This article demonstrates the customization of the task scheduling algorithm .NET uses to run Task items. Here, we use it to put a hard limit on the number of parallel jobs being performed, rather than leaving that to the default scheduler, which is very aggressive.
Introduction
The Task framework in .NET and the TAP programming pattern are very powerful tools to add concurrent execution to your application. Often easier to use than threads, they give you at least as much power, if you know how to use them. Some of the best features however, aren't very well documented. Once such feature is the TaskScheduler, which controls when your tasks get executed.
I got into this mess revisting this project but using the Task framework and the built in thread pool. To my horror, .NET allocates (on my system) 2047 potential threads for CPU bound** operations. I'm not sure they're actually created, or if there's just cutouts, but still, an ideally designed application will have exactly as many CPU bound operations going as there are cores (or usually, cores minus one since the primary one is usually concerned with managing everything else, and probably a UI). The bottom line is, if you have operations that tie up your CPU, you don't gain any performance by running more of them than you have cores to execute them. Given that, the .NET value I get back for available threads per process seems obscene. In fact, the more threads you have, the harder the scheduler has to work, meaning you're losing performance with more threads than you can even run concurrently on your CPU. The moral of this is create as few threads as you need, but no fewer.
I'd rather prefer to queue operations once I won't get additional performance out of running more of them. The built in ThreadPool doesn't really care about that, and setting SetMaxThreads() to try to change that impacts the whole process, among other problems. Using the technique I outlined in the previous article works, but it's a bit complicated, and even if it was abstracted, using the Task framework is the way to go these days in .NET. Therefore, I needed something to allow me to use Tasks, but in such a way that I could control how many ran at once. Eventually, I stumbled on TaskScheduler, and even a bit of example code for subclassing it to change the behavior, but otherwise it's not very well documented. Here, I present this technique to you.
** A CPU bound operation is one that ties up your processor, making it crunch on something. Contrast this with an I/O bound operation that spends most of its time waiting on external device interactions like a hard drive's disk reads or a network controller's incoming packets. The distinction is important, because there's good reason to have more I/O bound operations than cores, depending on how many devices you are talking to. An I/O bound operation does not tie up CPU cycles (aside from a miniscule bit of overhead to make it work).
Conceptualizing this Mess
The ThreadPool as I said, allocates a tremendous amount of threads (or at least stand ins for them) up front and basically takes queuing long operations off the table, because you'll usually have a thread available, even if you don't have an idle core to run it on - or at least this is default behavior. This setup on my system gives me roughly 1023 threads per core, per process in the pool. That's ridiculous. Even if my app had that many long running CPU bound tasks for some reason I can't fathom, there's no way I'd want to try to execute them all at once! No, what I'd like to do is allocate a certain number of workers, and then dedicate those workers to fulfilling the tasks as the workers become available, so that tasks are waiting in line to be completed, even as more than one are being completed at once. One of the main reasons for doing this is performance, but also it can be simply a manageability issue. The more of these tasks you are juggling at once, the more unwieldy and resource hungry your app can become. This isn't what we want.
Luckily, the Task framework gives you a way to customize scheduling if you're willing to use TaskFactory.StartNew() instead of Task.Run(). To facilitate this, we have to pass a custom TaskScheduler as an argument to the TaskFactory's constructor. First however, we need a task scheduler implementation to pass it. Microsoft gives us two, and neither does what we want. The example code I linked to however, comes close. With a bit of hammering on it, I was able to recreate a pretty faithful reproduction of the behavior of my previous application, but using this entirely different paradigm.
Basically, it has facilities for queuing and dequeuing tasks, as well as executing them normally or on the current thread. It also includes a member use by debuggers to enumerate the tasks. We'll be implementing most of this here.
