
inputLayer = new InputLayer();
hiddenLayer = new HiddenLayer(nFirstHiddenLayerNeurons, this);
outputLayer = new OutputLayer(hiddenLayer, this);
}
public NeuralNetFeedForward(int NNeurons)
{
nFirstHiddenLayerNeurons = NNeurons;
create();
}
public NeuralNetFeedForward()
{
create();
}
public static double dotProduct(double[] a, double[] b)
{
double result = 0.0;
for (int i = 0; i < a.Length; i++)
{
result += a[i] * b[i];
}
return result;
}
public static double randomWeight()
{
double span = 50000;
int spanInt = (int)span;
double magnitude = 10.0;
return ((double)(NeuralNetFeedForward.rand.Next(0, spanInt * 2) - spanInt)) /
(span * magnitude);
}
public bool testInference(int EXPECTED, out int guessed, out double confidence)
{
setExpected(EXPECTED);
activate();
guessed = answer(out confidence);
return (guessed == EXPECTED);
}
public void train(int nIterations, int EXPECTED)
{
setExpected(EXPECTED);
for (int n = 0; n < nIterations; n++)
{
activate();
backPropagate();
}
}
public void activate()
{
hiddenLayer.activate();
outputLayer.activate();
}
public void backPropagate()
{
outputLayer.backPropagate();
hiddenLayer.backPropagate();
}
public int answer(out double confidence)
{
confidence = 0.0;
double max = 0;
int result = -1;
for (int n = 0; n < NeuralNetFeedForward.outputLayer.nNeurons; n++)
{
double s = NeuralNetFeedForward.outputLayer.neurons[n].sigmoidOfSum;
if (s > max)
{
confidence = s;
result = n;
max = s;
}
}
return result;
}
}
Utilities
You can run this program with a choice of four activation functions: sigmoid, hyperbolic tangent, rectified linear, and "leaky" rectified linear. The Utils class in the squashFunctions class library contains the implementations of these four activation functions, along with their corresponding derivatives which are used in back propagation.
public class Utils
{
public enum ActivationType { SIGMOID, TANH, RELU, LEAKYRELU };
public static ActivationType activationType = ActivationType.LEAKYRELU;
public static double squash(double x)
{
if (activationType == ActivationType.TANH)
{
return hyTan(x);
}
else if (activationType == ActivationType.RELU)
{
return Math.Max(x, 0);
}
else if (activationType == ActivationType.LEAKYRELU)
{
if (x >= 0)
{
return x;
}
else
{
return x * 0.15;
}
}
else
{
return sigmoid(x);
}
}
public static double derivative(double x)
{
if (activationType == ActivationType.TANH)
{
return derivativeOfTanHofX(x);
}
else if (activationType == ActivationType.RELU)
{
return x > 0 ? 1 : 0;
}
else if (activationType == ActivationType.LEAKYRELU)
{
return x >= 0 ? 1 : 0.15;
}
else
{
return derivativeOfSigmoidOfX(x);
}
}
public static double sigmoid(double x)
{
double s = 1.0 / (1.0 + Math.Exp(-x));
return s;
}
public static double derivativeOfSigmoid(double x)
{
double s = sigmoid(x);
double sPrime = s * (1.0 - s);
return sPrime;
}
public static double derivativeOfSigmoidOfX(double sigMoidOfX)
{
double sPrime = sigMoidOfX * (1.0 - sigMoidOfX);
return sPrime;
}
public static double hyTan(double x)
{
double result = Math.Tanh(x);
return result;
}
public static double derivativeOfTanH(double x)
{
double h = hyTan(x);
return derivativeOfTanHofX(h);
}
public static double derivativeOfTanHofX(double tanHofX)
{
return 1.0 - (tanHofX * tanHofX);
}
public static double dotProduct(double[] a, double[] b)
{
double result = 0.0;
for (int i = 0; i < a.Length; i++)
{
result += a[i] * b[i];
}
return result;
}
}
Room for Improvement
With only a few minutes of training, this network can achieve roughly 95% accuracy. This is sufficient to prove the concept, but it's not really a very good practical result. There are a few possible ways in which the accuracy might be improved.
First, you can experiment with varying the number of hidden neurons. The included code uses 20 neurons by default, but this number can be increased or reduced (a minimum of 10 hidden layer neurons is hard-coded in, but you can change this if you like). Also, you can experiment with trying different activation functions by choosing one from the dropdown on the UI. Some activation functions such as RELU usually tend to converge faster but may be subject to exploding gradients, while others may be subject to vanishing gradients.
Each network you train will come out with different weights, because the weights are initialized with random values. Training of neural nets using gradient descent is subject to the problem of settling into "local minima" and thereby missing a better possible solution. If you come up with a good training result, you can use the commands on the File menu to save that weight configuration and read it back in later.
By twiddling the code, better results may be achieved. One possible improvement is random dropouts. In this method, some of the neurons in the middle layer are randomly omitted. I have included some code for implementing random dropouts, but the code is experimental and not fully tested. This option is not available from the UI, but by fooling around with the code, you can investigate further.
Another code wrinkle that's not fully tested is dynamically reducing the learning rate. I have included some hooks in the code to reduce the learning rate after a certain number of trials have been reached. It's rather crudely implemented, and the feature is turned off right now. It should be possible to trigger reductions in the learning rate based upon the current level of accuracy, rather than by the number of digits trained.
It should also be noted that it's possible to overtrain a network. Longer training times are not always better. You can halt training early through the user interface, but it should be possible by altering the code to trigger early halts based upon the current estimated accuracy learned by periodic testing.
Finally, a peculiarity of the MNIST data is that the training data set digits were drawn by postal employees, and the test data set digits were drawn by school children, so there is a notable difference in quality between the test and training data. Better results might be achieved by pooling the two data sets and then arbitrarily dividing them into training data and test data. One way to do this would be to use the even-numbered digit examples as training data and the odd-number digit examples as test data. This insures that you have distinct training data and test data, while reducing accidental differences between the quality of the two sets. I have implemented something like this with the "interleave" feature, which is not fully tested. This is not available in the UI, but if you look through the code, you can enable it.
History
- 26th June, 2020: Initial version
- 15th September, 2020: Update