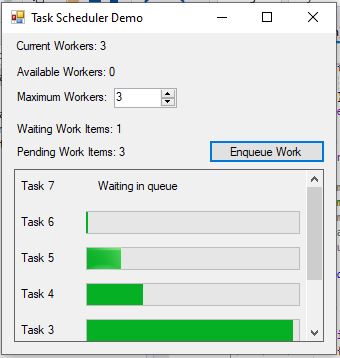
Once we do, the rest of the app is straightforward. It just spawns a new task whenever a button is clicked, linking the task to a progress control it adds to the display. The scheduler handles when it runs. We use an anonymous delegate for linking the control which is much simpler than my original application, although this is a special use case, and that application's infrastructure supports far more than scheduling whereas this is a one trick pony. Still, it's a useful pony with a neat trick.
Coding this Mess
The User Interface
First let's look at the user interface. The meat of it is in the "Enqueue Work" button's click handler:
var wpc = new WorkerProgressControl(_nextTaskId++);
ProgressPanel.SuspendLayout();
ProgressPanel.Controls.Add(wpc);
wpc.Dock = DockStyle.Top;
ProgressPanel.ResumeLayout(true);
new TaskFactory(_taskSched).StartNew(()=> {
for(var i = 0;i<50;++i)
{
Thread.Sleep(100);
BeginInvoke(new Action(()=> {
wpc.Value = i * 2;
}));
}
wpc.Value = 100;
});
_taskSched is our custom task scheduler instance. Note how we're passing it to TaskFactory's constructor on the bolded line. This allows us to swap out the standard scheduling behavior with ours that constrains the number of concurrent tasks. In the delegate, there's the "work" that our long running task performs. Note how we're updating the UI periodically within it, using BeginInvoke(). This is to report our progress in a thread safe manner. This is a bit different than how the last article's app worked, but it's easier this time than it was in the previous article.
Our WorkerProgressControl is basically just a progress bar and a label like in the last article. We dock them as we add more tasks to create a list. Unlike the last app, we can let the C# compiler manage our lookup for our control by using its anonymous method hoisting feature. Basically, we just reference wpc from inside the anonymous method and it works like magic - like it always does.
The nice thing here is, there's no work here done to schedule the task. All of that is handled by _taskSched. Our UI code doesn't have to care, which keeps it dead simple. A user interface should be glue, and not much more. Let's keep the scheduling logic where it belongs!
The Task Scheduler
Speaking of our custom TaskScheduler, let's visit it now. We use it to track the current tasks, get the next task, execute tasks, and gather various statistics on tasks. Much of this is a shameless lift of Microsoft's example code I linked to in the introduction, but I've modified it to gather more statistics and to allow you to change the amount of concurrency allowed for during the lifetime of the object, not just on creation. Let's dive in, starting with our member fields:
[ThreadStatic]
static bool _currentThreadIsProcessingItems;
readonly LinkedList<Task> _tasks = new LinkedList<Task>();
int _maximumTaskCount = Math.Max(1,Environment.ProcessorCount-1);
int _pendingTaskCount = 0;
int _waitingTaskCount = 0;
First, we have a flag that indicates whether the current thread is processing work items. This is set on a thread by thread basis and checked when we try to "inline" a task to run on the same thread. Otherwise, it's not much use to us.
Second, we have a linked list that stores our tasks. We lock all access to it, using lock. I thought this was terrible at first, and I was ready to replace the whole thing with a slimmer synchronization facility, but when I did some reading, I found out that in this case, due to thread access patterns, the lock performs as good or better than most of the other options in this scenario, and better than anything non-trivial. At one point, I probably would have vowed to only use it at gunpoint but in the end, here we are. The linked list is appropriate because tasks are added as often as they are removed, and removal happens at the first node.
Now, we have our maximum task count, which it tries to set to the ideal number based on the hardware of your machine. Basically it wants to use all your cores minus one, with a minimum of one.
Finally, we have our _pendingTaskCount and _waitingTaskCount which track the number of items running** and the number of items waiting.
** Sort of. We actually get this decremented some time before the task is finished running. There's a way to track the end of the task and get it on the nose, but it's far less efficient. Consider this value to be an estimate.
Now let's put these fields to work. The first non-trivial member we encounter is QueueTask(), which is implemented thus:
lock (_tasks)
{
_tasks.AddLast(task);
++_waitingTaskCount;
if (_pendingTaskCount < _maximumTaskCount)
{
++_pendingTaskCount;
_NotifyThreadPoolOfPendingWork();
}
}
All it's doing is taking a lock on the list, adding a task and updating our statistics. If it's less than the number of tasks we allow for, we increase the pending tasks and notify the thread pool, which brings us to _NotifyThreadPoolOfPendingWork():
ThreadPool.UnsafeQueueUserWorkItem((object state) =>
{
_currentThreadIsProcessingItems = true;
try
{
while (true)
{
Task item;
lock (_tasks)
{
if (0 == _tasks.Count)
{
--_pendingTaskCount;
break;
}
item = _tasks.First.Value;
_tasks.RemoveFirst();
--_waitingTaskCount;
}
base.TryExecuteTask(item);
}
}
finally { _currentThreadIsProcessingItems = false; }
}, null);
This is a bit more substantial. First, we call UnsafeQueueUserWorkItem(). You might be wondering why we're not calling QueueUserWorkItem() and I wondered that too, but then I found this. We aren't calling ExecutionContext.Capture() which is an expensive call. The downside is this matters when your code runs in a restricted environment because it can elevate privileges. Performance is the only reason I could find for discovering this call in the example code from Microsoft. Looking at the rest of this code of theirs, it was implemented better than I expected for an example, so I'm sticking with this call. Presumably the performance payoff is worth it though with long running tasks I wouldn't think so, or perhaps more importantly, there might be gotchas I'm unaware of with the more traditional method in this scenario. I can't be sure so ironically, I'm playing it safe by sticking to UnsafeQueueUserWorkItem()!
Inside the anonymous method, we have to do our work, so we set the per-thread flag indicating we're busy processing, and then we loop through the tasks. Note we're locking inside the loop. We do that so we can keep the base.TryExecuteTask(item) outside of the lock, and this is important for performance and to prevent potential deadlocks. Inside the lock, we update our statistics, get the time, and remove it from the task list. Finally, we exit the lock. Once we're done, we set our per-thread flag back to idle.
We didn't have to use the system thread pool here. You can schedule your tasks to execute on raw threads or even the same thread if you want it to always block. It all depends on how you implement TaskScheduler.
Next, we have TryExecuteInline() which attempts to execute the task on the current thread:
if (!_currentThreadIsProcessingItems) return false;
if (taskWasPreviouslyQueued)
if (TryDequeue(task))
return base.TryExecuteTask(task);
else
return false;
else
return base.TryExecuteTask(task);
First, what we're doing here is checking if we're currently processing, because for this to work, we have to be, or we'll never get an opportunity from this thread in the first place. If we are, then we see if the task was already in the queue. If so, we remove and run it immediately, otherwise if it's not in the queue we return false. Finally, if it wasn't previously queued, we simply run the task. The removal is so we don't run the task twice.
TryDequeue() simply tries to remove an item:
lock (_tasks)
{
if (_tasks.Remove(task))
{
--_waitingTaskCount;
return true;
}
return false;
}
The only other thing we're doing aside from locking the list and removal is updating the waiting statistic.
Finally, we have GetScheduledTasks():
bool lockTaken = false;
try
{
Monitor.TryEnter(_tasks, ref lockTaken);
if (lockTaken) return _tasks;
else throw new NotSupportedException();
}
finally
{
if (lockTaken) Monitor.Exit(_tasks);
}
The thing about this method is that it's intended for debuggers, and we can't block on the debugger thread so we simply try to enter the lock, and if we can't, then we throw. Oddly enough, the debugger can handle an exception better than a blocking call, and the documentation for the method says as much, in so many words.
And that's it. There's really not a lot to it. It's just a matter of knowing what to look for.
History
- 18th July, 2020 - Initial submission

